Data masking protects sensitive information by replacing original data with fictional but realistic values, ensuring privacy and security during testing or analysis. It prevents unauthorized access to confidential data while maintaining data integrity for operational purposes. Explore the article to learn how you can implement effective data masking strategies for your organization.
Table of Comparison
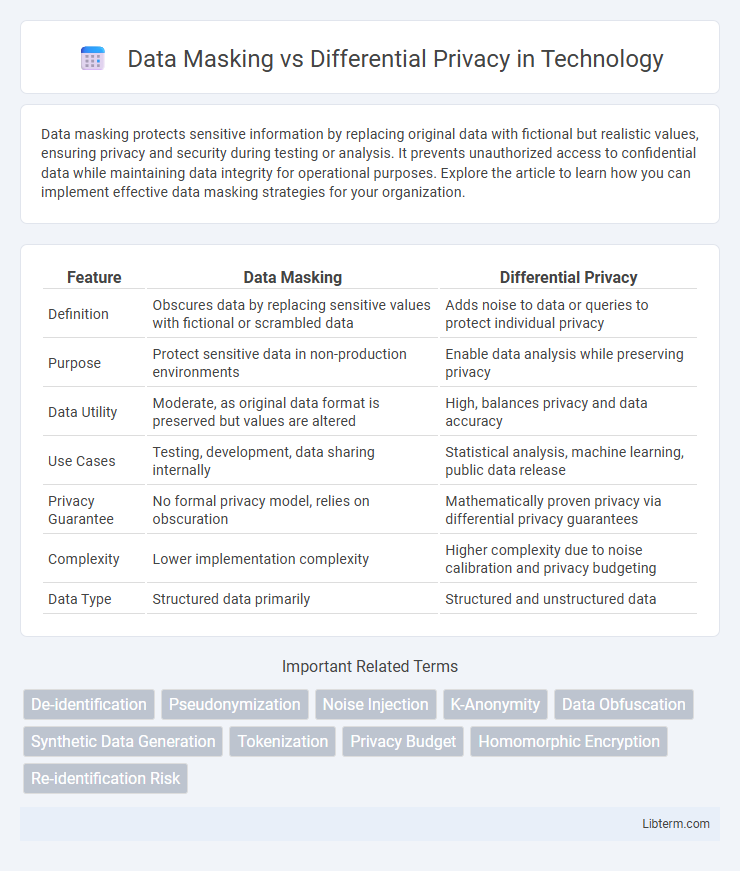
| Feature | Data Masking | Differential Privacy |
|---|---|---|
| Definition | Obscures data by replacing sensitive values with fictional or scrambled data | Adds noise to data or queries to protect individual privacy |
| Purpose | Protect sensitive data in non-production environments | Enable data analysis while preserving privacy |
| Data Utility | Moderate, as original data format is preserved but values are altered | High, balances privacy and data accuracy |
| Use Cases | Testing, development, data sharing internally | Statistical analysis, machine learning, public data release |
| Privacy Guarantee | No formal privacy model, relies on obscuration | Mathematically proven privacy via differential privacy guarantees |
| Complexity | Lower implementation complexity | Higher complexity due to noise calibration and privacy budgeting |
| Data Type | Structured data primarily | Structured and unstructured data |
Introduction to Data Privacy Techniques
Data masking transforms sensitive data by obfuscating or replacing original values to protect privacy during testing or analysis, ensuring unauthorized users cannot access real information. Differential privacy introduces carefully calibrated noise to datasets or query results, providing strong mathematical guarantees that individual data points remain indistinguishable, even under multiple analyses. Both techniques serve crucial roles in data privacy frameworks, with data masking emphasizing data utility preservation and differential privacy focusing on rigorous privacy guarantees.
What is Data Masking?
Data masking is a data protection technique that involves obscuring specific data elements to prevent unauthorized access while preserving the usability of the data for testing or analysis. Common methods include character substitution, shuffling, or encryption to replace original sensitive information with fictional but realistic data. This approach ensures compliance with privacy regulations by protecting personally identifiable information (PII) in non-production environments.
Understanding Differential Privacy
Differential privacy ensures data privacy by adding carefully calibrated noise to datasets, enabling statistical analysis while protecting individual entries from re-identification. Unlike data masking that obscures or alters specific data points, differential privacy provides mathematical guarantees about privacy loss even when multiple analyses are performed. This technique is widely adopted in large-scale data sharing scenarios, such as by technology companies and government agencies, to balance data utility with rigorous privacy protection.
Key Differences Between Data Masking and Differential Privacy
Data Masking replaces sensitive information with fictitious but realistic data to protect privacy during testing or analysis, while Differential Privacy introduces mathematical noise into datasets to provide formal privacy guarantees against re-identification. Data Masking is deterministic and often used for static data protection, whereas Differential Privacy offers probabilistic protection ideal for dynamic or aggregated data queries. The key difference lies in Data Masking's focus on data substitution versus Differential Privacy's focus on limiting information leakage through controlled randomness.
Use Cases for Data Masking
Data masking is primarily used in scenarios requiring the protection of sensitive information within non-production environments like software testing, user training, and data analytics, ensuring compliance with data privacy regulations such as GDPR and HIPAA. It allows organizations to create realistic but fictitious data sets that preserve the original format and structure, enabling developers and testers to work without exposing actual personal or sensitive data. Data masking is especially valuable in industries like finance, healthcare, and retail, where safeguarding customer data while maintaining usability for critical business processes is essential.
Applications of Differential Privacy
Differential privacy is widely applied in sectors such as healthcare, finance, and government to share aggregate data without exposing individual information. It enables data analysts to extract valuable insights while mathematically guaranteeing privacy, protecting against re-identification risks inherent in traditional data masking techniques. This makes differential privacy essential for large-scale data releases, like census statistics and user behavior analytics, where preserving data utility alongside privacy is critical.
Advantages and Limitations of Data Masking
Data masking enhances data security by replacing sensitive information with realistic but fictitious data, reducing the risk of exposure during development and testing processes. It enables compliance with privacy regulations by protecting personally identifiable information (PII) while maintaining data usability for analysis. However, data masking does not provide strong protection against sophisticated re-identification attacks and may reduce data utility for advanced analytics compared to differential privacy methods.
Pros and Cons of Differential Privacy
Differential privacy offers strong protection by injecting statistical noise into data queries, effectively preventing identification of individual records while allowing useful aggregate analysis. Its main advantage is rigorous mathematical guarantees of privacy, suitable for sensitive datasets in healthcare and finance. However, differential privacy can reduce data accuracy and requires careful calibration of privacy parameters, leading to potential trade-offs between data utility and privacy protection.
Choosing the Right Privacy Method for Your Data
Data masking and differential privacy serve distinct purposes in data protection, with data masking anonymizing sensitive information by obfuscating data elements, while differential privacy introduces statistical noise to datasets to preserve individual privacy in analytical results. Selecting the right privacy method depends on the use case: data masking is ideal for creating realistic datasets for testing or training without exposing real data, whereas differential privacy is suited for sharing aggregate data insights without compromising individual records. Organizations must evaluate the sensitivity of their data, compliance requirements, and intended data usage to determine whether masking or differential privacy best balances usability and privacy risks.
Future Trends in Data Privacy Technologies
Emerging trends in data privacy technologies emphasize the integration of data masking and differential privacy to enhance protection against sophisticated cyber threats. Advances in machine learning algorithms enable adaptive data masking techniques that dynamically obfuscate sensitive information while maintaining data utility. Differential privacy frameworks are evolving to support real-time data sharing with quantifiable privacy guarantees, facilitating secure analytics in sectors like healthcare and finance.
Data Masking Infographic