Document stores are a type of NoSQL database designed to efficiently manage, store, and retrieve document-oriented information such as JSON, XML, or BSON formats. These databases excel at handling semi-structured data, offering flexible schema designs and powerful querying capabilities tailored for complex documents. Dive into the rest of this article to explore how a document store can optimize Your data management strategy.
Table of Comparison
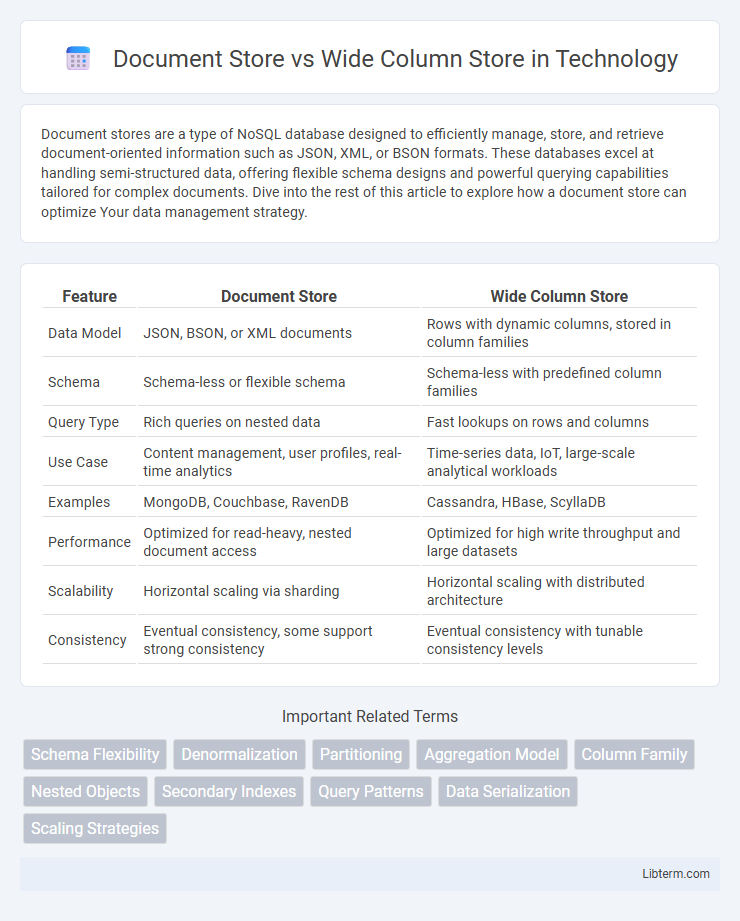
| Feature | Document Store | Wide Column Store |
|---|---|---|
| Data Model | JSON, BSON, or XML documents | Rows with dynamic columns, stored in column families |
| Schema | Schema-less or flexible schema | Schema-less with predefined column families |
| Query Type | Rich queries on nested data | Fast lookups on rows and columns |
| Use Case | Content management, user profiles, real-time analytics | Time-series data, IoT, large-scale analytical workloads |
| Examples | MongoDB, Couchbase, RavenDB | Cassandra, HBase, ScyllaDB |
| Performance | Optimized for read-heavy, nested document access | Optimized for high write throughput and large datasets |
| Scalability | Horizontal scaling via sharding | Horizontal scaling with distributed architecture |
| Consistency | Eventual consistency, some support strong consistency | Eventual consistency with tunable consistency levels |
Introduction to Modern Database Architectures
Document stores organize data using JSON-like documents, enabling flexible schemas and nested data structures ideal for applications requiring dynamic and hierarchical data. Wide column stores model data as tables with rows and dynamic columns, optimizing for large-scale, high-throughput workloads with efficient storage of sparse data. Both architectures support horizontal scalability and distributed computing, making them essential in modern database ecosystems tailored to specific use cases like content management and real-time analytics.
What is a Document Store?
A Document Store is a type of NoSQL database designed to store, retrieve, and manage document-oriented information, typically in formats like JSON, BSON, or XML. It organizes data as collections of documents, each containing key-value pairs that can represent complex nested structures, allowing flexible and dynamic schemas. This model excels in applications requiring fast retrieval of hierarchical data and supports indexing on document attributes for efficient querying.
What is a Wide Column Store?
A Wide Column Store is a type of NoSQL database designed to store and manage large volumes of structured data across distributed systems using tables, rows, and dynamic columns that can vary by row. It excels in handling sparse data efficiently by allowing flexible schema design where each row can have a different set of columns, making it ideal for time-series data, real-time analytics, and IoT applications. Prominent examples of Wide Column Stores include Apache Cassandra, Google Bigtable, and HBase, which provide high scalability, fault tolerance, and fast read/write performance.
Data Modeling: Document vs Wide Column Approach
Document stores organize data in flexible, JSON-like documents that encapsulate related information within a single record, enabling hierarchical and nested data modeling suited for complex, varied datasets. Wide column stores arrange data into rows and dynamic columns grouped into column families, allowing efficient storage of sparse data and optimized queries on large-scale datasets with a focus on scalability. The document approach favors rich, self-describing records ideal for applications requiring schema flexibility, while the wide column approach excels in scenarios demanding high throughput and distributed data across clusters.
Performance and Scalability Comparison
Document stores like MongoDB provide flexible schema design, enabling better performance for hierarchical and semi-structured data queries, while wide column stores such as Apache Cassandra excel in write-heavy workloads and horizontal scalability due to their distributed architecture. Wide column stores offer linear scalability and high availability through partitioning and replication, handling massive volumes of time-series or analytics data with predictable latency. Document stores may face challenges in scaling across geographies but achieve faster query performance with rich indexes and secondary indexes optimized for nested documents.
Query Flexibility and Indexing
Document Stores provide high query flexibility by allowing complex, nested queries on JSON-like documents, supporting dynamic schemas and rich indexing options such as single-field, compound, and text indexes. Wide Column Stores optimize for rapid access to large volumes of structured data with sparse, column-oriented storage, offering efficient indexing primarily through primary keys and secondary indexes but generally less support for ad-hoc query patterns. The choice between the two depends on the need for flexible querying and indexing versatility versus high-performance, scalable data retrieval in columnar formats.
Use Cases for Document Stores
Document stores excel in managing semi-structured data such as JSON, XML, and BSON, making them ideal for content management systems, e-commerce platforms, and real-time analytics where flexible schema design is crucial. They support nested documents and dynamic fields, enabling developers to handle complex data types and evolving requirements without schema migrations. Use cases often include user profiles, product catalogs, and event logging, where rapid iteration and scalability under diverse query patterns are essential.
Use Cases for Wide Column Stores
Wide column stores excel in handling large volumes of sparse data across distributed systems, making them ideal for real-time analytics, time-series data, and IoT applications. These databases, such as Apache Cassandra and HBase, are optimized for write-heavy workloads and provide high availability and scalability in multi-node clusters. Use cases include fraud detection, recommendation engines, and telemetry data storage where rapid data ingestion and flexible schema designs are critical.
Pros and Cons: Document Stores vs Wide Column Stores
Document stores excel at handling semi-structured data with flexible schemas, making them ideal for applications requiring dynamic and nested data models, but they may suffer from slower complex querying compared to wide column stores. Wide column stores optimize read and write performance across large-scale, distributed datasets with high throughput and efficient compression, yet they often require more rigid schema design and complex data modeling efforts. Choosing between document stores and wide column stores depends on specific use cases involving schema flexibility, query complexity, and scalability requirements.
Choosing the Right Database for Your Needs
Document stores like MongoDB excel in managing semi-structured data with flexible schemas, ideal for applications requiring dynamic content and nested documents. Wide column stores such as Cassandra offer high scalability and fast writes, making them suitable for large-scale analytical workloads and real-time data processing. Selecting the right database depends on data complexity, query patterns, and scalability requirements, where document stores favor rich, hierarchical data and wide column stores support massive, distributed datasets.
Document Store Infographic