Covariate shift occurs when the distribution of input data changes between training and testing phases, causing models to perform poorly on new data. Addressing covariate shift involves techniques like importance weighting and domain adaptation to maintain model accuracy and reliability. Explore the rest of the article to learn how to detect and manage covariate shift in your machine learning projects.
Table of Comparison
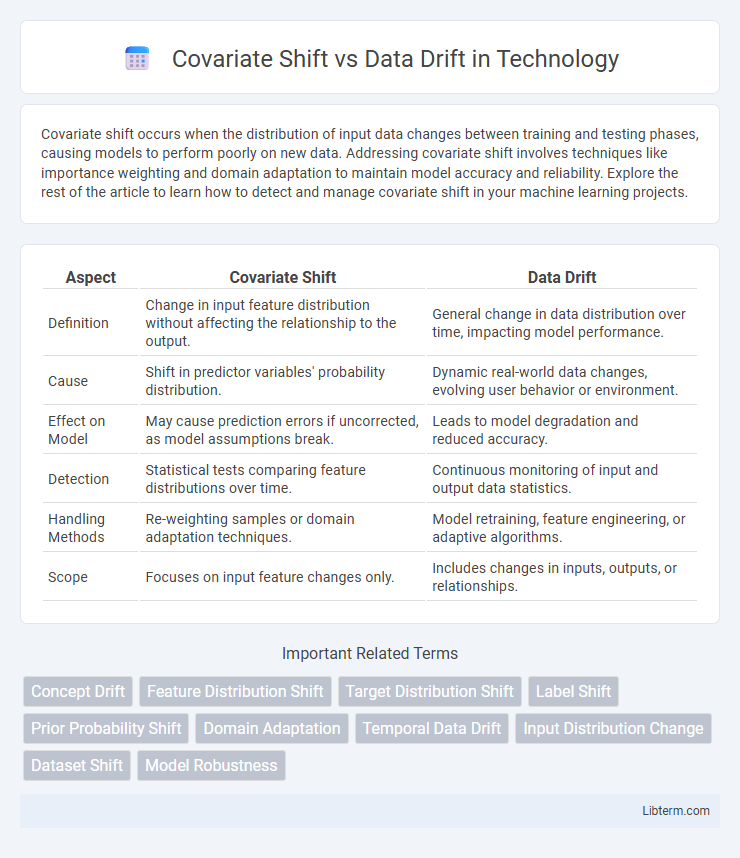
| Aspect | Covariate Shift | Data Drift |
|---|---|---|
| Definition | Change in input feature distribution without affecting the relationship to the output. | General change in data distribution over time, impacting model performance. |
| Cause | Shift in predictor variables' probability distribution. | Dynamic real-world data changes, evolving user behavior or environment. |
| Effect on Model | May cause prediction errors if uncorrected, as model assumptions break. | Leads to model degradation and reduced accuracy. |
| Detection | Statistical tests comparing feature distributions over time. | Continuous monitoring of input and output data statistics. |
| Handling Methods | Re-weighting samples or domain adaptation techniques. | Model retraining, feature engineering, or adaptive algorithms. |
| Scope | Focuses on input feature changes only. | Includes changes in inputs, outputs, or relationships. |
Understanding Covariate Shift
Covariate shift occurs when the distribution of input features changes between the training and testing phases, while the relationship between inputs and outputs remains stable. Understanding covariate shift is crucial for maintaining model performance in evolving real-world environments where feature distributions may shift due to temporal, demographic, or operational changes. Techniques such as reweighting samples, domain adaptation, and feature importance monitoring help detect and mitigate covariate shift effectively.
Defining Data Drift
Data drift refers to the changes in the statistical properties of the input data over time, affecting model performance by altering feature distributions or relationships. Unlike covariate shift, which specifically involves changes in the input variable distribution while the conditional distribution remains constant, data drift encompasses broader variations such as shifts in feature-label dependencies or emerging patterns. Monitoring data drift through techniques like distribution comparison and anomaly detection is essential to maintain the accuracy and reliability of machine learning models in dynamic environments.
Key Differences Between Covariate Shift and Data Drift
Covariate shift specifically refers to changes in the distribution of input features without alterations to the conditional distribution of the output given inputs, while data drift encompasses a broader spectrum of shifts that may include changes in feature distribution, target distribution, or their relationship. Key differences between covariate shift and data drift lie in the affected data components: covariate shift impacts only the input feature distribution, whereas data drift may affect features, targets, or both over time in a production environment. Understanding these distinctions is crucial for developing accurate machine learning models and implementing appropriate monitoring strategies for model performance degradation.
Causes of Covariate Shift in Machine Learning
Covariate shift in machine learning occurs when the input feature distribution changes between training and deployment, while the conditional distribution of the output given inputs remains the same. Causes of covariate shift include changes in data collection methods, evolving user behavior, and varying environmental conditions that alter the feature space but not the relationship to the target variable. Recognizing covariate shift is critical for maintaining model performance and requires strategies like importance weighting or domain adaptation to address these distributional changes.
Common Sources of Data Drift
Common sources of data drift include changes in user behavior, evolving market conditions, seasonal trends, and modifications in data collection methods. Covariate shift specifically refers to variations in the input feature distribution while the relationship between input and output remains constant. Detecting data drift requires continuous monitoring to maintain model accuracy and prevent degradation in predictive performance.
Detecting Covariate Shift: Methods and Tools
Detecting covariate shift involves monitoring changes in the joint distribution of input features between training and deployment datasets using statistical tests such as the Kolmogorov-Smirnov test or the Population Stability Index (PSI). Machine learning tools like Alibi Detect and River offer specialized modules to systematically identify shifts in feature distributions, enabling early warnings for model degradation. Leveraging dimensionality reduction techniques and feature importance ranking enhances the interpretability and precision of covariate shift detection frameworks in real-world applications.
Identifying and Monitoring Data Drift
Data drift occurs when the statistical properties of input data change over time, impacting model performance, while covariate shift specifically refers to changes in the input feature distribution without changes in the conditional distribution of the output. Identifying data drift involves continuous monitoring of key data metrics such as feature means, variances, and distributional shapes using techniques like population stability index (PSI) and Kolmogorov-Smirnov tests. Effective monitoring systems leverage real-time dashboards and alert mechanisms to detect significant deviations, enabling timely model retraining and maintaining predictive accuracy.
Impact of Covariate Shift on Model Performance
Covariate shift occurs when the distribution of input features changes between training and deployment, leading to a mismatch that can degrade model accuracy and reliability. This shift causes models to make incorrect predictions because they encounter data that differs statistically from the training set, undermining generalization. Detecting and mitigating covariate shift is crucial to maintaining robust performance in real-world applications.
Mitigation Strategies for Covariate Shift and Data Drift
Mitigation strategies for covariate shift focus on reweighting training samples using importance weighting techniques to match the target distribution, alongside domain adaptation methods that adjust models to new feature distributions. Data drift mitigation involves continuous monitoring and retraining with recent data, incorporating techniques like online learning and adaptive algorithms to maintain model accuracy over time. Employing feature selection and robust model architectures further enhances resilience to shifts in data distribution and dynamic environments.
Best Practices for Managing and Preventing Data Distribution Changes
Effective management of covariate shift and data drift requires continuous monitoring of feature distribution using statistical tests such as Kolmogorov-Smirnov or population stability index to detect distributional changes promptly. Implementing real-time data validation pipelines and retraining machine learning models with updated datasets ensures robustness against evolving data patterns. Leveraging domain adaptation techniques and incorporating drift detection frameworks like ADWIN or DDM further aids in preventing performance degradation due to shifting data distributions.
Covariate Shift Infographic