Bloom Filter is a space-efficient probabilistic data structure used to test whether an element is a member of a set with a possibility of false positives but no false negatives. It is highly effective for scenarios requiring fast membership checks with minimal memory usage, such as databases, caching, and network security. Discover how Bloom Filters optimize your data lookup processes and their practical applications in the rest of this article.
Table of Comparison
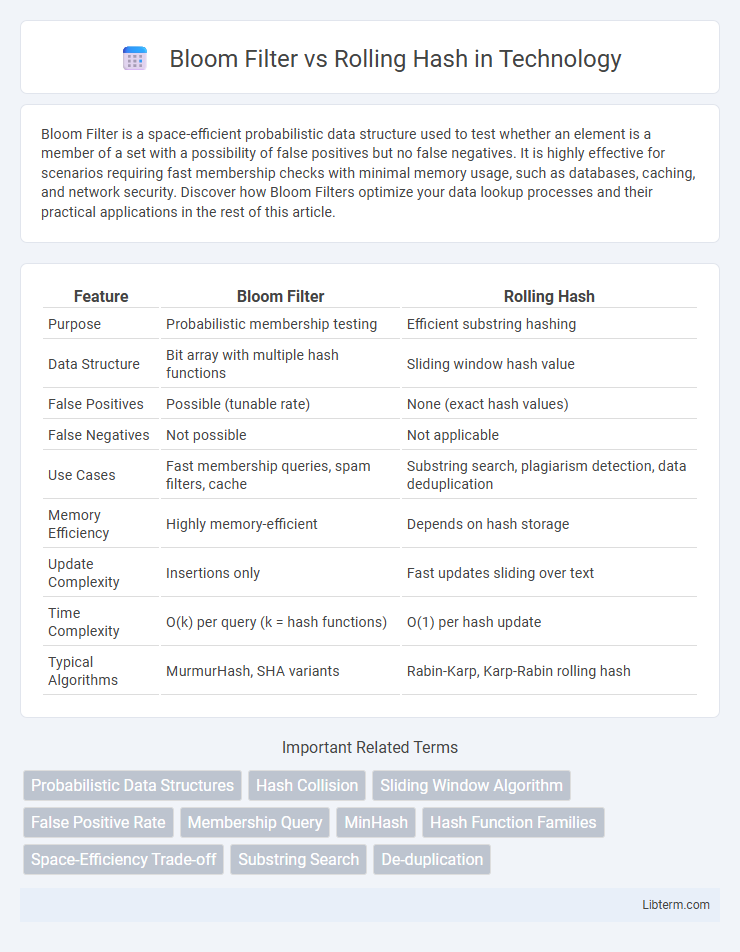
| Feature | Bloom Filter | Rolling Hash |
|---|---|---|
| Purpose | Probabilistic membership testing | Efficient substring hashing |
| Data Structure | Bit array with multiple hash functions | Sliding window hash value |
| False Positives | Possible (tunable rate) | None (exact hash values) |
| False Negatives | Not possible | Not applicable |
| Use Cases | Fast membership queries, spam filters, cache | Substring search, plagiarism detection, data deduplication |
| Memory Efficiency | Highly memory-efficient | Depends on hash storage |
| Update Complexity | Insertions only | Fast updates sliding over text |
| Time Complexity | O(k) per query (k = hash functions) | O(1) per hash update |
| Typical Algorithms | MurmurHash, SHA variants | Rabin-Karp, Karp-Rabin rolling hash |
Introduction to Bloom Filter and Rolling Hash
Bloom Filter is a space-efficient probabilistic data structure used to test whether an element is a member of a set, allowing false positives but no false negatives. Rolling Hash enables efficient computation of hash values for substrings by updating the hash value incrementally as the window slides over the input, commonly used in string matching algorithms like Rabin-Karp. Both techniques optimize performance in computational tasks involving large datasets and string searches, with Bloom Filter excelling in membership queries and Rolling Hash optimizing substring hashing operations.
Fundamental Concepts Explained
Bloom Filter is a probabilistic data structure designed for efficient set membership testing, utilizing multiple hash functions to map elements onto a bit array, allowing fast query responses with a controlled false positive rate. Rolling Hash is a hashing technique used primarily in string search algorithms, which computes hash values of substrings in constant time by updating the previous hash, enabling efficient pattern matching. Both methods leverage hashing but serve different purposes: Bloom Filters optimize space for membership queries, while Rolling Hashes optimize substring comparison speed.
How Bloom Filters Work
Bloom filters use multiple hash functions to map elements to a bit array, setting bits corresponding to each hashed position to 1 for every inserted item. During query operations, the filter checks these bits at all hashed positions to determine membership, providing a probabilistic answer with potential false positives but no false negatives. This space-efficient data structure is ideal for applications requiring fast set membership tests with minimal memory overhead.
How Rolling Hash Functions
Rolling hash functions generate hash values for substrings by efficiently updating the hash as the window slides over the input data, using a fixed-size window and a mathematical formula that incorporates the removal of the leading character and the addition of the new trailing character. This technique minimizes recomputation, making it ideal for algorithms like Rabin-Karp in pattern matching, where hash values are recalculated dynamically for overlapping segments. Unlike Bloom filters, rolling hashes focus on substring hashing with order preservation rather than probabilistic membership testing.
Key Differences Between Bloom Filter and Rolling Hash
Bloom Filters are probabilistic data structures used for membership testing that trade off false positives for space efficiency, while Rolling Hashes enable efficient substring hashing for string matching algorithms like Rabin-Karp. Bloom Filters utilize multiple hash functions to set bits in a fixed-size bit array, supporting constant-time membership queries with no false negatives; Rolling Hashes compute hash values incrementally to slide over text, optimizing continuous substring comparisons. Key differences include their core purpose--Bloom Filters for approximate membership checks versus Rolling Hashes for pattern detection--and their operational mechanisms, where Bloom Filters store compact bit arrays and Rolling Hashes maintain dynamic hash computations over sequences.
Common Use Cases and Applications
Bloom filters are widely used in database systems, network security, and cache filtering to efficiently test set membership with probabilistic guarantees, minimizing memory usage while allowing false positives. Rolling hashes serve essential roles in string matching algorithms like Rabin-Karp, data deduplication, and file synchronization by enabling fast, incremental hash computations over sliding windows of data. Both data structures optimize different stages of data processing; Bloom filters quickly eliminate unlikely candidates, whereas rolling hashes facilitate rapid pattern detection and integrity verification in streaming or large-scale data.
Performance Comparison and Efficiency
Bloom filters excel in space efficiency and fast membership queries with constant-time complexity, making them ideal for large-scale data sets where false positives are tolerable. Rolling hash algorithms provide efficient incremental hash computations suited for string matching and substring searching but generally require more processing time and memory than Bloom filters for membership tests. Performance-wise, Bloom filters outperform rolling hashes in speed and storage for probabilistic presence checks, while rolling hashes are preferred for accurate pattern detection with linear-time complexity.
Advantages and Disadvantages
Bloom filters offer fast membership queries with low memory usage by using multiple hash functions and bit arrays, making them highly efficient for probabilistic set membership tests. However, they suffer from false positives and cannot handle deletions easily, limiting their use in dynamic datasets. Rolling hash allows efficient recalculation of hash values for substrings, benefiting string matching algorithms, but it is vulnerable to hash collisions and generally requires more computational overhead than Bloom filters.
Choosing the Right Tool for Your Needs
Bloom Filters excel in efficiently testing membership with a low memory footprint and probabilistic false positives, making them ideal for large datasets where speed and space are critical. Rolling Hash algorithms enable fast substring search and fingerprinting by updating hashes incrementally, perfect for real-time pattern matching or duplicate detection in streams. Selecting between these tools depends on requirements: use Bloom Filters for approximate set membership and memory efficiency, while Rolling Hash suits scenarios needing exact or incremental string comparisons.
Conclusion and Future Prospects
Bloom Filters offer space-efficient probabilistic membership testing with false positive rates manageable through parameter tuning, while Rolling Hashes excel in efficient substring search and fingerprinting with deterministic outputs. Combining Bloom Filters with Rolling Hashes can enhance applications like duplicate detection and fast data synchronization by leveraging probabilistic filtering and fast content hashing. Future developments may focus on hybrid algorithms that optimize accuracy, speed, and memory usage across large-scale data streams and distributed systems.
Bloom Filter Infographic