Data anonymization protects sensitive information by transforming personal identifiers into non-identifiable formats, ensuring privacy compliance and reducing risks of data breaches. This technique enables organizations to securely share datasets for analysis without compromising individual confidentiality. Discover how mastering data anonymization can enhance Your data security and regulatory adherence throughout the rest of this article.
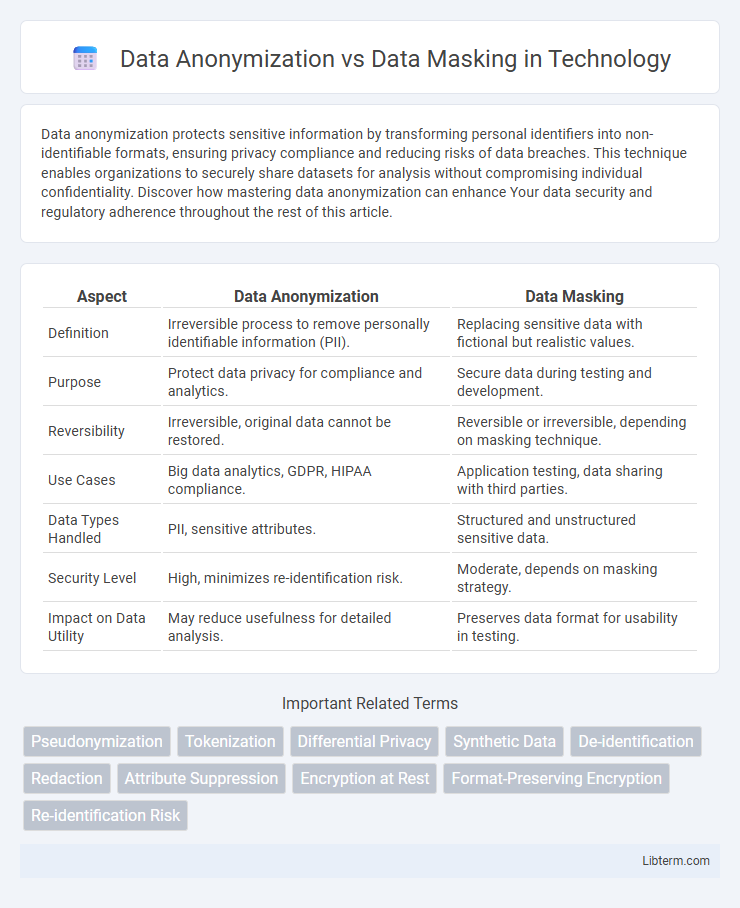
Table of Comparison
| Aspect | Data Anonymization | Data Masking |
|---|---|---|
| Definition | Irreversible process to remove personally identifiable information (PII). | Replacing sensitive data with fictional but realistic values. |
| Purpose | Protect data privacy for compliance and analytics. | Secure data during testing and development. |
| Reversibility | Irreversible, original data cannot be restored. | Reversible or irreversible, depending on masking technique. |
| Use Cases | Big data analytics, GDPR, HIPAA compliance. | Application testing, data sharing with third parties. |
| Data Types Handled | PII, sensitive attributes. | Structured and unstructured sensitive data. |
| Security Level | High, minimizes re-identification risk. | Moderate, depends on masking strategy. |
| Impact on Data Utility | May reduce usefulness for detailed analysis. | Preserves data format for usability in testing. |
Introduction to Data Anonymization and Data Masking
Data anonymization transforms personal data into a form that prevents identification, ensuring compliance with privacy regulations like GDPR and HIPAA. Data masking obscures sensitive information by replacing it with fictitious but realistic values, enabling safe data use in non-production environments. Both techniques protect data privacy but differ in purpose and reversibility: anonymization is irreversible, while masking often allows controlled data restoration.
Defining Data Anonymization
Data anonymization involves transforming personal data into a form that prevents identification of the data subject, ensuring privacy through irreversible processes such as encryption, hashing, or generalization. Unlike data masking, which obscures data elements but retains their format and usability primarily for testing or development, anonymization eliminates any possibility of tracing information back to an individual. This technique complies with regulations like GDPR and HIPAA by protecting sensitive information while enabling data analytics and sharing.
Understanding Data Masking
Data masking transforms sensitive data into a non-sensitive format by replacing original values with realistic but fictional data, ensuring confidentiality during development, testing, or external sharing. It preserves data usability for analysis while preventing unauthorized access to personally identifiable information (PII) or financial records. This technique supports compliance with data protection regulations such as GDPR and HIPAA by mitigating risks associated with data exposure.
Key Differences Between Data Anonymization and Data Masking
Data anonymization permanently removes or alters personally identifiable information (PII) to prevent re-identification, ensuring compliance with privacy regulations like GDPR and HIPAA. Data masking involves obscuring sensitive data by substituting or encrypting the data fields, allowing functional use in non-production environments without exposing real data. Key differences include anonymization's irreversible process aimed at protecting privacy, versus masking's reversible or non-permanent changes designed for secure testing and user training.
Use Cases for Data Anonymization
Data anonymization is primarily used in scenarios requiring privacy protection while enabling data analysis, such as sharing datasets for research, compliance with regulations like GDPR and HIPAA, and publishing public health statistics. It allows organizations to remove personally identifiable information (PII) to prevent re-identification of individuals in big data analytics and machine learning applications. This technique is essential for maintaining data utility in environments where sensitive data must be protected but insights must still be extracted.
Use Cases for Data Masking
Data masking is primarily utilized in non-production environments such as software testing, user training, and development to safeguard sensitive information while maintaining data usability. It enables organizations to comply with data privacy regulations like GDPR and HIPAA by obscuring personally identifiable information (PII) without altering the original data structure. Common use cases include protecting customer data in test databases, securing employee records during training sessions, and facilitating analytics on masked datasets without risking data exposure.
Advantages of Data Anonymization
Data anonymization offers strong privacy protection by irreversibly removing personally identifiable information, enabling organizations to share and analyze data without risking individual privacy breaches. It supports regulatory compliance with laws such as GDPR and HIPAA by ensuring that anonymized data falls outside the scope of personal data regulations. Unlike data masking, which merely obfuscates information while retaining identifiable data underlying it, anonymization provides a higher level of security suitable for public data releases and advanced analytics.
Benefits of Data Masking
Data masking enhances data security by replacing sensitive information with realistic but fictitious data, reducing the risk of exposure during testing or analysis. It ensures compliance with data privacy regulations such as GDPR and HIPAA by preventing unauthorized access to personally identifiable information (PII). Organizations benefit from minimized data breach risks and maintained data utility for non-production environments while protecting customer trust.
Challenges and Limitations
Data anonymization faces challenges in balancing data utility with privacy protection, often resulting in reduced data accuracy for analysis due to irreversible transformation. Data masking limitations include maintaining data referential integrity across systems while protecting sensitive information, posing difficulties in dynamic data environments where real-time data updates occur. Both techniques struggle with evolving regulatory compliance requirements and the risk of re-identification through advanced analytics or cross-referencing with external datasets.
Choosing the Right Approach for Data Protection
Data anonymization permanently removes or alters personally identifiable information (PII) to prevent re-identification, ideal for compliance with GDPR and long-term data privacy. Data masking obscures sensitive data with fictional values for safe use in testing or development environments without impacting real data integrity. Choosing the right approach hinges on whether data needs to retain analytical value or simply require protection against unauthorized access during operational use.
Data Anonymization Infographic