Tokenized data breaks down text into smaller units called tokens, which are essential for natural language processing applications. These tokens can be words, characters, or subwords, helping algorithms analyze and understand language patterns more effectively. Discover how tokenized data enhances machine learning models and improves your text analysis by reading the full article.
Table of Comparison
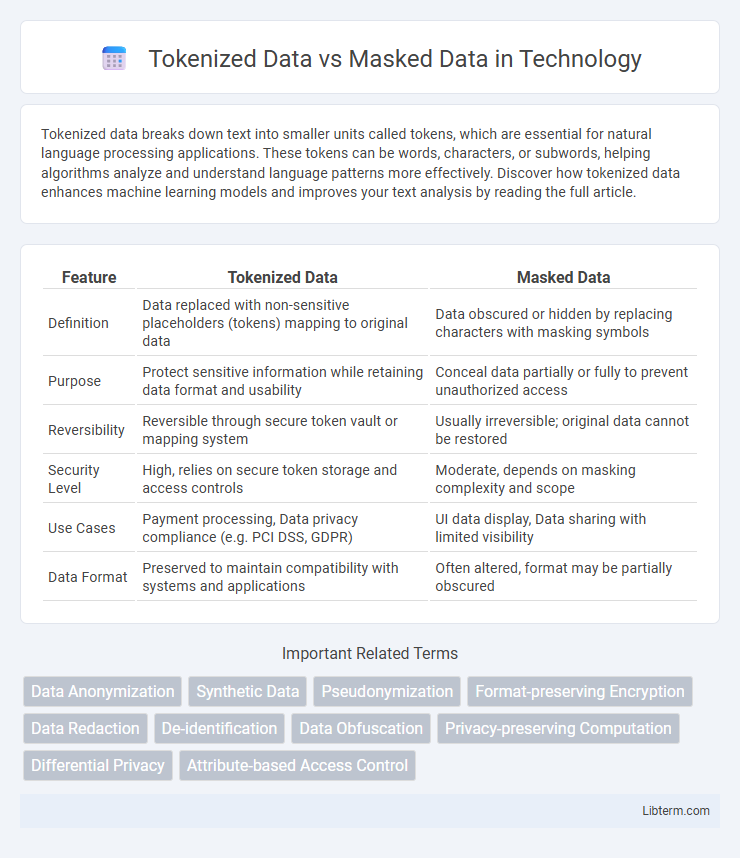
| Feature | Tokenized Data | Masked Data |
|---|---|---|
| Definition | Data replaced with non-sensitive placeholders (tokens) mapping to original data | Data obscured or hidden by replacing characters with masking symbols |
| Purpose | Protect sensitive information while retaining data format and usability | Conceal data partially or fully to prevent unauthorized access |
| Reversibility | Reversible through secure token vault or mapping system | Usually irreversible; original data cannot be restored |
| Security Level | High, relies on secure token storage and access controls | Moderate, depends on masking complexity and scope |
| Use Cases | Payment processing, Data privacy compliance (e.g. PCI DSS, GDPR) | UI data display, Data sharing with limited visibility |
| Data Format | Preserved to maintain compatibility with systems and applications | Often altered, format may be partially obscured |
Introduction to Tokenized and Masked Data
Tokenized data involves breaking text into smaller units called tokens, which can be words, subwords, or characters, enabling efficient processing by natural language models. Masked data refers to the technique where certain tokens in a sequence are replaced with a special mask token, aiding models in learning contextual relationships by predicting the hidden content. Both tokenization and masking are fundamental preprocessing steps that enhance the training and performance of language models like BERT and GPT.
Understanding Tokenized Data
Tokenized data involves breaking text into meaningful units called tokens, which can be words, subwords, or characters, enabling efficient processing by natural language models. Each token represents a discrete element of language, facilitating tasks like text analysis, machine translation, and sentiment detection by preserving the semantic structure. Understanding tokenized data is crucial for optimizing language model input, as it directly impacts model accuracy and computational efficiency.
What is Masked Data?
Masked data refers to information that has been deliberately altered by obscuring or replacing sensitive elements to protect privacy while preserving its utility for analysis. Common masking techniques include character substitution, encryption, or redaction, ensuring confidential data like personally identifiable information (PII) remains undisclosed. This approach is widely used in data privacy compliance to enable secure processing and sharing without exposing original sensitive content.
Core Differences: Tokenized vs Masked Data
Tokenized data involves breaking text into meaningful units, such as words or subwords, enabling efficient analysis and processing by language models. Masked data hides or replaces certain tokens with placeholders, guiding models to predict missing information and improve contextual understanding. The core difference lies in tokenization segmenting the text for structure, while masking alters the data to train prediction capabilities.
Security Benefits of Tokenization
Tokenized data replaces sensitive information with non-sensitive equivalents, significantly reducing the risk of data breaches by ensuring original data is never exposed or transmitted during processing. Unlike masked data, which obscures information but still retains the format and sometimes underlying data patterns, tokenization eliminates the link between the token and the original data stored separately and securely. This separation and cryptographically secure token generation enhance compliance with data protection regulations such as PCI DSS and HIPAA, offering stronger protection against unauthorized access and identity theft.
Privacy Protection through Data Masking
Data masking enhances privacy protection by replacing sensitive information with fictitious but realistic values, maintaining data utility without exposing original data. Tokenized data substitutes sensitive information with non-sensitive tokens that reference the original data stored securely, enabling controlled access and reduced risk of data breaches. Both methods safeguard privacy, yet data masking provides stronger anonymization for analytic environments where data exposure must be minimized.
Use Cases for Tokenized Data
Tokenized data is primarily used in payment processing and secure data storage to replace sensitive information with a non-sensitive equivalent, reducing the risk of data breaches while maintaining usability for transactions. It is ideal for compliance with regulations such as PCI-DSS by ensuring that credit card details are not stored in their original form. Tokenized data also supports analytics and business intelligence without exposing personal identifiers, enabling secure insights into customer behavior.
Common Applications of Masked Data
Masked data is commonly used in natural language processing tasks such as language modeling, text generation, and data anonymization, where sensitive information is obscured while retaining contextual clues. Techniques like Masked Language Modeling (MLM) enable models like BERT to predict missing tokens, improving understanding of word dependencies and context. Masked data also supports privacy-preserving applications by hiding personally identifiable information during data sharing and analysis.
Compliance Considerations: Tokenization vs Masking
Tokenized data replaces sensitive information with non-sensitive equivalents while maintaining referential integrity, enabling easier compliance with PCI DSS and GDPR by minimizing exposure of actual data. Masked data obscures original data by transforming it, often rendering it irreversible and suitable for non-production environments, supporting compliance by limiting access to sensitive information. Choosing between tokenization and masking depends on regulatory requirements, data usage context, and the need for reversibility in compliance frameworks.
Choosing the Right Approach: Tokenized or Masked Data?
Choosing the right approach between tokenized data and masked data depends on the specific use case and model requirements; tokenized data efficiently represents text as discrete units for language modeling, while masked data is crucial for tasks like masked language modeling that require context prediction through obscured tokens. Tokenized data enables models like GPT to generate coherent sequences by understanding word boundaries, whereas masked data serves models such as BERT to learn deeper contextual embeddings by predicting missing words. Evaluating task goals, model architecture, and training objectives determines whether tokenization or masking better optimizes performance and accuracy in natural language processing applications.
Tokenized Data Infographic