Apache Spark is a powerful open-source distributed computing system designed for big data processing and analytics. It enables fast, in-memory data processing across large clusters, supporting diverse workloads such as batch processing, streaming, machine learning, and graph computation. Discover how Apache Spark can transform your data workflows by exploring the full article.
Table of Comparison
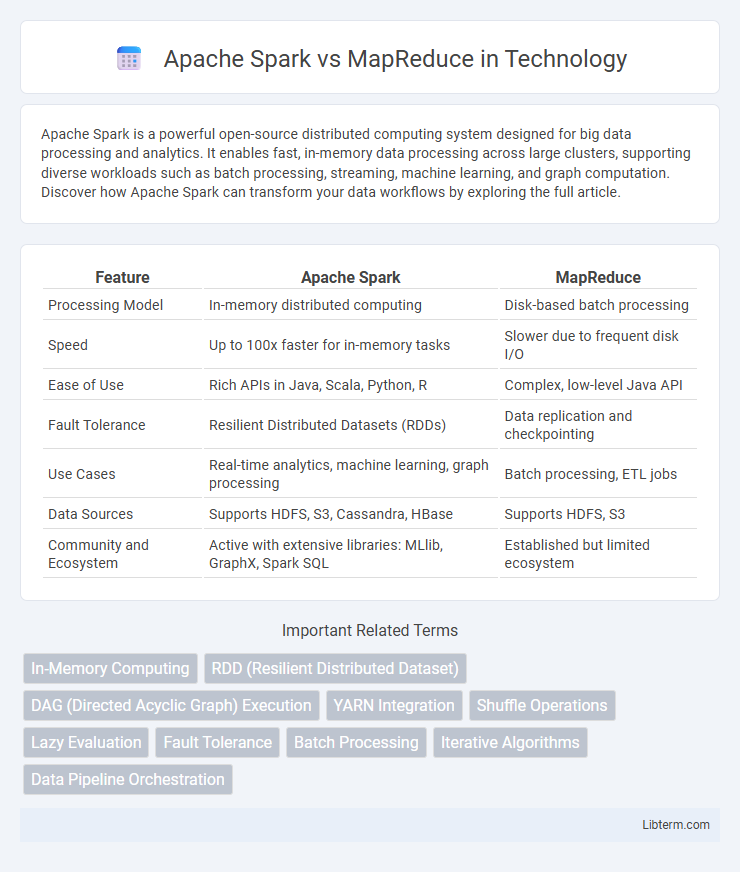
| Feature | Apache Spark | MapReduce |
|---|---|---|
| Processing Model | In-memory distributed computing | Disk-based batch processing |
| Speed | Up to 100x faster for in-memory tasks | Slower due to frequent disk I/O |
| Ease of Use | Rich APIs in Java, Scala, Python, R | Complex, low-level Java API |
| Fault Tolerance | Resilient Distributed Datasets (RDDs) | Data replication and checkpointing |
| Use Cases | Real-time analytics, machine learning, graph processing | Batch processing, ETL jobs |
| Data Sources | Supports HDFS, S3, Cassandra, HBase | Supports HDFS, S3 |
| Community and Ecosystem | Active with extensive libraries: MLlib, GraphX, Spark SQL | Established but limited ecosystem |
Introduction to Big Data Processing
Apache Spark and MapReduce are foundational frameworks in big data processing, designed to handle large-scale data analytics across distributed computing environments. Spark offers in-memory computation, leading to faster data processing compared to MapReduce's disk-based batch processing model. Both platforms support parallel data tasks, but Spark's advanced DAG execution engine and support for real-time analytics provide superior performance in complex data workflows.
Overview of Apache Spark
Apache Spark is a unified analytics engine designed for large-scale data processing, known for its in-memory computing capabilities that significantly enhance performance compared to traditional disk-based MapReduce. It supports diverse workloads, including batch processing, stream processing, machine learning, and graph processing, through a rich set of APIs in Java, Scala, Python, and R. Apache Spark's resilient distributed datasets (RDDs) offer fault tolerance and fault recovery, enabling efficient iterative algorithms and interactive data analysis.
Overview of MapReduce
MapReduce is a programming model designed for processing large data sets with a distributed algorithm on a cluster, breaking tasks into map and reduce functions to enable parallel processing. It emphasizes fault tolerance through data replication and task re-execution, making it suitable for batch processing in Hadoop ecosystems. Despite its robustness, MapReduce often incurs higher latency and less flexibility compared to in-memory processing frameworks like Apache Spark.
Architecture Differences
Apache Spark leverages an in-memory cluster computing architecture that processes data through Resilient Distributed Datasets (RDDs), enabling faster iterative computation compared to MapReduce's rigid disk-based data flow. Spark's Directed Acyclic Graph (DAG) execution engine optimizes task scheduling and fault tolerance, whereas MapReduce relies on a two-stage map and reduce model with intermediate data written to disk after each phase. This architectural difference results in Spark achieving significantly lower latency and improved performance for complex, multi-step data processing workflows compared to the batch-oriented MapReduce framework.
Data Processing Speed and Performance
Apache Spark outperforms MapReduce in data processing speed and performance due to its in-memory computing capabilities, which reduce disk I/O operations and enable faster task execution. Spark's DAG (Directed Acyclic Graph) execution engine optimizes task scheduling and allows for efficient iterative processing, making it ideal for complex and real-time analytics. In contrast, MapReduce relies heavily on disk-based storage between map and reduce phases, resulting in higher latency and slower performance for iterative and interactive workloads.
Ease of Programming and APIs
Apache Spark offers a more user-friendly programming model with high-level APIs in Java, Scala, Python, and R, supporting interactive data analysis and iterative algorithms efficiently. MapReduce requires writing complex Java code, focusing on batch processing without built-in support for iterative tasks, making development more time-consuming. Spark's in-memory processing and unified APIs accelerate debugging and application development compared to the low-level, disk-based MapReduce framework.
Fault Tolerance and Reliability
Apache Spark provides fault tolerance through lineage graphs that enable efficient data recovery by re-computing only lost partitions, resulting in faster failure recovery compared to MapReduce's replication-based approach. MapReduce achieves fault tolerance by replicating intermediate data on HDFS, which increases data reliability but incurs higher overhead and slower recovery times. Spark's in-memory processing combined with its DAG execution model enhances reliability by minimizing data loss risks and supporting automated task retries.
Use Cases and Applications
Apache Spark excels in iterative machine learning, real-time data processing, and interactive analytics due to its in-memory computing capabilities. MapReduce remains suitable for large-scale batch processing tasks such as ETL workflows, log analysis, and data warehousing where fault tolerance and scalability are critical. Spark's versatility supports graph processing and streaming applications, offering faster execution times compared to MapReduce's disk-based operations.
Scalability and Resource Management
Apache Spark offers superior scalability by utilizing in-memory processing, which significantly reduces I/O operations compared to MapReduce's disk-based storage approach. Spark's dynamic resource management and ability to optimize job execution through DAG (Directed Acyclic Graph) scheduling enhance performance on large-scale data clusters. In contrast, MapReduce relies on static resource allocation and slower batch processing, limiting its efficiency in handling iterative and interactive workloads at scale.
Choosing Between Apache Spark and MapReduce
Choosing between Apache Spark and MapReduce depends on specific data processing requirements and workload characteristics. Apache Spark offers faster in-memory processing suitable for iterative machine learning algorithms and real-time analytics, while MapReduce provides reliable, disk-based batch processing ideal for large-scale ETL tasks in Hadoop ecosystems. Evaluating factors such as latency tolerance, fault tolerance, and ecosystem integration helps determine the most efficient framework for big data projects.
Apache Spark Infographic