ETL (Extract, Transform, Load) is a critical process in data warehousing that enables the movement and transformation of data from diverse sources into a centralized repository for analysis. This process ensures data consistency, quality, and accessibility, empowering Your organization to make informed decisions based on reliable information. Explore the rest of the article to understand how ETL can optimize your data management strategy.
Table of Comparison
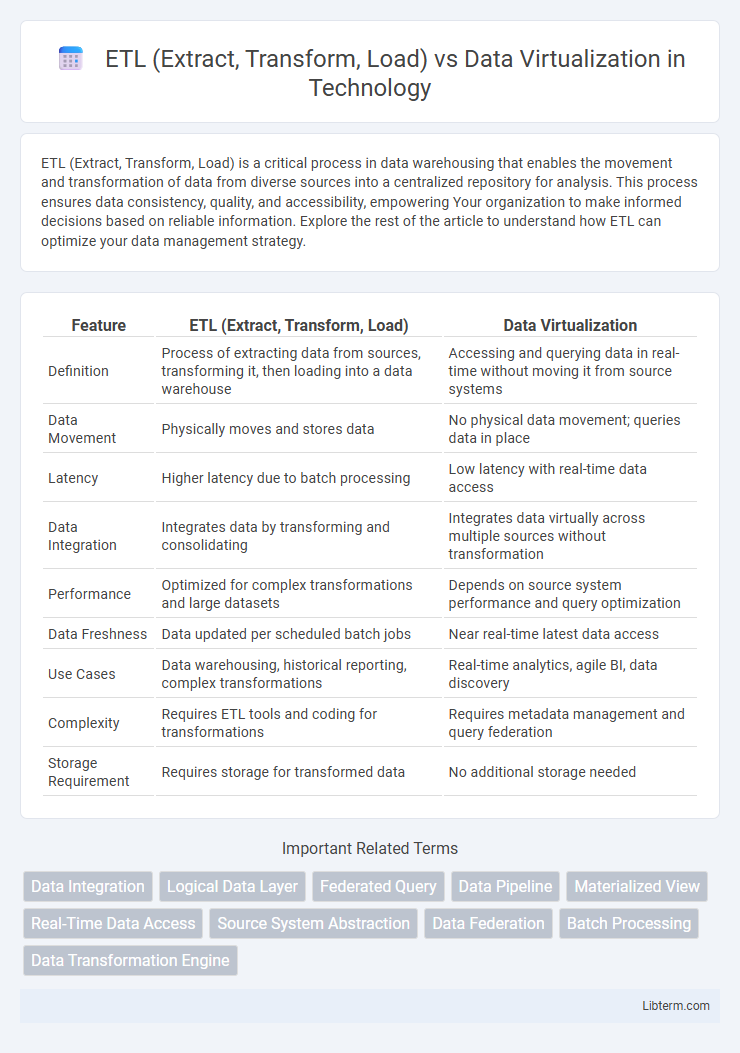
| Feature | ETL (Extract, Transform, Load) | Data Virtualization |
|---|---|---|
| Definition | Process of extracting data from sources, transforming it, then loading into a data warehouse | Accessing and querying data in real-time without moving it from source systems |
| Data Movement | Physically moves and stores data | No physical data movement; queries data in place |
| Latency | Higher latency due to batch processing | Low latency with real-time data access |
| Data Integration | Integrates data by transforming and consolidating | Integrates data virtually across multiple sources without transformation |
| Performance | Optimized for complex transformations and large datasets | Depends on source system performance and query optimization |
| Data Freshness | Data updated per scheduled batch jobs | Near real-time latest data access |
| Use Cases | Data warehousing, historical reporting, complex transformations | Real-time analytics, agile BI, data discovery |
| Complexity | Requires ETL tools and coding for transformations | Requires metadata management and query federation |
| Storage Requirement | Requires storage for transformed data | No additional storage needed |
Introduction to ETL and Data Virtualization
ETL (Extract, Transform, Load) involves extracting data from multiple sources, transforming it into a suitable format, and loading it into a centralized data warehouse for analysis. Data Virtualization, on the other hand, provides real-time access to data across disparate systems without physical movement or copying, creating a unified data layer. While ETL emphasizes preprocessing and storage for optimized querying, Data Virtualization prioritizes on-demand data integration and faster access with reduced data latency.
Defining ETL: Core Concepts and Processes
ETL (Extract, Transform, Load) is a data integration process that involves extracting data from various sources, transforming it to meet business rules and quality standards, and loading it into a target data warehouse or repository for analysis. Core ETL processes include data extraction from heterogeneous systems, data cleansing and validation during transformation, and efficient data loading to ensure accuracy and consistency. ETL is essential for creating structured, historical datasets optimized for complex analytics and reporting.
Understanding Data Virtualization: Key Principles
Data virtualization enables real-time data access by abstracting and integrating data from multiple sources without physical movement, offering agility over traditional ETL processes that rely on extracting, transforming, and loading data into a centralized repository. Key principles include creating a unified data layer, ensuring data consistency through semantic mapping, and delivering low-latency query performance across heterogeneous data environments. This approach reduces data duplication and accelerates analytics by providing a virtualized view of data instead of managing complex ETL pipelines.
ETL Architecture and Workflow Explained
ETL architecture involves a structured workflow where data is extracted from diverse sources, transformed through cleansing, aggregation, and enrichment, then loaded into a centralized data warehouse for analytics. This batch-oriented process ensures data consistency, historical preservation, and optimized query performance by physically storing integrated data. Data virtualization, in contrast, provides real-time data access without replication, but ETL remains the preferred approach for scenarios demanding high data quality, complex transformations, and stable reporting environments.
Data Virtualization Architecture and Components
Data Virtualization architecture integrates multiple data sources through a virtual layer without moving data, enabling real-time data access and abstraction. Key components include the Data Virtualization Server, which manages query processing and optimization; the Metadata Layer, responsible for data cataloging and semantic mapping; and the Data Source Connectors, facilitating seamless connectivity to heterogeneous systems. Unlike ETL processes that rely on data extraction and physical transformation, Data Virtualization emphasizes virtual integration, reducing data redundancy and latency while providing a unified data view.
Use Cases: When to Use ETL vs Data Virtualization
ETL (Extract, Transform, Load) is ideal for complex data integration requiring extensive data cleansing, transformation, and loading into a centralized repository like a data warehouse for high-performance analytics. Data virtualization suits real-time data access scenarios where users need to query and combine data from multiple heterogeneous sources without physical data movement, enabling agile reporting and operational decisions. Choose ETL for batch processing and historical data consolidation, while data virtualization excels in scenarios demanding low-latency access and federated data views across distributed systems.
Performance Comparison: ETL vs Data Virtualization
ETL processes typically offer higher performance for large-scale data integration by physically extracting, transforming, and loading data into optimized storage, enabling faster query execution and improved data accessibility. In contrast, data virtualization provides real-time data access without data movement, but may experience latency and slower performance due to on-the-fly query federation and dependency on source system speed. Performance effectiveness depends on data volume, complexity, and latency requirements, with ETL favored for batch processing and data warehousing, while data virtualization suits agile analytics and real-time decision-making scenarios.
Data Integration: Flexibility and Scalability
ETL processes provide robust data integration by physically extracting, transforming, and loading data into centralized repositories, ensuring high data quality and consistency but often requiring significant time and resources to scale. Data virtualization offers enhanced flexibility by enabling real-time access to distributed data sources without physical data movement, facilitating quicker integration and agile analytics across diverse platforms. Scalability in data virtualization benefits from its abstraction layer, allowing seamless connection to new data sources, whereas ETL scaling demands additional infrastructure and processing power for increased data volumes.
Security and Data Governance Considerations
ETL processes involve physically extracting, transforming, and loading data into centralized repositories, providing robust control over data lineage, access permissions, and compliance, which strengthens security and governance frameworks. Data Virtualization, by enabling real-time data access without data replication, reduces data sprawl but requires stringent access controls and encryption to mitigate risks associated with live data querying across multiple sources. Comprehensive data governance in ETL benefits from verifiable audit trails and standardized transformation protocols, whereas data virtualization demands dynamic governance policies to manage heterogeneous data sources and maintain consistent security posture.
Choosing the Right Approach for Your Business Needs
ETL (Extract, Transform, Load) offers robust data integration by physically consolidating and transforming data, ideal for businesses requiring high data quality and complex analytics. Data Virtualization provides real-time access to distributed data without replication, suited for organizations needing agility and quick insights with minimal infrastructure. Selecting the right approach depends on evaluating factors such as data volume, latency tolerance, governance requirements, and the complexity of data environments.
ETL (Extract, Transform, Load) Infographic