Trie data structures efficiently store and retrieve strings by organizing characters in a tree-like format, enabling fast prefix searches and autocomplete features. Their unique structure minimizes redundant storage of common prefixes, making them ideal for applications like dictionary implementations and IP routing. Explore the rest of the article to discover how Tries can enhance your data handling and search operations.
Table of Comparison
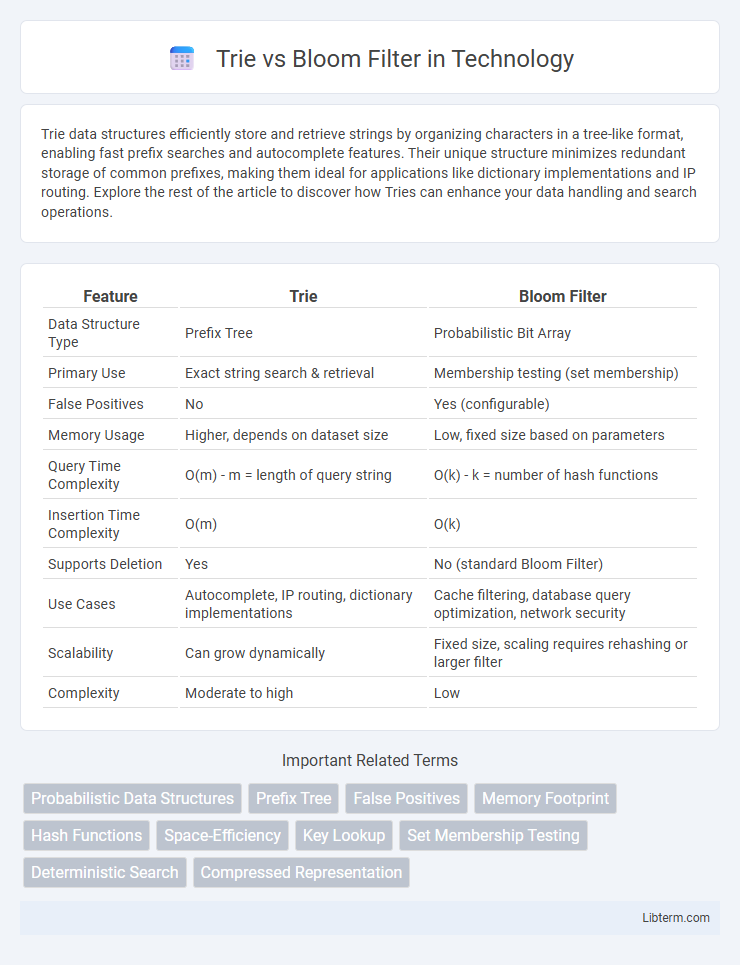
| Feature | Trie | Bloom Filter |
|---|---|---|
| Data Structure Type | Prefix Tree | Probabilistic Bit Array |
| Primary Use | Exact string search & retrieval | Membership testing (set membership) |
| False Positives | No | Yes (configurable) |
| Memory Usage | Higher, depends on dataset size | Low, fixed size based on parameters |
| Query Time Complexity | O(m) - m = length of query string | O(k) - k = number of hash functions |
| Insertion Time Complexity | O(m) | O(k) |
| Supports Deletion | Yes | No (standard Bloom Filter) |
| Use Cases | Autocomplete, IP routing, dictionary implementations | Cache filtering, database query optimization, network security |
| Scalability | Can grow dynamically | Fixed size, scaling requires rehashing or larger filter |
| Complexity | Moderate to high | Low |
Introduction to Trie and Bloom Filter
A Trie is a tree-like data structure used to store a dynamic set of strings, enabling efficient retrieval by representing keys as paths from the root to leaves. Bloom Filter is a probabilistic data structure designed to test set membership, offering space-efficient storage with possible false positives but no false negatives. Both structures optimize search operations, with Trie excelling in prefix-based queries and Bloom Filter prioritizing memory usage and query speed.
Core Concepts of Trie
Trie is a tree-like data structure that stores strings by breaking them into characters, allowing efficient retrieval through prefix searches. Each node represents a character, and paths from the root to leaves correspond to stored words, enabling fast lookups and autocomplete functionalities. Unlike Bloom Filters, which use probabilistic membership testing, Tries provide exact matches with guaranteed retrieval accuracy.
Core Concepts of Bloom Filter
A Bloom Filter is a space-efficient probabilistic data structure used to test whether an element is a member of a set, allowing false positives but no false negatives. It consists of multiple hash functions that map elements to a bit array, setting bits to indicate presence. Compared to Trie, which stores keys explicitly with a tree structure, Bloom Filters trade accuracy for faster membership queries and reduced memory usage in large-scale applications.
Memory Usage Comparison
Trie data structures consume more memory due to storing nodes for each character and pointers, often leading to increased overhead for large alphabets or datasets. Bloom Filters provide a memory-efficient alternative by using bit arrays and multiple hash functions, significantly reducing space at the cost of false positives. When memory usage is critical, Bloom Filters are preferred for approximate membership queries, while Tries offer exact lookups with higher memory consumption.
Performance and Speed Analysis
Trie data structures provide fast prefix-based lookups with time complexity proportional to the key length, enabling efficient exact and prefix searches ideal for autocomplete systems. Bloom Filters offer probabilistic membership checking with constant time complexity, providing significantly faster query speeds and lower memory usage but at the cost of false positives and no support for key retrieval. Performance comparison shows Tries excel in applications requiring ordered data and retrieval, while Bloom Filters are superior for high-speed membership tests in memory-constrained environments.
False Positives and Accuracy
Trie data structures provide exact membership queries with zero false positives by storing keys explicitly in a tree format, ensuring high accuracy for string search operations. Bloom Filters use multiple hash functions to represent sets compactly, trading space efficiency for a controlled false positive rate that can be adjusted by tuning filter size and hash functions. While Tries guarantee perfect accuracy with increased memory usage and slower insertion, Bloom Filters offer faster queries and lower memory at the cost of probabilistic false positives.
Scalability and Flexibility
Trie structures offer high flexibility in handling dynamic datasets by supporting prefix-based queries and efficient updates with scalable memory usage dependent on the dataset's size and alphabet. Bloom Filters excel in scalability for large datasets due to their fixed-size bit array and probabilistic membership testing, but they lack flexibility as they do not support deletions or retrieval of stored keys. The choice between Trie and Bloom Filter depends on the need for exact key storage and flexible querying versus memory-efficient, fast membership checks at scale.
Use Cases for Trie
Tries are ideal for applications requiring efficient prefix-based searches, such as autocomplete systems, spell checkers, and IP routing. Their ability to store and retrieve variable-length strings with deterministic lookup times makes them valuable in dictionary implementations and word games. Tries excel when exact match retrieval and ordered retrieval of keys are prioritized over space efficiency.
Use Cases for Bloom Filter
Bloom Filters excel in applications requiring fast and memory-efficient probabilistic membership testing, such as database query optimization, network packet filtering, and distributed systems for cache invalidation. Their ability to quickly determine whether an element is possibly in a set or definitely not makes them ideal for use cases where false positives are acceptable but false negatives are not. Common implementations include web cache sharing, spell checking, and preventing duplicate transmissions in networking protocols.
Choosing Between Trie and Bloom Filter
Choosing between a Trie and a Bloom Filter depends on the use case requirements for space efficiency, false positives, and exactness of lookups. Tries provide exact match search with prefix querying capabilities, making them ideal for applications like autocomplete or dictionary implementations where precise data retrieval is crucial. Bloom Filters offer probabilistic membership testing with a significantly smaller memory footprint but potentially allow false positives, making them suitable for scenarios where space is limited and false positives are tolerable, such as network caching or database query optimizations.
Trie Infographic