Table denormalization enhances database performance by reducing the number of joins needed during query execution, which speeds up data retrieval processes. This technique involves intentionally introducing redundancy into your tables to simplify complex queries and improve read efficiency at the cost of some storage space. Discover how table denormalization can optimize your database management system as you read the rest of this article.
Table of Comparison
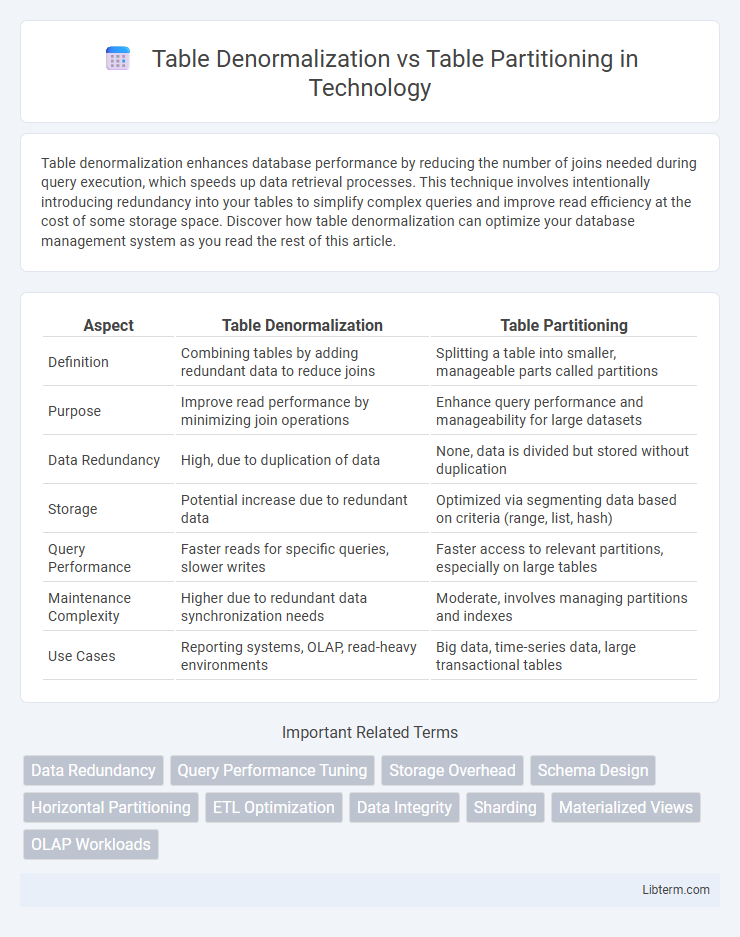
| Aspect | Table Denormalization | Table Partitioning |
|---|---|---|
| Definition | Combining tables by adding redundant data to reduce joins | Splitting a table into smaller, manageable parts called partitions |
| Purpose | Improve read performance by minimizing join operations | Enhance query performance and manageability for large datasets |
| Data Redundancy | High, due to duplication of data | None, data is divided but stored without duplication |
| Storage | Potential increase due to redundant data | Optimized via segmenting data based on criteria (range, list, hash) |
| Query Performance | Faster reads for specific queries, slower writes | Faster access to relevant partitions, especially on large tables |
| Maintenance Complexity | Higher due to redundant data synchronization needs | Moderate, involves managing partitions and indexes |
| Use Cases | Reporting systems, OLAP, read-heavy environments | Big data, time-series data, large transactional tables |
Introduction to Table Denormalization and Table Partitioning
Table denormalization involves intentionally introducing redundancy into a database table to improve query performance by reducing the number of joins required. Table partitioning divides a large table into smaller, more manageable pieces called partitions, based on a defined key, enhancing query speed and maintainability. Both techniques optimize database performance but address different challenges: denormalization targets query complexity, while partitioning manages data volume and access patterns.
Core Concepts: Denormalization Explained
Table denormalization involves intentionally introducing redundancy into a database schema to improve query performance by reducing the number of joins needed. It consolidates related data from multiple normalized tables into a single table, optimizing read operations at the cost of data duplication and potential update anomalies. This technique contrasts with partitioning, which divides data across multiple segments to enhance manageability and query speed without altering the schema's normalization level.
Core Concepts: Partitioning Explained
Table partitioning divides a large database table into smaller, more manageable segments based on key attributes such as range, list, or hash values, improving query performance and maintenance efficiency. Each partition acts as an independent unit that can be accessed or managed separately, allowing for faster data retrieval and optimized storage management. Partitioning supports large datasets by enhancing scalability and enabling parallel processing, which reduces I/O overhead during complex queries.
Key Differences Between Denormalization and Partitioning
Table denormalization involves merging tables or adding redundant data to reduce the number of joins and improve query performance, while table partitioning breaks a large table into smaller, more manageable pieces based on key column values for optimized data management. Denormalization typically enhances read performance at the expense of increased storage and potential data anomalies, whereas partitioning improves query efficiency and maintenance by enabling operations on individual partitions. Key differences include denormalization's focus on schema design changes to optimize access patterns versus partitioning's emphasis on physical data organization for scaling and manageability.
Performance Impact: Query Speed and Efficiency
Table denormalization improves query speed by reducing the need for complex joins, thus enhancing read performance in data-heavy applications. Table partitioning boosts efficiency by dividing large tables into smaller, manageable segments, allowing queries to scan relevant partitions only, which reduces I/O and execution time. Both techniques optimize performance differently: denormalization favors faster read access with possible data redundancy, while partitioning supports scalability and maintenance by improving query performance on large datasets.
Storage and Maintenance Considerations
Table denormalization reduces the number of joins by storing redundant data, which can increase storage requirements but simplifies query performance and maintenance by minimizing complex joins. Table partitioning divides a large table into smaller, manageable pieces based on key values, improving storage efficiency and maintenance by enabling targeted backups, faster deletions, and optimized query performance on partitions. While denormalization can increase storage usage and risk data anomalies, partitioning helps maintain data integrity and provides scalable maintenance without duplicating data.
Data Consistency and Integrity Issues
Table denormalization can improve query performance by reducing joins but often introduces data consistency and integrity challenges due to redundant data storage, increasing the risk of anomalies during updates or deletions. Table partitioning enhances manageability and query speed by dividing large tables into smaller, more manageable parts without duplicating data, thus maintaining strong data consistency and integrity. While denormalization may require complex application logic or triggers to ensure consistency, partitioning relies on database engine-level enforcement, reducing the likelihood of integrity violations.
Use Cases: When to Denormalize vs Partition
Table denormalization improves query performance in read-heavy workloads by duplicating data, making it ideal for reporting systems and OLAP environments where fast retrieval outweighs storage efficiency. Table partitioning enhances manageability and query speed in large, write-intensive datasets by dividing tables into smaller, manageable segments, suitable for time-series data, log management, and data warehousing scenarios. Choose denormalization when reducing complex joins is critical, while partitioning fits best when managing large volumes of data across discrete ranges or categories is essential.
Pros and Cons of Each Approach
Table denormalization improves query performance by reducing the number of joins and simplifying data retrieval, but it increases data redundancy and the risk of inconsistencies during updates. Table partitioning enhances manageability and query speed for large datasets by dividing tables into smaller, more manageable segments, yet it can complicate data maintenance and may require complex query optimization strategies. Choosing between denormalization and partitioning depends on specific use cases, such as prioritizing read performance or scalability versus data integrity and maintenance overhead.
Best Practices for Database Optimization
Table denormalization enhances read performance by reducing complex joins through redundant data storage, ideal for read-heavy workloads requiring fast query responses. Table partitioning improves manageability and query efficiency by dividing large tables into smaller, manageable segments based on specified keys, optimizing maintenance and parallel processing. Best practices recommend using denormalization selectively for critical read paths while leveraging partitioning to improve query performance and maintenance on large datasets.
Table Denormalization Infographic