Clustering is a powerful technique in data analysis that groups similar data points based on shared characteristics, enabling pattern recognition and insightful segmentation. It enhances your ability to uncover hidden structures within large datasets, making it essential for fields like marketing, image processing, and customer segmentation. Discover how clustering can transform your data-driven decisions by exploring the rest of this article.
Table of Comparison
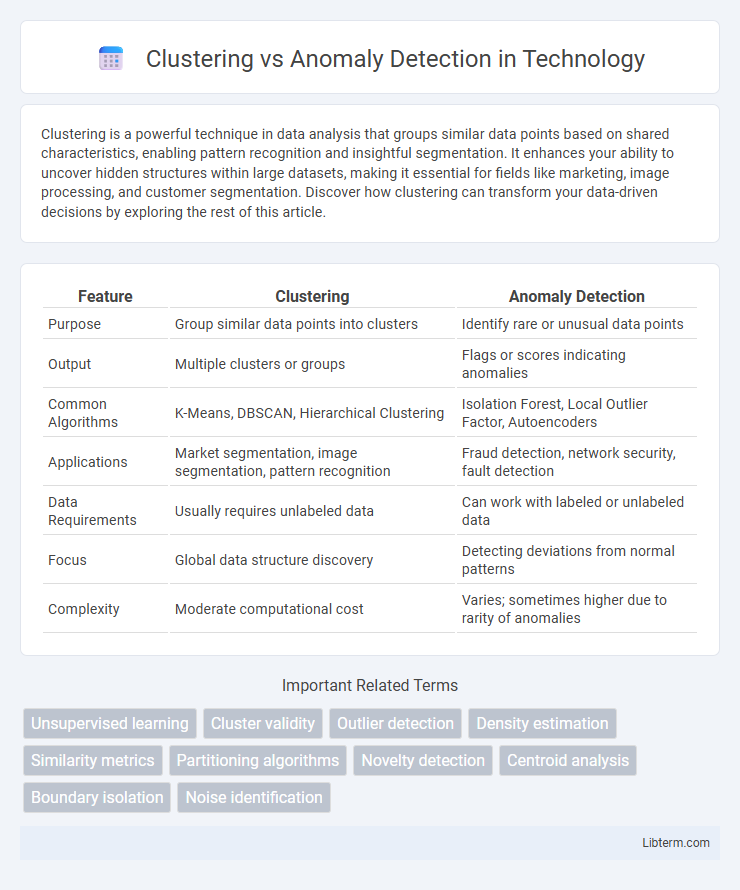
| Feature | Clustering | Anomaly Detection |
|---|---|---|
| Purpose | Group similar data points into clusters | Identify rare or unusual data points |
| Output | Multiple clusters or groups | Flags or scores indicating anomalies |
| Common Algorithms | K-Means, DBSCAN, Hierarchical Clustering | Isolation Forest, Local Outlier Factor, Autoencoders |
| Applications | Market segmentation, image segmentation, pattern recognition | Fraud detection, network security, fault detection |
| Data Requirements | Usually requires unlabeled data | Can work with labeled or unlabeled data |
| Focus | Global data structure discovery | Detecting deviations from normal patterns |
| Complexity | Moderate computational cost | Varies; sometimes higher due to rarity of anomalies |
Introduction to Clustering and Anomaly Detection
Clustering groups data points based on similarity, dividing datasets into distinct clusters that reveal underlying patterns or structures. Anomaly detection identifies data points that deviate significantly from the norm, pinpointing unusual or rare events within a dataset. Both techniques are essential in data analysis, with clustering aiding in pattern recognition and anomaly detection crucial for spotting irregularities or errors.
Defining Clustering: Key Concepts and Techniques
Clustering involves grouping data points into distinct clusters based on similarity metrics, enabling the identification of intrinsic structures within datasets without pre-labeled categories. Key techniques include K-means, hierarchical clustering, and DBSCAN, each leveraging different distance measures and density assumptions to segment data effectively. This unsupervised learning approach contrasts with anomaly detection, which focuses on identifying outliers rather than forming cohesive groups.
Understanding Anomaly Detection: Purpose and Methods
Anomaly detection aims to identify rare patterns or outliers that deviate significantly from normal behavior within datasets, serving critical roles in fraud detection, network security, and fault diagnosis. Common methods include statistical techniques, machine learning algorithms such as isolation forests, and deep learning models like autoencoders, which focus on distinguishing normal data distributions from anomalies. Unlike clustering that groups similar data points for pattern discovery, anomaly detection highlights unusual instances for further investigation and risk mitigation.
Similarities Between Clustering and Anomaly Detection
Clustering and anomaly detection both involve pattern recognition techniques used in unsupervised learning to analyze data structures and identify significant deviations. They aim to uncover inherent data groupings or outliers based on similarity measures, often leveraging distance metrics such as Euclidean or Manhattan distances. Both methods enhance data preprocessing and feature engineering tasks by organizing data into meaningful subsets or highlighting unusual observations for further analysis.
Core Differences: Clustering vs. Anomaly Detection
Clustering groups data points based on similarity to identify distinct patterns or segments within datasets, emphasizing the discovery of inherent structures. Anomaly detection focuses on identifying data points that deviate significantly from the established norms or clusters, highlighting rare or unusual instances. While clustering organizes data into coherent groups, anomaly detection isolates outliers that may indicate errors, fraud, or novel events.
Popular Algorithms in Clustering
K-means, DBSCAN, and hierarchical clustering rank among the most popular algorithms in clustering due to their efficiency in grouping data points based on similarity and density. K-means excels with large datasets by partitioning data into k distinct clusters using centroid vectors, while DBSCAN identifies clusters of varying shapes and sizes by detecting high-density regions, effectively handling noise and outliers. Hierarchical clustering builds nested clusters via a dendrogram, enabling flexible, granular cluster analysis adaptable to diverse applications in customer segmentation, image analysis, and bioinformatics.
Widely Used Techniques for Anomaly Detection
Widely used techniques for anomaly detection include statistical methods, density-based approaches, and machine learning algorithms such as Isolation Forest, One-Class SVM, and Autoencoders. These methods identify unusual data points by modeling normal behavior patterns and detecting deviations. In contrast, clustering techniques like K-Means or DBSCAN group similar data points but are less specialized for pinpointing anomalies.
Ideal Use Cases for Clustering
Clustering is ideal for segmenting large datasets into meaningful groups based on intrinsic patterns, such as customer segmentation in marketing, image segmentation in computer vision, and grouping similar documents for information retrieval. It excels in scenarios where the goal is to identify natural groupings without prior labels, enabling targeted strategies like personalized promotions or optimized resource allocation. Unlike anomaly detection, clustering focuses on understanding the overall data structure, making it suitable for exploratory data analysis and pattern discovery.
Practical Applications of Anomaly Detection
Anomaly detection is widely used in fraud detection, network security, and fault diagnosis, where identifying unusual patterns prevents significant risks and losses. Unlike clustering that groups similar data points, anomaly detection focuses on pinpointing rare, atypical events critical in monitoring systems and predictive maintenance. Practical applications include detecting credit card fraud, spotting cyber intrusions, and identifying equipment failures before they cause downtime.
Choosing the Right Approach: Factors and Recommendations
Selecting between clustering and anomaly detection depends on the primary goal: grouping similar data points or identifying rare, outlying events. Consider data characteristics, such as the presence of labeled anomalies, cluster density, and distribution patterns, to determine the method's suitability. For datasets with well-defined clusters, clustering algorithms like K-means or DBSCAN are recommended, whereas anomaly detection techniques like Isolation Forest or One-Class SVM excel in spotting uncommon deviations.
Clustering Infographic