A distributed database stores data across multiple physical locations, enhancing scalability and fault tolerance by allowing simultaneous access and updates from various nodes. It ensures data consistency and availability through advanced synchronization and replication mechanisms, catering to large-scale applications and real-time processing needs. Explore the full article to understand how distributed databases can optimize your data management strategy.
Table of Comparison
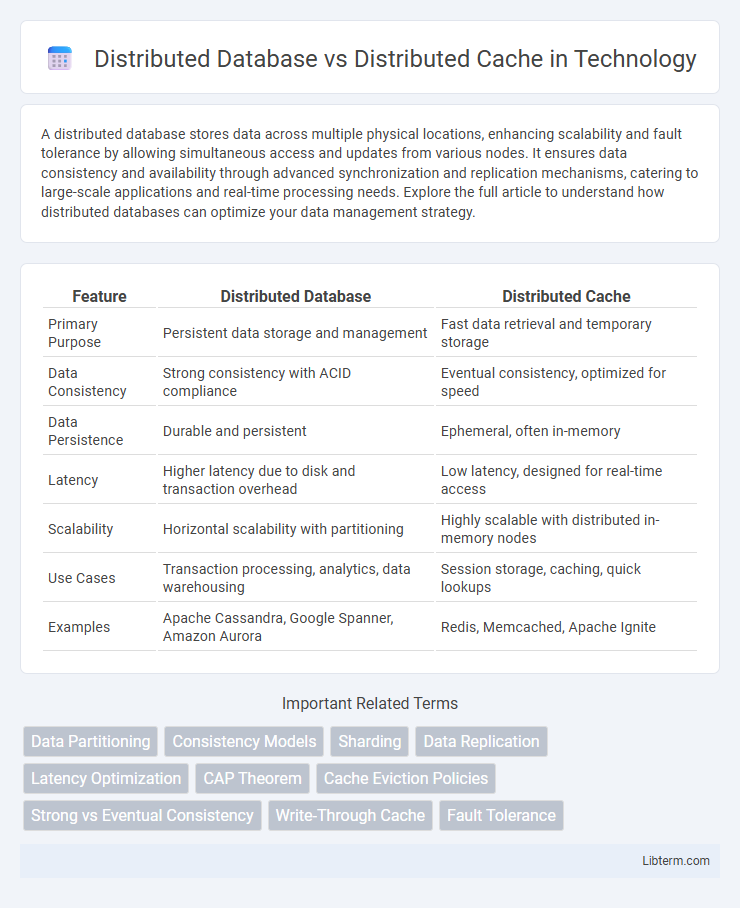
| Feature | Distributed Database | Distributed Cache |
|---|---|---|
| Primary Purpose | Persistent data storage and management | Fast data retrieval and temporary storage |
| Data Consistency | Strong consistency with ACID compliance | Eventual consistency, optimized for speed |
| Data Persistence | Durable and persistent | Ephemeral, often in-memory |
| Latency | Higher latency due to disk and transaction overhead | Low latency, designed for real-time access |
| Scalability | Horizontal scalability with partitioning | Highly scalable with distributed in-memory nodes |
| Use Cases | Transaction processing, analytics, data warehousing | Session storage, caching, quick lookups |
| Examples | Apache Cassandra, Google Spanner, Amazon Aurora | Redis, Memcached, Apache Ignite |
Introduction to Distributed Database and Distributed Cache
Distributed databases store and manage data across multiple nodes, ensuring consistency, fault tolerance, and scalability for complex transactional workloads. Distributed caches provide high-speed data retrieval by temporarily storing frequently accessed data in memory across various servers, significantly reducing latency for read-heavy applications. Both systems enhance performance and availability but cater to different use cases--persistent storage versus rapid access.
Core Concepts: Key Differences Explained
Distributed databases store data across multiple nodes to ensure data consistency, fault tolerance, and transactional support, making them ideal for complex queries and persistent storage. Distributed caches prioritize fast data retrieval by temporarily storing frequently accessed data in-memory across nodes, optimizing performance and reducing latency for read-heavy workloads. Key differences include durability and consistency guarantees, with distributed databases emphasizing ACID compliance while distributed caches focus on speed and scalability.
Architecture Overview: How They Work
Distributed databases organize data across multiple physical servers to provide scalability and fault tolerance through data partitioning and replication, ensuring consistency and durability via consensus protocols like Paxos or Raft. Distributed caches store frequently accessed data across a cluster of nodes, prioritizing low latency and high throughput by maintaining in-memory copies, often using strategies like LRU eviction and cache coherence mechanisms. Both architectures rely on network communication for synchronization, but distributed databases enforce strong consistency models, whereas distributed caches typically offer eventual consistency to enhance performance.
Data Consistency and Integrity
Distributed databases ensure strong data consistency and integrity through mechanisms like two-phase commit protocols and consensus algorithms such as Paxos or Raft, maintaining synchronized state across multiple nodes. In contrast, distributed caches prioritize low latency and high availability, often employing eventual consistency models that may tolerate temporary data discrepancies for faster read/write operations. Unlike distributed caches, distributed databases implement strict ACID (Atomicity, Consistency, Isolation, Durability) properties to guarantee reliable and consistent data transactions in distributed environments.
Performance and Scalability Factors
Distributed databases provide strong consistency and durability by replicating data across multiple nodes, ensuring reliable performance in transactional workloads, but may introduce latency due to synchronization overhead. Distributed caches optimize read-heavy operations with in-memory data storage, dramatically reducing access times and increasing throughput, yet often sacrifice consistency for speed. Scalability in distributed databases relies on partitioning and replication strategies, while distributed caches leverage horizontal scaling to handle high traffic volumes efficiently.
Use Cases: When to Use Database vs Cache
Distributed databases are ideal for scenarios requiring strong consistency, complex querying, and persistent data storage across multiple nodes, such as financial applications and inventory management systems. Distributed caches excel in use cases demanding low latency and high throughput for read-heavy operations, including session storage, real-time analytics, and content delivery networks. Choosing between a distributed database and a distributed cache depends on whether the use case prioritizes data durability and transactional integrity or fast access to frequently read data.
Data Persistence and Storage Mechanisms
Distributed databases use complex storage mechanisms such as distributed file systems, replication, and sharding to ensure durable data persistence across multiple nodes. Distributed caches primarily focus on in-memory storage for faster data retrieval, often sacrificing persistence to optimize speed and reduce latency. While distributed databases guarantee ACID compliance and long-term storage, distributed caches rely on ephemeral data retention with optional persistence layers like write-back or write-through strategies.
Fault Tolerance and Reliability
Distributed databases ensure fault tolerance through data replication across multiple nodes, providing high availability and consistency even during node failures. Distributed caches prioritize low-latency data access by replicating cache entries, but often trade strong consistency for performance, which can impact reliability during network partitions. Effective fault tolerance in distributed systems requires balancing data durability in databases with faster access from caches, optimizing reliability based on workload requirements.
Popular Technologies and Tools
Distributed databases like Apache Cassandra, Amazon DynamoDB, and Google Cloud Spanner provide horizontal scalability, data consistency, and fault tolerance for handling large datasets across multiple nodes. Distributed caches such as Redis, Memcached, and Apache Ignite focus on ultra-fast data access by storing frequently accessed information in-memory to reduce latency and offload databases. Choosing between these technologies depends on use cases where databases ensure durable storage and complex querying, while caches optimize performance through rapid data retrieval.
Choosing the Right Solution for Your Application
Distributed databases provide persistent, scalable storage for complex queries and transactional consistency, making them ideal for applications requiring durable data and strong ACID compliance. Distributed caches offer ultra-fast, in-memory data access designed for high-throughput read operations and low latency, best suited for session management or frequently accessed ephemeral data. Selecting the right solution depends on factors like data durability needs, read/write patterns, and latency tolerance to optimize performance and reliability in your application architecture.
Distributed Database Infographic