Precomputation enhances the efficiency of algorithms by calculating complex data or results in advance, reducing the need for repetitive processing during runtime. This approach is widely used in areas such as cryptography, game development, and data analysis to save time and resources. Explore the rest of the article to understand how precomputation can optimize your computational tasks.
Table of Comparison
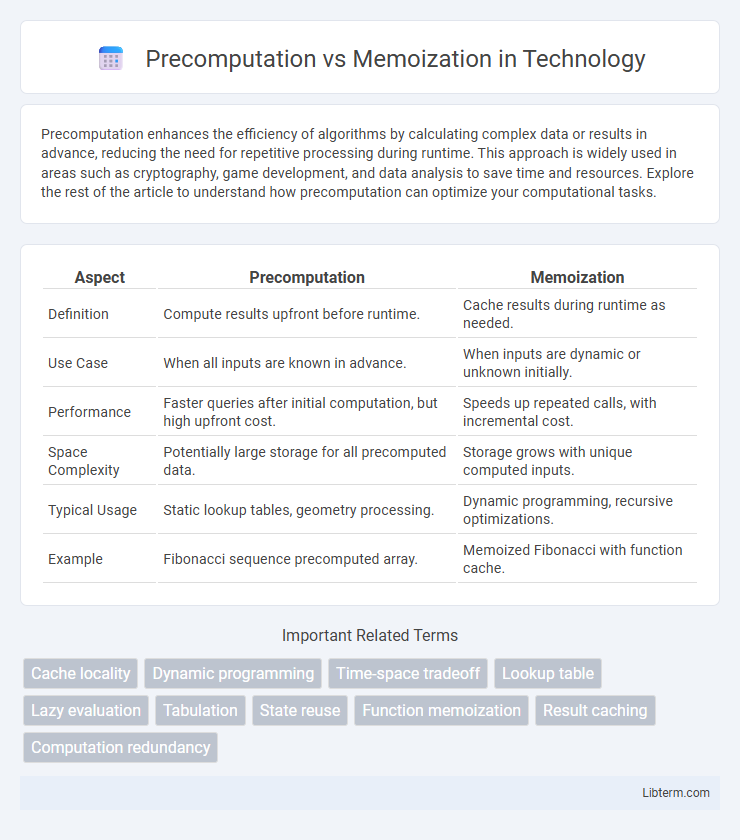
| Aspect | Precomputation | Memoization |
|---|---|---|
| Definition | Compute results upfront before runtime. | Cache results during runtime as needed. |
| Use Case | When all inputs are known in advance. | When inputs are dynamic or unknown initially. |
| Performance | Faster queries after initial computation, but high upfront cost. | Speeds up repeated calls, with incremental cost. |
| Space Complexity | Potentially large storage for all precomputed data. | Storage grows with unique computed inputs. |
| Typical Usage | Static lookup tables, geometry processing. | Dynamic programming, recursive optimizations. |
| Example | Fibonacci sequence precomputed array. | Memoized Fibonacci with function cache. |
Understanding Precomputation: Definition and Purpose
Precomputation refers to the process of calculating results or data before it is actually needed during the execution of an algorithm, aiming to reduce runtime complexity by trading off increased initial computation and memory usage. It is often used in dynamic programming and optimization problems where repeated calculations of identical subproblems occur, allowing the algorithm to retrieve precomputed values instantly rather than recalculating them multiple times. Precomputation enhances performance efficiency in scenarios involving static data or predictable queries, minimizing redundant computations.
What is Memoization? Core Concepts Explained
Memoization is an optimization technique used to speed up computer programs by storing the results of expensive function calls and reusing them when the same inputs occur again, reducing redundant calculations. It involves a cache, often implemented as a dictionary or hash table, that maps function arguments to their computed results, enabling constant-time lookup for repeated calls. This approach is particularly effective in recursive algorithms and dynamic programming, where overlapping subproblems make repeated computations costly.
Key Differences Between Precomputation and Memoization
Precomputation involves calculating all possible results before they are needed, enabling constant-time query responses, while memoization dynamically stores results during execution to avoid redundant computations. Precomputation requires more upfront processing and memory, whereas memoization optimizes performance gradually with input-dependent caching. The key difference lies in precomputation's eager calculation of entire solution spaces versus memoization's lazy, on-demand caching of partial solutions.
Performance Impact: When to Use Precomputation
Precomputation significantly improves performance when the problem involves repetitive queries over a fixed dataset, as it allows constant-time retrieval by storing all possible results in advance. It is most effective for problems with a predictable and limited input range, such as prefix sums or factorial tables, where the overhead of initial computation is offset by faster query times. Use precomputation when memory space is sufficient and query frequency is high, maximizing time efficiency at the cost of extra storage.
Memory Management in Precomputation vs Memoization
Precomputation allocates memory upfront by storing results of all possible inputs, which can lead to high initial memory usage but ensures constant-time access during execution. Memoization dynamically allocates memory only for computed inputs, optimizing memory consumption by caching necessary results and avoiding redundant calculations. Efficient memory management in precomputation requires balancing storage capacity with query speed, whereas memoization adapts memory usage based on runtime demand and input variability.
Common Use Cases: Precomputation Scenarios
Precomputation is commonly used in scenarios requiring rapid query responses, such as prefix sums for range queries, factorial tables for combinatorial computations, and sieve algorithms for prime number identification. It efficiently handles static datasets where repeated calculations can be replaced by a single upfront computation, improving overall runtime performance. This approach is prevalent in competitive programming, database indexing, and real-time analytics to reduce redundant processing overhead.
Typical Applications: Memoization in Practice
Memoization is essential in dynamic programming algorithms such as the Fibonacci sequence, where it avoids redundant calculations by storing previously computed values in a cache. It is widely used in recursive computations, like parsing algorithms and combinatorial problems, to enhance performance by returning precomputed results instantly. This technique optimizes time complexity significantly in problems with overlapping subproblems, making it a staple in real-world applications like game theory, artificial intelligence, and optimization tasks.
Advantages and Disadvantages of Precomputation
Precomputation improves performance by calculating and storing results in advance, enabling constant-time access during runtime and reducing redundant calculations for fixed input sets. However, it demands significant memory for storing precomputed values, which can be inefficient for large or dynamic datasets. Furthermore, precomputation lacks flexibility when input parameters change, leading to potential invalidation of stored data and increased recomputation overhead.
Pros and Cons of Memoization Techniques
Memoization enhances performance by storing and reusing previously computed results, significantly reducing redundant calculations in recursive algorithms such as Fibonacci sequence generation or dynamic programming problems. It requires additional memory to maintain a cache, which can lead to increased space complexity, especially in problems with large input domains. Memoization excels in scenarios with overlapping subproblems but may suffer from cache overhead and limited use in problems without repeated states.
Choosing the Right Approach: Precomputation or Memoization?
Choosing between precomputation and memoization depends on the problem's constraints and runtime requirements; precomputation is ideal for scenarios with predictable queries and sufficient memory, allowing all results to be computed upfront for constant-time access. Memoization suits problems with overlapping subproblems where computing all possibilities is expensive or unnecessary, optimizing performance by caching only the results of expensive function calls as needed. Evaluating the trade-offs in time complexity, space usage, and input size patterns ensures the selection of the most efficient optimization strategy.
Precomputation Infographic