Data redaction ensures sensitive information is securely removed or obscured from documents, protecting privacy and complying with regulations. Implementing effective data redaction techniques minimizes the risk of data breaches and unauthorized access. Explore the rest of the article to learn how your organization can benefit from advanced data redaction methods.
Table of Comparison
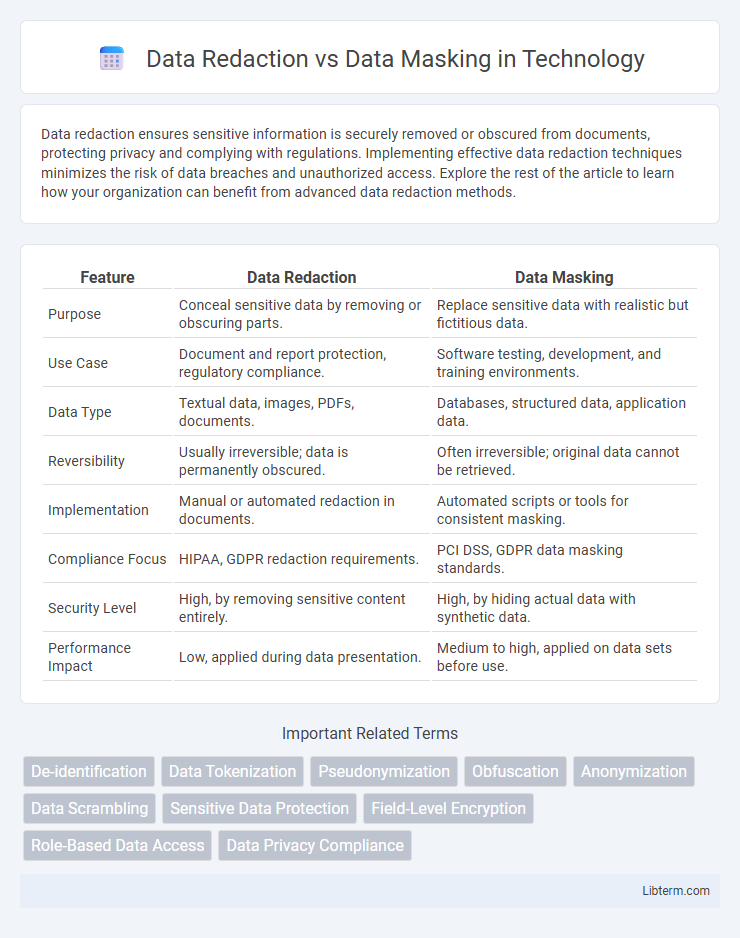
| Feature | Data Redaction | Data Masking |
|---|---|---|
| Purpose | Conceal sensitive data by removing or obscuring parts. | Replace sensitive data with realistic but fictitious data. |
| Use Case | Document and report protection, regulatory compliance. | Software testing, development, and training environments. |
| Data Type | Textual data, images, PDFs, documents. | Databases, structured data, application data. |
| Reversibility | Usually irreversible; data is permanently obscured. | Often irreversible; original data cannot be retrieved. |
| Implementation | Manual or automated redaction in documents. | Automated scripts or tools for consistent masking. |
| Compliance Focus | HIPAA, GDPR redaction requirements. | PCI DSS, GDPR data masking standards. |
| Security Level | High, by removing sensitive content entirely. | High, by hiding actual data with synthetic data. |
| Performance Impact | Low, applied during data presentation. | Medium to high, applied on data sets before use. |
Introduction to Data Protection Techniques
Data redaction involves permanently removing or obscuring sensitive information from documents to prevent unauthorized access, while data masking replaces original data with realistic but fictional data to maintain usability in non-production environments. Both techniques are essential components of data protection strategies aimed at securing personally identifiable information (PII) and confidential business data. Implementing these methods helps organizations comply with regulations such as GDPR and HIPAA by minimizing data exposure risks during analysis, development, and sharing processes.
Understanding Data Redaction
Data redaction permanently removes or obscures sensitive information within a dataset, ensuring that unauthorized users cannot access the original data. It is often used in document sharing, compliance reporting, and legal disclosures to protect confidential information such as social security numbers, credit card details, or personal identifiers. Unlike data masking, which replaces data with fictitious but realistic values for testing or development, redaction irreversibly eliminates select data elements to prevent exposure of sensitive content.
What is Data Masking?
Data masking is a security technique that replaces sensitive information with fictional but realistic data to protect privacy while maintaining usability for testing or analysis. It ensures that masked data retains the same format and structure as the original, enabling seamless integration with applications without exposing confidential details. Commonly used in software development, data masking helps organizations comply with data protection regulations like GDPR and HIPAA by preventing unauthorized access to sensitive information.
Key Differences: Data Redaction vs Data Masking
Data redaction permanently removes sensitive information from documents or databases by obscuring or deleting specific data elements, ensuring they are unreadable and inaccessible. Data masking disguises data by replacing original values with realistic but fictitious data to protect privacy while maintaining usability for testing or analysis. The key difference lies in redaction's irreversible data removal compared to masking's reversible or adjustable data obfuscation, balancing security and utility needs.
Use Cases for Data Redaction
Data redaction is primarily used in regulatory compliance scenarios such as GDPR and HIPAA to hide sensitive information in documents before sharing or publishing. It is essential for legal, financial, and healthcare industries where partial data needs to be obscured to protect privacy while preserving the document's usability. Data redaction effectively removes confidential content from text, images, or PDFs without altering underlying data structures, making it ideal for audit reports and customer statements.
Use Cases for Data Masking
Data masking is primarily used in non-production environments such as development, testing, and training to protect sensitive information while maintaining data utility. It enables organizations to comply with data privacy regulations like GDPR and HIPAA by obfuscating personally identifiable information (PII) and financial data, reducing the risk of data breaches. Unlike data redaction, which permanently removes data from view, data masking creates realistic but fictitious data to support accurate application testing and analytics without exposing confidential details.
Compliance and Regulatory Considerations
Data redaction and data masking are critical techniques for compliance with regulations such as GDPR, HIPAA, and CCPA, ensuring sensitive information is protected during data processing and sharing. Data redaction permanently removes or obscures sensitive content in documents, making it compliant with legal disclosure requirements, while data masking substitutes data with realistic but fictitious values to maintain usability in non-production environments without exposing real data. Regulatory frameworks often mandate strict controls on how personally identifiable information (PII) and protected health information (PHI) are handled, making the choice between redaction and masking essential to meet audit and privacy standards.
Choosing the Right Method for Your Organization
Selecting the appropriate method between data redaction and data masking depends on your organization's compliance requirements and data usage scenarios. Data redaction is ideal for permanently removing sensitive information in documents or logs to prevent unauthorized access, while data masking is best suited for creating realistic, usable datasets for testing and development without exposing actual sensitive data. Evaluating factors such as data sensitivity, user access levels, and operational needs ensures the chosen technique aligns with security policies and business objectives.
Implementation Challenges and Best Practices
Data redaction often faces challenges such as maintaining data usability while securely hiding sensitive information, requiring precise identification and consistent application of redaction rules across varied data formats. Data masking implementation demands ensuring realistic data substitution without compromising the integrity and functionality of underlying systems during testing or analysis. Best practices include employing automated tools for consistent application, continuous auditing to verify compliance, and integrating security policies that align with organizational data governance frameworks.
Future Trends in Data Privacy Protection
Data redaction is evolving with AI-driven automated detection and removal of sensitive information, enhancing efficiency in real-time data protection, while data masking is advancing through dynamic, context-aware techniques that generate realistic but non-sensitive data for testing and analytics. Emerging trends emphasize integration with zero-trust architectures and privacy-preserving technologies like homomorphic encryption to safeguard data across distributed environments. Future developments will prioritize adaptive privacy controls powered by machine learning to balance user access with stringent regulatory compliance globally.
Data Redaction Infographic