Avro and Protobuf are powerful serialization frameworks designed to efficiently encode structured data for storage or transmission. Avro offers dynamic schemas and JSON-based schema definition, which simplify integration with big data tools like Apache Hadoop, while Protobuf provides compact, high-performance binary encoding with strong backward compatibility managed via .proto files. Explore the rest of this article to understand which serialization format best suits your data processing needs.
Table of Comparison
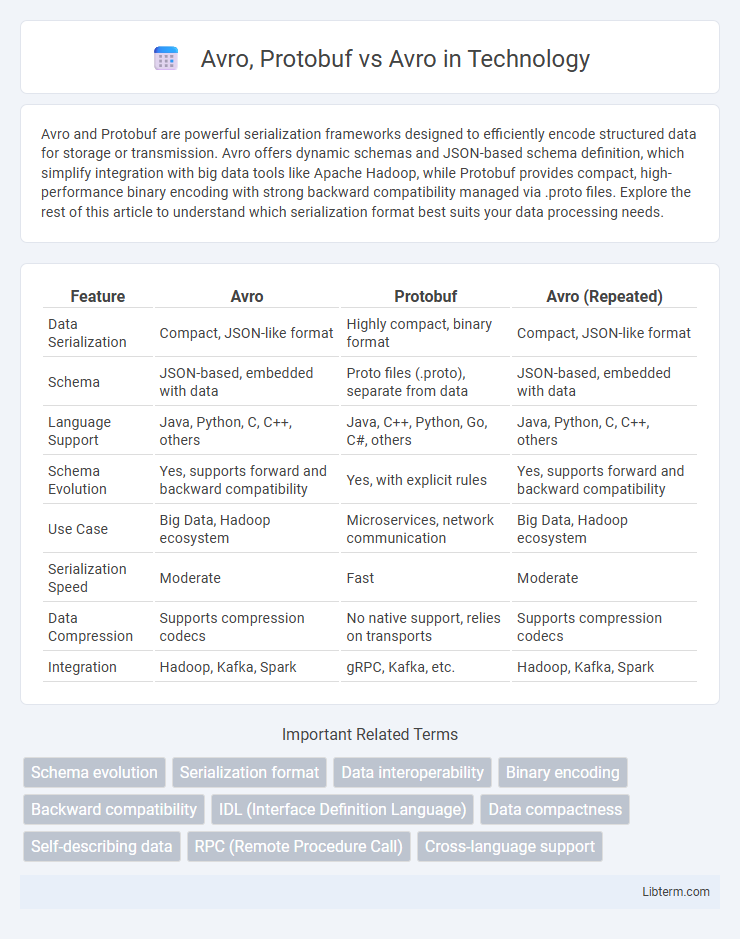
| Feature | Avro | Protobuf | Avro (Repeated) |
|---|---|---|---|
| Data Serialization | Compact, JSON-like format | Highly compact, binary format | Compact, JSON-like format |
| Schema | JSON-based, embedded with data | Proto files (.proto), separate from data | JSON-based, embedded with data |
| Language Support | Java, Python, C, C++, others | Java, C++, Python, Go, C#, others | Java, Python, C, C++, others |
| Schema Evolution | Yes, supports forward and backward compatibility | Yes, with explicit rules | Yes, supports forward and backward compatibility |
| Use Case | Big Data, Hadoop ecosystem | Microservices, network communication | Big Data, Hadoop ecosystem |
| Serialization Speed | Moderate | Fast | Moderate |
| Data Compression | Supports compression codecs | No native support, relies on transports | Supports compression codecs |
| Integration | Hadoop, Kafka, Spark | gRPC, Kafka, etc. | Hadoop, Kafka, Spark |
Introduction to Avro and Protobuf
Avro and Protobuf are popular serialization frameworks used for efficient data exchange in distributed systems. Avro, developed within the Apache Hadoop ecosystem, uses JSON-defined schemas and supports dynamic schema evolution, making it ideal for big data applications. Protobuf, created by Google, employs a compact binary format with a strictly defined schema, optimizing performance for low-latency communication and storage in microservices and mobile applications.
What is Avro?
Avro is a data serialization system developed within the Apache Hadoop project, designed for efficient, compact binary data encoding and schema evolution. It provides rich data structures, support for dynamic schemas, and integrates seamlessly with big data frameworks like Apache Kafka and Apache Spark. Unlike Protobuf, which requires precompiled schemas, Avro embeds schemas with the data, enabling robust schema negotiation and compatibility in distributed systems.
What is Protobuf?
Protobuf, short for Protocol Buffers, is a language-neutral, platform-neutral data serialization format developed by Google, designed for efficient and compact communication between services. Compared to Avro, Protobuf uses a predefined schema compiled into code for faster serialization and deserialization, which enhances performance in microservices and network communication. While Avro emphasizes schema evolution and dynamic typing through JSON encoding of schemas, Protobuf prioritizes lightweight binary encoding with rigid schema definitions for optimized speed and reduced bandwidth.
Core Features of Avro
Avro excels with its dynamic schema resolution and efficient binary serialization, enabling seamless data interchange across heterogeneous systems. Unlike Protobuf, Avro embeds schemas within the data file, ensuring schema evolution support without requiring code regeneration. Core features include compact serialization, JSON encoding options, and native support for rich data structures, making it ideal for big data and streaming applications.
Core Features of Protobuf
Protobuf offers compact binary serialization with efficient parsing, making it ideal for high-performance communication across distributed systems. It supports forward and backward compatibility through explicit schema evolution rules, enabling smooth message upgrades without breaking existing services. Key features include language-neutral support, robust data types, and autogenerated code, facilitating seamless integration across diverse platforms.
Schema Definition and Evolution
Avro uses JSON-based schema definitions that enable dynamic schema evolution with backward and forward compatibility, making it ideal for systems requiring flexible data formats. Protobuf relies on a compact, language-neutral binary schema defined in .proto files, offering efficient serialization but more rigid schema changes that may require explicit version management. While Avro supports schema evolution natively through embedded schemas and schema resolution, Protobuf demands careful planning for field additions or removals to maintain compatibility across versions.
Data Serialization Performance
Protobuf offers faster serialization and smaller message sizes compared to Avro, which is advantageous for high-performance applications processing large volumes of data. Avro excels in schema evolution and dynamic typing, allowing more flexible integration with big data frameworks like Apache Hadoop and Kafka. Benchmark tests indicate Protobuf typically achieves lower CPU usage and faster serialization speeds, while Avro's binary encoding provides good performance with enhanced schema resolution capabilities.
Compatibility and Ecosystem Support
Avro offers strong forward and backward compatibility with schema evolution, making it ideal for data pipelines where schemas change over time, while Protobuf provides robust backward compatibility but requires careful management for forward compatibility. Avro's integration with the Hadoop ecosystem and native support in Apache Kafka ensure extensive ecosystem support, whereas Protobuf benefits from broad language support and efficient serialization but has less direct integration with big data platforms. Choosing between Avro and Protobuf depends largely on the need for schema flexibility and the specific ecosystem requirements.
Use Cases: When to Choose Avro vs Protobuf
Avro excels in big data environments like Apache Hadoop and Kafka due to its seamless schema evolution and compact binary encoding, making it ideal for data serialization in distributed systems and streaming pipelines. Protobuf is preferred for communication between microservices and mobile applications where performance, smaller message sizes, and faster serialization are critical. Choose Avro when schema evolution and integration with Hadoop ecosystems are priorities, and Protobuf when you require efficient, strongly-typed data interchange across diverse platforms.
Conclusion: Avro or Protobuf?
Avro offers seamless integration with the Hadoop ecosystem and supports dynamic schemas, making it ideal for big data applications. Protobuf provides efficient serialization, compact message sizes, and broad language support, excelling in performance-critical and cross-platform environments. Choose Avro for schema evolution and data processing in analytics, while Protobuf suits real-time communication and lightweight data exchange.
Avro, Protobuf Infographic