k-Anonymity is a crucial privacy technique that ensures individual data entries cannot be distinguished from at least k-1 others, protecting sensitive information in datasets. By generalizing or suppressing specific identifiers, it minimizes the risk of re-identification while maintaining data utility for analysis. Explore the rest of this article to understand how k-Anonymity can safeguard your data privacy effectively.
Table of Comparison
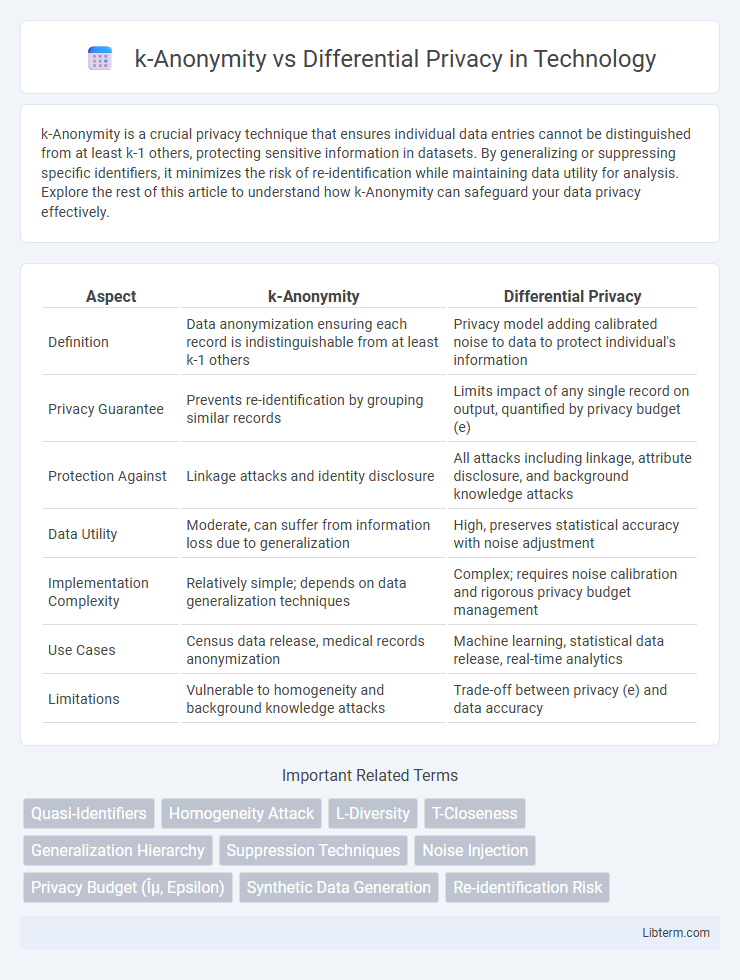
| Aspect | k-Anonymity | Differential Privacy |
|---|---|---|
| Definition | Data anonymization ensuring each record is indistinguishable from at least k-1 others | Privacy model adding calibrated noise to data to protect individual's information |
| Privacy Guarantee | Prevents re-identification by grouping similar records | Limits impact of any single record on output, quantified by privacy budget (e) |
| Protection Against | Linkage attacks and identity disclosure | All attacks including linkage, attribute disclosure, and background knowledge attacks |
| Data Utility | Moderate, can suffer from information loss due to generalization | High, preserves statistical accuracy with noise adjustment |
| Implementation Complexity | Relatively simple; depends on data generalization techniques | Complex; requires noise calibration and rigorous privacy budget management |
| Use Cases | Census data release, medical records anonymization | Machine learning, statistical data release, real-time analytics |
| Limitations | Vulnerable to homogeneity and background knowledge attacks | Trade-off between privacy (e) and data accuracy |
Introduction to Data Privacy Techniques
k-Anonymity ensures data privacy by generalizing and suppressing identifiers so that each individual is indistinguishable from at least k-1 others in a dataset, minimizing re-identification risks. Differential Privacy offers a mathematical framework by adding controlled noise to data queries, providing strong privacy guarantees even against attackers with auxiliary information. Both techniques play crucial roles in protecting sensitive information while enabling data utility in fields like healthcare and finance.
Understanding k-Anonymity: Definition and Mechanisms
k-Anonymity is a privacy model ensuring that each individual's data cannot be distinguished from at least k-1 other individuals within a dataset by generalizing or suppressing identifying attributes. Its mechanisms involve techniques like data generalization, where specific values are replaced with broader categories, and suppression, which removes sensitive information to prevent re-identification. This model aims to protect privacy by making every record indistinguishable within a group of size k, reducing the risk of identity disclosure.
Core Principles of Differential Privacy
Differential Privacy ensures individual data protection by adding controlled random noise to datasets, making it mathematically impossible to identify a single person's information with high confidence. The core principle revolves around the privacy parameter epsilon (e), which quantifies the trade-off between data accuracy and privacy guarantees. Unlike k-Anonymity, Differential Privacy provides robust protection against re-identification attacks even when adversaries have access to auxiliary information.
Key Differences Between k-Anonymity and Differential Privacy
k-Anonymity ensures privacy by making each individual's data indistinguishable from at least k-1 others through generalization and suppression techniques, while Differential Privacy adds calibrated noise to query results to provide provable privacy guarantees regardless of external knowledge. Unlike k-Anonymity, which can be vulnerable to background knowledge attacks and attribute disclosure, Differential Privacy provides robust protection against various attack vectors by quantifying privacy loss through a formal privacy parameter epsilon. The trade-off lies in utility and implementation complexity: k-Anonymity is easier to implement on static datasets but less flexible, whereas Differential Privacy supports dynamic queries with mathematically bounded privacy risks but often requires more sophisticated mechanisms.
Real-World Applications of k-Anonymity
k-Anonymity is widely applied in healthcare and census data to protect individual identities while maintaining data utility for research and policy-making. By ensuring each record is indistinguishable from at least k-1 others based on quasi-identifiers, k-Anonymity effectively prevents re-identification in datasets shared for statistical analysis. Real-world implementations include anonymizing patient records in electronic health records (EHRs) and safeguarding demographic information in national surveys.
Practical Implementations of Differential Privacy
Practical implementations of differential privacy leverage randomized algorithms to add calibrated noise to datasets, preserving individual data points while enabling accurate aggregate analysis. Unlike k-anonymity, which generalizes or suppresses data to achieve anonymity and often struggles with linkage attacks, differential privacy provides mathematically provable privacy guarantees regardless of external information. Key real-world applications include Google's RAPPOR and Apple's local differential privacy, demonstrating scalable privacy-preserving mechanisms integrated into large-scale data collection and analysis systems.
Advantages and Limitations of k-Anonymity
k-Anonymity enhances data privacy by ensuring that each individual's record is indistinguishable from at least k-1 others, reducing the risk of re-identification in shared datasets. Its advantages include simplicity and ease of implementation in data anonymization processes, especially in tabular datasets. However, k-Anonymity faces limitations such as vulnerability to homogeneity and background knowledge attacks, and it does not protect against attribute disclosure with multiple quasi-identifiers.
Strengths and Weaknesses of Differential Privacy
Differential privacy provides strong mathematical guarantees by ensuring individual data points cannot be distinguished, even against adversaries with background knowledge, which makes it highly effective for protecting user privacy in large datasets. Its main strength lies in the ability to quantify and control privacy loss through parameters like epsilon, enabling customizable privacy levels. However, differential privacy can suffer from reduced data utility due to noise addition, and its complexity often requires expert implementation to avoid misconfiguration and degraded analytical accuracy.
Choosing the Right Privacy Method for Your Data
Selecting the appropriate privacy method depends on the data type and privacy requirements; k-Anonymity ensures that each record is indistinguishable among at least k individuals, making it suitable for datasets where re-identification risk needs minimization with structured data. Differential Privacy offers mathematically rigorous guarantees by adding randomized noise to queries or datasets, ideal for dynamic data analysis and aggregate statistics without compromising individual information. Organizations must evaluate data sensitivity, utility needs, and threat models to balance privacy protection and analytical accuracy when choosing between k-Anonymity and Differential Privacy.
Future Trends in Data Anonymization and Privacy
Future trends in data anonymization emphasize the integration of k-Anonymity with Differential Privacy to balance data utility and privacy protection. Advances in machine learning algorithms enhance the dynamic adaptation of privacy parameters to evolving datasets, addressing the limitations of static k-Anonymity models. Emerging frameworks leverage hybrid privacy-preserving techniques, combining k-Anonymity's de-identification with Differential Privacy's mathematical noise injection to mitigate re-identification risks in large-scale data analytics.
k-Anonymity Infographic