Table indexing significantly enhances database query performance by enabling quicker data retrieval through efficient organization of table records. It reduces the search time for specific entries by maintaining sorted pointers, which is especially beneficial in large datasets where direct scanning is impractical. Explore the rest of this article to understand how implementing table indexing can optimize your database operations effectively.
Table of Comparison
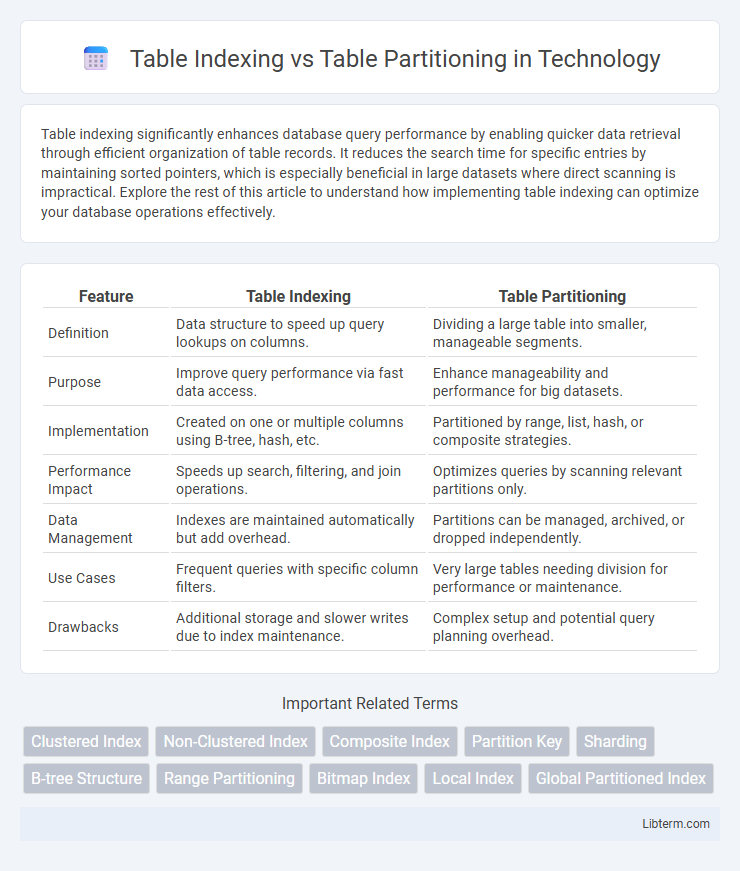
| Feature | Table Indexing | Table Partitioning |
|---|---|---|
| Definition | Data structure to speed up query lookups on columns. | Dividing a large table into smaller, manageable segments. |
| Purpose | Improve query performance via fast data access. | Enhance manageability and performance for big datasets. |
| Implementation | Created on one or multiple columns using B-tree, hash, etc. | Partitioned by range, list, hash, or composite strategies. |
| Performance Impact | Speeds up search, filtering, and join operations. | Optimizes queries by scanning relevant partitions only. |
| Data Management | Indexes are maintained automatically but add overhead. | Partitions can be managed, archived, or dropped independently. |
| Use Cases | Frequent queries with specific column filters. | Very large tables needing division for performance or maintenance. |
| Drawbacks | Additional storage and slower writes due to index maintenance. | Complex setup and potential query planning overhead. |
Introduction to Table Indexing and Partitioning
Table indexing improves database query performance by creating data structures that allow rapid access to rows based on key column values, reducing search time within large datasets. Table partitioning organizes a large table into smaller, manageable segments called partitions, typically based on a key such as date or region, which enhances query efficiency and maintenance operations. Both techniques optimize data retrieval but serve different purposes: indexing accelerates access to specific rows, while partitioning improves management and performance for large-scale tables.
Definition and Purpose of Table Indexing
Table indexing is a database optimization technique that creates data structures to improve the speed of data retrieval operations by allowing quick access to rows in a table. It functions like a pointer to specific data entries, minimizing the need to scan the entire table for queries. The primary purpose of table indexing is to enhance query performance, reduce search time, and support efficient sorting and filtering in large datasets.
What is Table Partitioning?
Table partitioning is a database management technique that divides a large table into smaller, manageable pieces called partitions based on specified criteria such as range, list, or hash. Each partition can be accessed, managed, and maintained independently, improving query performance and easing maintenance tasks like backups and archiving. Partitioning enhances scalability by allowing parallel processing and reducing I/O overhead during data retrieval.
Core Differences Between Indexing and Partitioning
Table indexing improves query performance by creating data structures like B-trees or hash indexes that allow fast data retrieval without scanning the entire table. Table partitioning divides large tables into smaller, manageable segments based on partition keys such as range, list, or hash, enhancing manageability and query efficiency on specific data subsets. Indexing optimizes search and retrieval operations, while partitioning optimizes data organization and maintenance for large-scale datasets.
Performance Impact: Indexing vs Partitioning
Table indexing improves query performance by enabling faster data retrieval through structured access paths like B-trees, significantly reducing search time for specific rows. Table partitioning enhances performance by dividing large tables into smaller, manageable segments, allowing queries to scan only relevant partitions, which reduces I/O and improves maintenance operations. While indexing speeds up point lookups and range queries, partitioning optimizes query execution on large datasets by limiting the data scanned, often providing better performance for bulk operations and large-scale analytics.
Use Cases: When to Use Indexing
Table indexing enhances query performance by enabling rapid data retrieval through structured lookup mechanisms, making it ideal for environments with frequent read operations and complex search conditions. Indexing is best suited for small to medium-sized tables where low-latency access is critical, such as online transaction processing (OLTP) systems or applications requiring quick filtering and sorting. It efficiently supports scenarios with selective queries on specific columns, reducing I/O overhead without restructuring the underlying data storage.
Use Cases: When to Use Partitioning
Table partitioning is ideal for managing large datasets where queries frequently target specific subsets of data, such as date ranges or geographic regions, enhancing query performance and maintenance efficiency. It is particularly beneficial in data warehousing, time-series analysis, and archiving scenarios where partition elimination reduces scan times and optimizes storage. Unlike table indexing, partitioning improves scalability by allowing operations like backup, restore, and data purging to be performed on individual partitions without affecting the entire table.
Maintenance and Management of Indexes and Partitions
Table indexing improves data retrieval speed by maintaining sorted pointers to rows, but index maintenance can become resource-intensive during frequent data modifications, requiring periodic rebuilds or reorganizations to optimize performance. Table partitioning divides large tables into smaller, manageable segments based on key values, simplifying maintenance tasks such as backups, archiving, and purging by targeting individual partitions without affecting the entire table. Both indexing and partitioning require careful monitoring of statistics and fragmentation levels to ensure efficient query processing and resource utilization in large-scale databases.
Best Practices for Combining Indexing and Partitioning
Combining table indexing and partitioning enhances query performance by aligning indexes with partition keys and ensuring local indexes on partitions rather than global indexes to minimize overhead. Best practices recommend creating partition-aligned indexes that match partition boundaries, enabling efficient pruning and faster data retrieval. Regularly monitoring index fragmentation and partition statistics helps optimize maintenance strategies and improve overall database responsiveness.
Choosing the Right Strategy for Your Database
Table indexing improves query performance by creating data pointers that speed up data retrieval for specific columns, ideal for frequently searched or filtered fields. Table partitioning divides a large table into smaller, manageable segments based on key ranges or lists, optimizing performance for massive datasets and improving maintenance tasks such as backups and archiving. Selecting between indexing and partitioning depends on query patterns, data volume, and maintenance needs, with indexing preferred for fast lookups and partitioning suited for large-scale data management and parallel processing.
Table Indexing Infographic