Data lakes offer a scalable solution for storing vast amounts of raw, unstructured, and structured data in its native format, enabling flexible analytics and machine learning applications. By centralizing data from multiple sources, data lakes improve data accessibility and support advanced insights that drive business decisions. Explore the rest of this article to understand how leveraging a data lake can transform your data strategy.
Table of Comparison
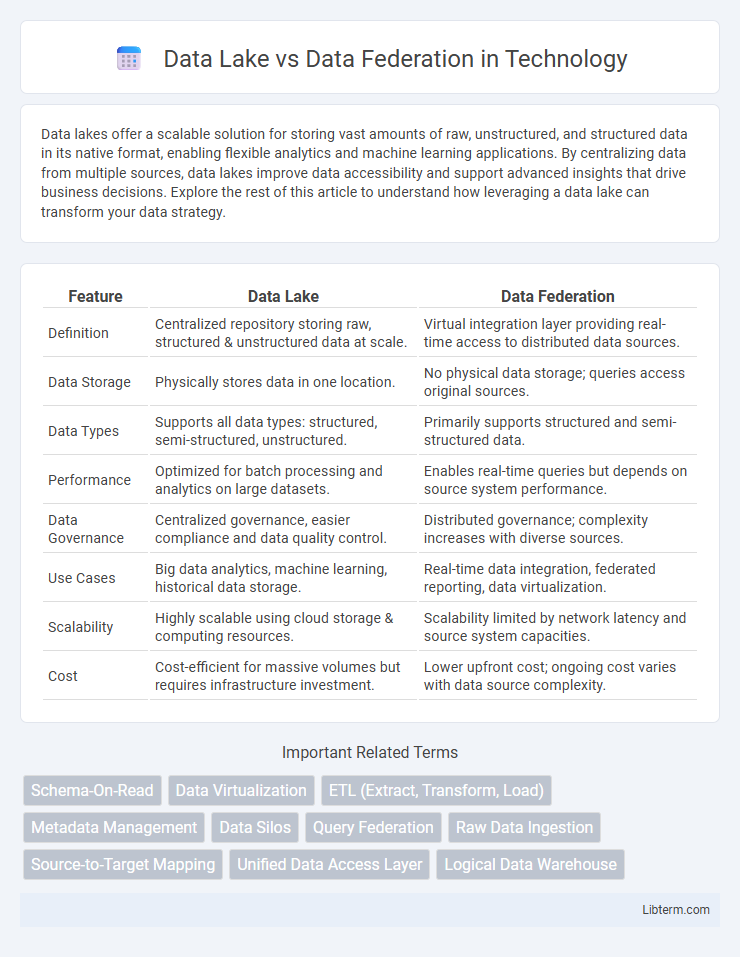
| Feature | Data Lake | Data Federation |
|---|---|---|
| Definition | Centralized repository storing raw, structured & unstructured data at scale. | Virtual integration layer providing real-time access to distributed data sources. |
| Data Storage | Physically stores data in one location. | No physical data storage; queries access original sources. |
| Data Types | Supports all data types: structured, semi-structured, unstructured. | Primarily supports structured and semi-structured data. |
| Performance | Optimized for batch processing and analytics on large datasets. | Enables real-time queries but depends on source system performance. |
| Data Governance | Centralized governance, easier compliance and data quality control. | Distributed governance; complexity increases with diverse sources. |
| Use Cases | Big data analytics, machine learning, historical data storage. | Real-time data integration, federated reporting, data virtualization. |
| Scalability | Highly scalable using cloud storage & computing resources. | Scalability limited by network latency and source system capacities. |
| Cost | Cost-efficient for massive volumes but requires infrastructure investment. | Lower upfront cost; ongoing cost varies with data source complexity. |
Introduction to Data Lake and Data Federation
Data Lake is a centralized repository that stores vast amounts of raw, unstructured, and structured data in its native format, enabling advanced analytics and machine learning. Data Federation integrates multiple disparate data sources into a virtual database, allowing real-time querying without physically moving the data. Both approaches address different needs for data management and accessibility in modern enterprises.
Core Concepts: What is a Data Lake?
A Data Lake is a centralized repository that stores vast amounts of raw, unstructured, and structured data at any scale, enabling organizations to retain data in its native format for future analysis. It supports data ingestion from diverse sources, providing flexible storage with schema-on-read capabilities that allow for versatile data exploration and processing. Data Lakes facilitate advanced analytics, machine learning, and business intelligence by consolidating heterogeneous data in a cost-effective, scalable environment.
Core Concepts: What is Data Federation?
Data Federation is a data integration approach that allows querying and accessing data from multiple heterogeneous sources without moving or copying the data into a centralized repository. It creates a virtual database layer that aggregates data in real-time, providing a unified view and enabling seamless data access for analytics and reporting. This contrasts with Data Lakes, which store large volumes of raw data in a centralized location for batch processing and advanced analytics.
Key Differences Between Data Lake and Data Federation
Data Lake stores large volumes of raw, unstructured, and structured data in a centralized repository, enabling comprehensive data analytics and machine learning. Data Federation, on the other hand, provides a virtual integration layer that allows real-time access and query across multiple heterogeneous data sources without data movement. Key differences include data storage versus virtual integration, latency in data access, and the complexity of data transformation processes.
Data Storage Architectures: Centralized vs Virtualized
Data Lake employs a centralized data storage architecture, consolidating massive volumes of raw data into a single repository optimized for high scalability and flexible schema-on-read processing. Data Federation, on the other hand, utilizes a virtualized data storage architecture that integrates and queries data in real-time across multiple distributed sources without physically moving data. Centralized data lakes offer optimized batch processing and advanced analytics, while virtualized federation enables agile access and unified views over heterogeneous data systems.
Use Cases for Data Lake
Data lakes serve as centralized repositories that store vast amounts of structured and unstructured data, making them ideal for big data analytics, machine learning, and real-time data processing use cases. Organizations leverage data lakes to integrate data from multiple sources in its raw form, enabling advanced data exploration, predictive modeling, and comprehensive historical analysis. This approach supports scalable storage and flexible access, which is critical for industries like finance, healthcare, and retail seeking deep insights from diverse and voluminous datasets.
Use Cases for Data Federation
Data Federation is ideal for use cases requiring real-time access to distributed data without physical data movement, such as querying multiple databases simultaneously to support dynamic reporting and decision-making. It benefits organizations with diverse data environments needing a unified view for analytics, enabling seamless integration across cloud, on-premises, and hybrid systems. Use cases include customer 360 views, regulatory compliance reporting, and operational BI, where timely, integrated data insight is crucial.
Integration and Scalability Considerations
Data Lake architectures centralize vast amounts of structured and unstructured data, enabling scalable storage and integrated analytics through schema-on-read approaches. Data Federation integrates data virtually from multiple heterogeneous sources in real-time without moving data, supporting agile query execution but often facing challenges in scalability with increasing data volume. Effective integration in Data Lakes relies on centralized storage and processing frameworks like Hadoop or cloud platforms, while Data Federation emphasizes seamless connectivity and query optimization across distributed databases for scalable, federated access.
Performance and Query Optimization
Data lake architecture enables high-performance analytics by centralizing vast amounts of raw data, supporting schema-on-read for flexible query optimization. Data federation optimizes query execution by dynamically integrating data from multiple heterogeneous sources without data movement, reducing latency for real-time access but may face bottlenecks in complex join operations. Performance in data lakes benefits from scalable storage and parallel processing frameworks like Apache Spark, while data federation relies heavily on source system capabilities and network bandwidth for query optimization.
Choosing the Right Approach: Data Lake or Data Federation
Choosing the right approach between Data Lake and Data Federation depends on the organization's data integration needs and infrastructure. Data Lakes are optimal for storing vast amounts of raw, unstructured data in a centralized repository, enabling large-scale analytics and machine learning. Data Federation suits environments requiring real-time access to diverse data sources without physical consolidation, offering agility and faster decision-making across distributed systems.
Data Lake Infographic