Data lakes provide a flexible and scalable solution for storing vast amounts of structured and unstructured data in its raw form, enabling organizations to derive deeper insights through advanced analytics and machine learning. They support diverse data types and rapid data ingestion while maintaining low storage costs, making them ideal for big data strategies. Explore the rest of this article to learn how data lakes can transform your data management and analytics capabilities.
Table of Comparison
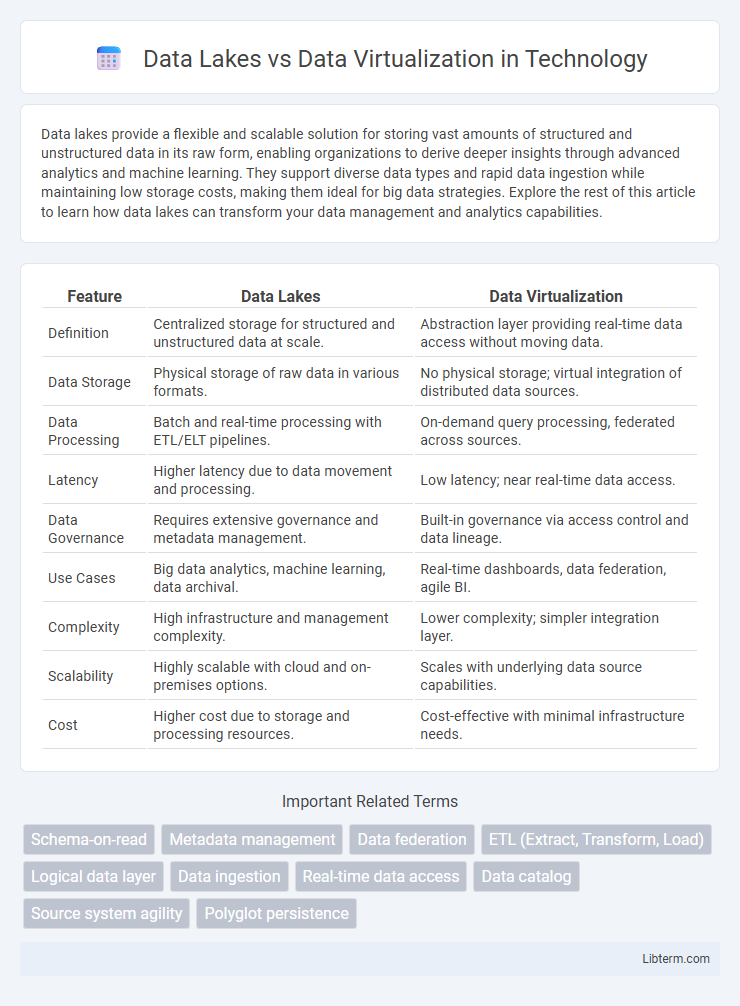
| Feature | Data Lakes | Data Virtualization |
|---|---|---|
| Definition | Centralized storage for structured and unstructured data at scale. | Abstraction layer providing real-time data access without moving data. |
| Data Storage | Physical storage of raw data in various formats. | No physical storage; virtual integration of distributed data sources. |
| Data Processing | Batch and real-time processing with ETL/ELT pipelines. | On-demand query processing, federated across sources. |
| Latency | Higher latency due to data movement and processing. | Low latency; near real-time data access. |
| Data Governance | Requires extensive governance and metadata management. | Built-in governance via access control and data lineage. |
| Use Cases | Big data analytics, machine learning, data archival. | Real-time dashboards, data federation, agile BI. |
| Complexity | High infrastructure and management complexity. | Lower complexity; simpler integration layer. |
| Scalability | Highly scalable with cloud and on-premises options. | Scales with underlying data source capabilities. |
| Cost | Higher cost due to storage and processing resources. | Cost-effective with minimal infrastructure needs. |
Understanding Data Lakes: Core Concepts
Data lakes are centralized repositories that store vast amounts of raw, unstructured, and structured data in its native format, enabling scalable storage and flexible data processing. They support schema-on-read, allowing users to define data structures at the time of analysis, which enhances agility compared to traditional data warehouses. Core concepts include metadata management, data ingestion pipelines, and distributed storage frameworks like Hadoop and cloud-based platforms such as AWS S3 and Azure Data Lake Storage.
What Is Data Virtualization? Key Principles
Data virtualization is a data management approach that allows users to access and manipulate data across multiple sources without moving or copying it, providing real-time integration through a virtual data layer. Key principles include data abstraction, which hides the complexity of disparate data sources; on-demand data access enabling real-time query responses; and centralized data governance ensuring consistent security and compliance across the virtualized environment. This approach contrasts with data lakes by emphasizing agility, reduced data redundancy, and immediate data availability without the need for large-scale storage consolidation.
Architecture Comparison: Data Lakes vs Data Virtualization
Data Lakes utilize a centralized architecture storing raw data in its native format across various structured and unstructured sources, allowing scalable storage and schema-on-read flexibility. Data Virtualization employs a distributed architecture that integrates data from multiple sources in real-time without physical movement, providing a unified, abstracted data layer for instant access. This architectural distinction highlights Data Lakes' emphasis on comprehensive, persistent storage versus Data Virtualization's focus on agility and real-time data integration.
Data Ingestion and Integration Workflows
Data lakes enable large-scale data ingestion by storing raw, unstructured, and structured data from diverse sources in a centralized repository, allowing batch or real-time processing workflows for integration. In contrast, data virtualization creates a unified, virtual data layer without physical movement, integrating data on-demand from multiple heterogeneous sources through real-time query execution and metadata abstraction. While data lakes emphasize offline ingestion and transformation pipelines, data virtualization prioritizes agility and low-latency access by abstracting complex integration workflows into virtual views.
Performance and Scalability Considerations
Data lakes offer high scalability by storing vast amounts of raw data in native formats, enabling efficient batch processing for analytics and machine learning workloads. Data virtualization provides superior performance for real-time data access by integrating multiple data sources without duplication, but may face limitations in handling extremely large datasets or complex transformations. Choosing between the two depends on workload requirements, with data lakes excelling in large-scale storage and batch analysis, while data virtualization favors agile, low-latency queries across distributed systems.
Data Governance and Security in Both Approaches
Data Lakes offer centralized storage that simplifies data governance through consistent policy enforcement and role-based access controls across vast, diverse datasets. Data Virtualization enables secure, real-time data access without replication, enforcing governance by controlling user permissions and data masking at the query layer. Both approaches require robust encryption, auditing, and compliance mechanisms to maintain data security and meet regulatory standards.
Use Cases: When to Use Data Lakes
Data lakes excel in scenarios requiring large-scale storage of diverse, raw data types from multiple sources for future analysis or machine learning projects. They are ideal when organizations need to retain data in its native format to support data science, advanced analytics, or historical data storage. Use cases include big data analytics, Internet of Things (IoT) data aggregation, and long-term archival storage where flexible schema design and scalability are critical.
Use Cases: When Data Virtualization Excels
Data virtualization excels in use cases requiring real-time data access and integration from multiple, heterogeneous sources without physical data replication. It is ideal for agile business intelligence, self-service analytics, and scenarios demanding rapid data provisioning with minimal infrastructure overhead. Enterprises benefit when prioritizing data consistency, low-latency query performance, and seamless integration across cloud and on-premises environments.
Challenges and Limitations of Each Solution
Data lakes face challenges such as data quality management, complex data governance, and high storage costs due to the vast volumes of raw data stored without predefined schemas. Data virtualization struggles with performance issues when querying large, diverse data sources in real-time and may encounter limitations in handling complex transformations or unstructured data. Both approaches require careful consideration of scalability, security, and integration complexity to effectively support enterprise analytics needs.
Choosing the Right Approach for Your Organization
Data lakes provide scalable, centralized storage for vast amounts of raw data, ideal for organizations requiring extensive historical analysis and machine learning capabilities. Data virtualization offers real-time integration and access to dispersed data sources without replication, enabling faster decision-making and reduced infrastructure costs. Choosing the right approach depends on factors such as data volume, latency requirements, budget constraints, and the complexity of data governance within your organization.
Data Lakes Infographic