Data Mesh revolutionizes data management by decentralizing ownership and promoting domain-oriented data teams, which enhances scalability and agility in handling large datasets. It empowers your organization to treat data as a product, improving quality and accessibility across departments. Discover how adopting Data Mesh can transform your data strategy by reading the full article.
Table of Comparison
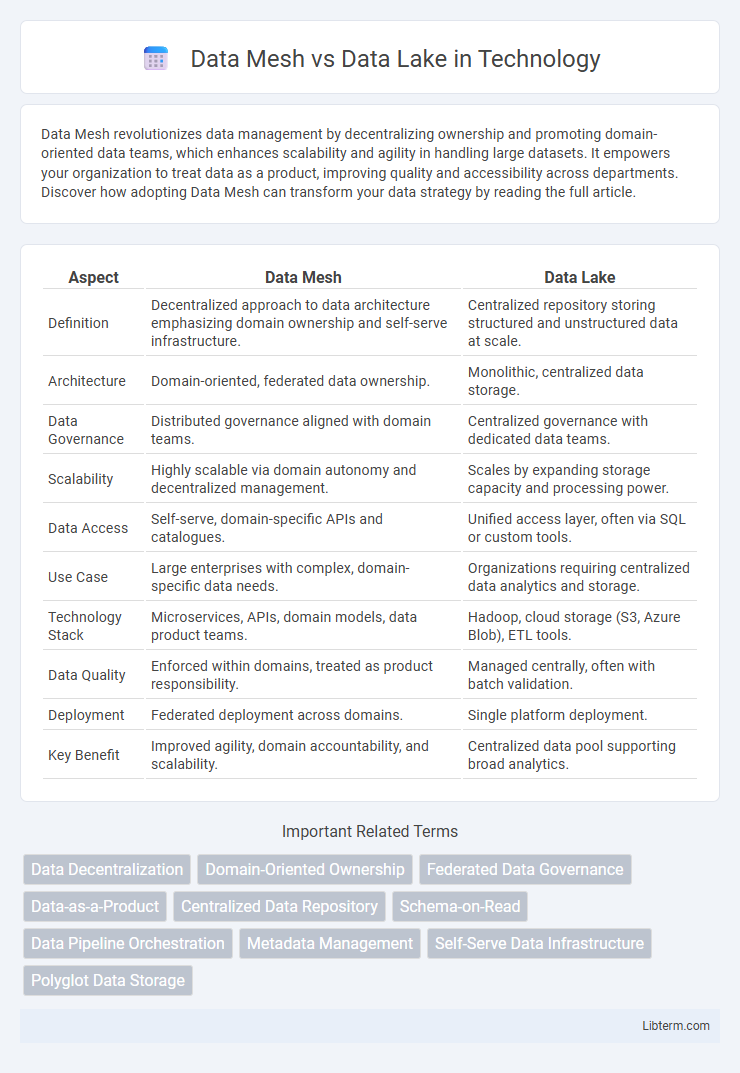
| Aspect | Data Mesh | Data Lake |
|---|---|---|
| Definition | Decentralized approach to data architecture emphasizing domain ownership and self-serve infrastructure. | Centralized repository storing structured and unstructured data at scale. |
| Architecture | Domain-oriented, federated data ownership. | Monolithic, centralized data storage. |
| Data Governance | Distributed governance aligned with domain teams. | Centralized governance with dedicated data teams. |
| Scalability | Highly scalable via domain autonomy and decentralized management. | Scales by expanding storage capacity and processing power. |
| Data Access | Self-serve, domain-specific APIs and catalogues. | Unified access layer, often via SQL or custom tools. |
| Use Case | Large enterprises with complex, domain-specific data needs. | Organizations requiring centralized data analytics and storage. |
| Technology Stack | Microservices, APIs, domain models, data product teams. | Hadoop, cloud storage (S3, Azure Blob), ETL tools. |
| Data Quality | Enforced within domains, treated as product responsibility. | Managed centrally, often with batch validation. |
| Deployment | Federated deployment across domains. | Single platform deployment. |
| Key Benefit | Improved agility, domain accountability, and scalability. | Centralized data pool supporting broad analytics. |
Introduction to Data Mesh and Data Lake
Data Mesh is a decentralized data architecture that treats data as a product, emphasizing domain ownership and self-serve data infrastructure to enhance scalability and agility. Data Lake is a centralized repository that stores vast amounts of raw data in its native format, enabling diverse analytics and machine learning applications. Both approaches address large-scale data management but differ in governance, data accessibility, and organizational alignment.
Core Principles of Data Mesh
Data Mesh emphasizes decentralized data ownership, treating data as a product managed by autonomous domain teams, unlike Data Lake's centralized storage approach. It promotes a self-serve data infrastructure platform and enforces data governance through federated computational governance to ensure data quality and compliance. This architecture addresses scalability and agility challenges by aligning data management with organizational domains.
Fundamental Concepts of Data Lake
Data Lake is a centralized repository that stores vast amounts of raw, unstructured, and structured data in its native format, enabling flexible data ingestion and schema-on-read capabilities. It supports diverse analytics by allowing users to run different types of queries and machine learning models without predefined schemas. The fundamental concept revolves around scalability, cost-efficiency, and the capacity to handle high volumes of big data from multiple sources in a single, unified platform.
Data Architecture Comparison
Data Mesh emphasizes decentralized data ownership and domain-oriented architecture, enabling teams to manage data as a product with clear governance and interoperability standards. Data Lake relies on a centralized repository architecture, storing vast amounts of raw data from various sources in a single system for analytics and processing. The Data Mesh architecture promotes scalability and agility through distributed data domains, while Data Lake architecture focuses on consolidation and large-scale data storage.
Scalability and Flexibility Differences
Data Mesh architecture enhances scalability by decentralizing data ownership across domain teams, enabling independent data product development and faster scaling with minimal bottlenecks. In contrast, Data Lake centralizes large volumes of raw data, which can create scalability challenges due to increased data management complexity and slower processing times. Flexibility in Data Mesh stems from its domain-oriented, self-serve infrastructure allowing tailored data solutions, whereas Data Lake offers flexibility through a unified storage platform but often requires complex ETL pipelines to access and transform data.
Data Governance and Ownership
Data Mesh emphasizes decentralized data governance and ownership by assigning accountability to domain teams, enabling faster decision-making and tailored compliance. Data Lake governance typically relies on a centralized model, which can create bottlenecks and reduce responsiveness to domain-specific needs. With Data Mesh, ownership of data products is embedded within the domain, promoting clearer data stewardship and enhancing data quality across the organization.
Use Cases and Business Applications
Data Mesh architecture excels in decentralized, large-scale enterprises requiring domain-oriented ownership and real-time data accessibility for agile decision-making, ideal for businesses with complex, distributed teams such as multinational corporations or digital platforms. Data Lake is suited for organizations needing centralized storage of vast, diverse data types for comprehensive analytics, making it valuable in scenarios like big data analytics, machine learning model training, and batch processing in industries such as finance or healthcare. Both approaches support data-driven strategies but differ where Data Mesh enhances scalability and domain-specific agility, Data Lake emphasizes centralized data consolidation and deep analytical capabilities.
Pros and Cons of Data Mesh
Data Mesh offers a decentralized data architecture promoting domain-oriented ownership, enhancing data agility and scalability compared to traditional Data Lakes. It improves data quality through closer alignment with business units but requires significant cultural shifts and governance maturity to implement effectively. Challenges include increased complexity in coordination and potential inconsistencies across distributed data products without robust standards.
Advantages and Limitations of Data Lake
Data Lakes offer scalable storage for vast amounts of raw data, enabling diverse analytics and machine learning applications with flexible schema-on-read processing. Their centralized architecture supports a unified data repository but often leads to data governance challenges, complex metadata management, and potential data quality issues. Limited control over data access and slower query performance compared to structured systems highlight key limitations of Data Lakes in enterprise environments.
Choosing the Right Approach for Your Organization
Choosing between Data Mesh and Data Lake depends on your organization's scale, data complexity, and governance needs. Data Mesh emphasizes decentralized ownership and domain-oriented data architecture, ideal for large enterprises with diverse teams requiring autonomous data ownership. In contrast, Data Lake offers a centralized repository suited for organizations prioritizing unified data storage and batch processing, making it essential to align with your operational goals and team structure.
Data Mesh Infographic