Flink is a powerful open-source stream processing framework designed for real-time data analytics and event-driven applications. It enables you to process large-scale data streams efficiently with low latency and high fault tolerance. Discover how Flink can transform your data processing needs by exploring the rest of this article.
Table of Comparison
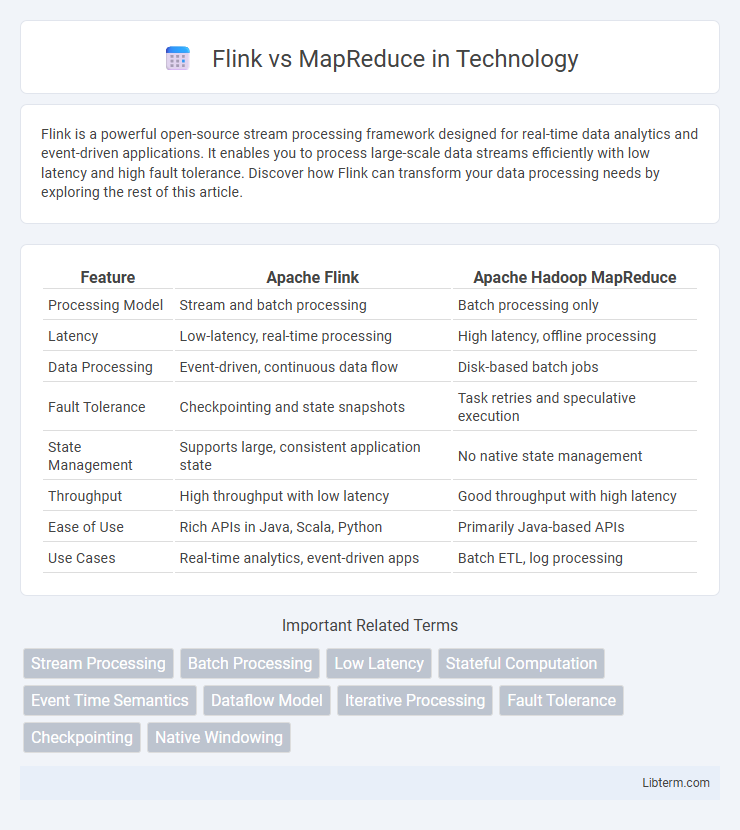
| Feature | Apache Flink | Apache Hadoop MapReduce |
|---|---|---|
| Processing Model | Stream and batch processing | Batch processing only |
| Latency | Low-latency, real-time processing | High latency, offline processing |
| Data Processing | Event-driven, continuous data flow | Disk-based batch jobs |
| Fault Tolerance | Checkpointing and state snapshots | Task retries and speculative execution |
| State Management | Supports large, consistent application state | No native state management |
| Throughput | High throughput with low latency | Good throughput with high latency |
| Ease of Use | Rich APIs in Java, Scala, Python | Primarily Java-based APIs |
| Use Cases | Real-time analytics, event-driven apps | Batch ETL, log processing |
Introduction to Flink and MapReduce
Apache Flink is a powerful open-source stream processing framework designed for real-time data analytics, capable of handling high-throughput, low-latency data streams with advanced event-driven applications. Hadoop MapReduce, a batch processing model within the Apache Hadoop ecosystem, processes large-scale datasets by dividing tasks into map and reduce operations for reliable offline data analysis. Flink's in-memory processing and native support for iterative algorithms provide significant performance advantages over MapReduce's disk-based, sequential batch processing approach.
Core Concepts and Architecture
Apache Flink utilizes a stream processing architecture with a distributed dataflow model that enables low-latency, stateful computations on unbounded data streams, employing event-time processing and exactly-once semantics. In contrast, MapReduce relies on a batch processing paradigm with a two-phase execution model--map and reduce stages--processing data in discrete, immutable chunks stored in Hadoop Distributed File System (HDFS). Flink's architecture includes a JobManager for scheduling and TaskManagers for executing tasks, emphasizing real-time processing and fault tolerance through distributed snapshots, whereas MapReduce's architecture centers on JobTracker and TaskTracker components designed for fault tolerance and scalability within batch jobs.
Data Processing Models
Apache Flink uses a stream processing model that allows real-time, continuous data ingestion and computation, enabling low latency and stateful processing. MapReduce operates on a batch processing model, dividing data into discrete chunks processed in parallel, which introduces higher latency but excels in throughput for large datasets. Flink's architecture supports event-driven applications and iterative algorithms more efficiently compared to the rigid batch-oriented paradigm of MapReduce.
Ease of Use and Programming APIs
Apache Flink offers a more user-friendly experience with its high-level, expressive APIs in Java, Scala, and Python, enabling real-time stream processing and batch processing with a unified programming model. In contrast, MapReduce involves a more complex, low-level Java API that requires extensive boilerplate code and is primarily designed for batch processing, making it less intuitive for developers. Flink's built-in support for iterative algorithms and event-time semantics simplifies complex data workflows, providing greater ease of use compared to the rigid, slower execution model of MapReduce.
Performance and Speed Comparison
Apache Flink outperforms MapReduce in processing speed due to its native stream processing engine, enabling real-time analytics with low latency, whereas MapReduce relies on batch processing with higher latency. Flink's in-memory computation and pipelined architecture significantly reduce job execution times compared to MapReduce's disk-based, two-stage Map and Reduce tasks. Benchmark tests show Flink achieving up to 100x faster processing on complex data workflows, making it ideal for applications requiring rapid data insights.
Fault Tolerance and Reliability
Flink ensures fault tolerance and reliability through its lightweight checkpointing mechanism and distributed snapshot algorithm, enabling state recovery with minimal overhead and low latency. MapReduce achieves fault tolerance by re-executing failed tasks using data replication and intermediate data storage on HDFS, which can lead to higher latency and resource consumption during recovery. Flink's exactly-once state consistency guarantees make it more reliable for real-time stream processing compared to MapReduce's batch-oriented fault tolerance model.
Scalability and Resource Management
Apache Flink excels in scalability by supporting high-throughput, low-latency stream processing across distributed clusters, dynamically adjusting resource allocation with fine-grained operator parallelism. In contrast, MapReduce handles batch processing with static resource allocation, which can lead to underutilization and scalability limitations in real-time use cases. Flink's efficient memory management and adaptive checkpointing enhance fault tolerance and resource optimization, outperforming MapReduce in complex, large-scale data processing environments.
Use Cases and Application Scenarios
Apache Flink excels in real-time stream processing use cases such as fraud detection, event monitoring, and IoT analytics due to its low-latency and stateful computation capabilities. MapReduce is better suited for batch processing workloads like large-scale data transformation, log analysis, and indexing in distributed storage systems where fault tolerance and scalability are critical. Use scenarios demanding iterative algorithms and continuous data ingestion favor Flink, while static, one-time data processing tasks commonly rely on MapReduce frameworks.
Integration with Big Data Ecosystem
Apache Flink offers seamless integration with the big data ecosystem, supporting connectors for Apache Kafka, HDFS, Apache Cassandra, and Apache Hadoop YARN for resource management, enabling real-time stream processing and batch jobs within unified architecture. In contrast, MapReduce primarily integrates with Hadoop Distributed File System (HDFS) and YARN, focusing on batch processing with limited support for real-time analytics. Flink's ability to work with various data sources and sinks, including NoSQL databases and message queues, provides greater flexibility and efficiency in complex big data workflows.
Choosing Between Flink and MapReduce
Choosing between Apache Flink and MapReduce depends on the specific data processing requirements and system capabilities. Flink offers real-time stream processing with low latency and supports stateful computations, making it ideal for complex event-driven applications. MapReduce provides reliable batch processing with high fault tolerance, suitable for large-scale, offline data analysis where processing time is not critical.
Flink Infographic