A document store is a type of NoSQL database designed to manage, store, and retrieve documents in formats like JSON, XML, or BSON. It efficiently handles semi-structured data, enabling flexible and scalable solutions for applications requiring dynamic schemas. Discover how a document store can enhance Your data management strategy in the rest of this article.
Table of Comparison
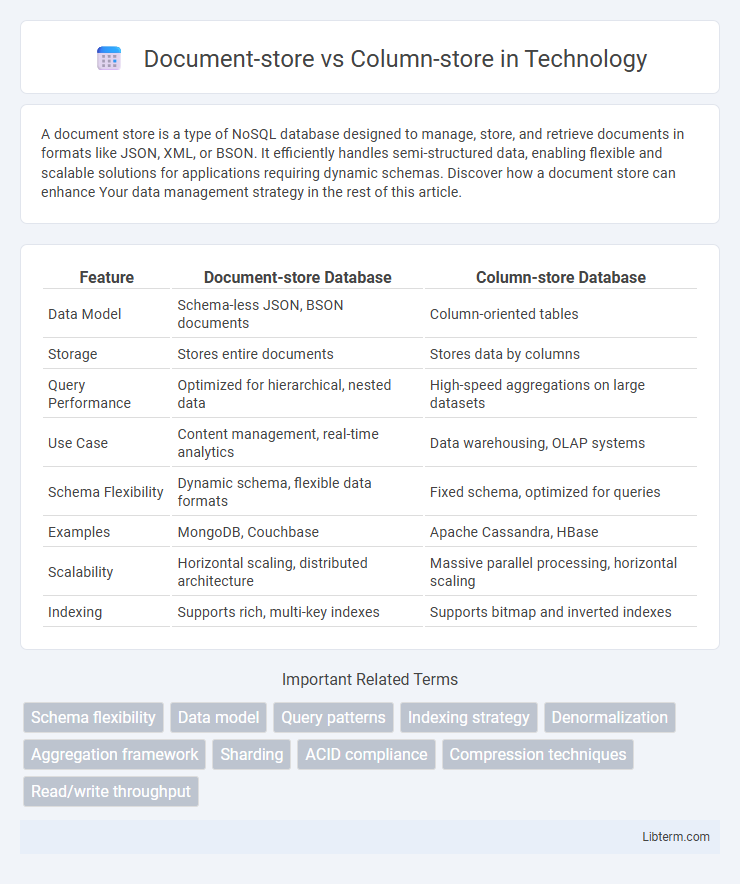
| Feature | Document-store Database | Column-store Database |
|---|---|---|
| Data Model | Schema-less JSON, BSON documents | Column-oriented tables |
| Storage | Stores entire documents | Stores data by columns |
| Query Performance | Optimized for hierarchical, nested data | High-speed aggregations on large datasets |
| Use Case | Content management, real-time analytics | Data warehousing, OLAP systems |
| Schema Flexibility | Dynamic schema, flexible data formats | Fixed schema, optimized for queries |
| Examples | MongoDB, Couchbase | Apache Cassandra, HBase |
| Scalability | Horizontal scaling, distributed architecture | Massive parallel processing, horizontal scaling |
| Indexing | Supports rich, multi-key indexes | Supports bitmap and inverted indexes |
Introduction to Document-Store and Column-Store Databases
Document-store databases organize data as JSON-like documents, enabling flexible schema design and efficient storage for semi-structured data. Column-store databases store data in columns rather than rows, optimizing read performance for analytical queries and large-scale data aggregation. Both database types cater to specific use cases: document stores excel in content management and real-time applications, while column stores dominate in data warehousing and business intelligence.
Key Concepts: How Document-Stores Work
Document-stores organize data as flexible, schema-less JSON-like documents, enabling dynamic and nested data structures that accommodate diverse and evolving datasets. Each document contains a unique key for fast retrieval, supporting complex queries through indexing on fields within the documents. This structure allows seamless storage of related information in a single entity, optimizing performance for applications with variable or hierarchical data models.
Core Principles of Column-Store Databases
Column-store databases organize data by columns rather than rows, enabling efficient retrieval and compression for analytical queries. Each column is stored separately, allowing faster aggregation and scan operations on large datasets by reading only relevant columns instead of entire rows. The core principle centers on optimizing input/output performance and reducing memory usage by leveraging columnar data locality and compression techniques.
Data Modeling: Flexibility vs Structure
Document-store databases offer high flexibility in data modeling by allowing schema-less storage of semi-structured JSON-like documents, which enables rapid iteration and adaptation to evolving application requirements. Column-store databases enforce a rigid, predefined schema optimized for aggregating and querying large volumes of structured data efficiently, making them ideal for analytical workloads. The choice between document-store and column-store hinges on the need for flexible, hierarchical data representations versus the performance benefits of fixed, columnar data layouts for complex queries.
Query Performance: Document-Store vs Column-Store
Document-store databases excel in flexible query performance by allowing complex, nested JSON documents to be retrieved efficiently without expensive joins, ideal for hierarchical data and rapid development cycles. Column-store databases optimize query performance for analytical workloads by storing data in columns, enabling faster aggregation and scanning across large datasets with reduced I/O and high compression rates. Query performance in document stores benefits from schema flexibility and indexing on document fields, whereas column-stores leverage columnar storage and vectorized execution for superior speed in read-heavy, aggregation-intensive scenarios.
Use Cases and Industry Applications
Document-store databases excel in managing semi-structured data such as JSON and XML, making them ideal for content management, e-commerce platforms, and real-time analytics where flexible schema design is crucial. Column-store databases optimize read-heavy workloads and large-scale analytical queries, widely used in data warehousing, business intelligence, and financial reporting industries. Industries like healthcare, telecommunications, and retail leverage document-stores for customer personalization and dynamic data, while column-stores support performance-driven applications requiring rapid aggregation on massive datasets.
Scalability and Handling Big Data
Document-store databases excel in scalability by enabling flexible schema designs and horizontal scaling through sharding, making them well-suited for handling heterogeneous big data. Column-store databases optimize performance for big data analytics by storing data in columns, allowing efficient compression and faster read operations, particularly for aggregation queries on large datasets. Both architectures support distributed systems, but column-stores typically offer superior read scalability for analytical workloads, whereas document-stores provide better adaptability for diverse data structures.
Indexing Techniques and Optimization
Document-store databases utilize flexible, schema-less indexing techniques such as inverted indexes and B-tree variants optimized for JSON or BSON structures, enabling efficient querying of nested and varied data formats. Column-store databases employ columnar indexing methods like bitmap indexes and zone maps that enhance read performance by scanning only relevant columns, optimizing aggregation and analytical queries. Both systems leverage compression algorithms and query optimization strategies tailored to their indexing mechanisms to improve data retrieval speed and resource utilization.
Pros and Cons: Document-Store vs Column-Store
Document-store databases excel in handling semi-structured data with flexible schemas and nested documents, making them ideal for applications requiring agility and rapid iteration, but they can suffer from inconsistent query performance and limited support for complex joins. Column-store databases optimize analytical queries by efficiently compressing and scanning columns, delivering high performance on large-scale read-heavy workloads, yet they often struggle with write-intensive operations and schema changes. Choosing between document-store and column-store depends on factors like query patterns, data structure complexity, and workload characteristics.
Choosing the Right Database for Your Needs
Document-store databases excel in managing semi-structured data with flexible schemas, ideal for applications requiring rapid development and evolving data models. Column-store databases optimize storage and query performance for analytical workloads by storing data column-wise, making them well-suited for complex aggregations and large-scale data analysis. Selecting the appropriate database depends on workload type, data structure, and query patterns; document stores favor operational, transaction-oriented use cases while column stores enhance efficiency in OLAP and business intelligence environments.
Document-store Infographic