A trie is a specialized tree data structure used to efficiently store and retrieve keys in a dataset, primarily strings like words or sequences. It enables fast prefix-based searches, making it ideal for autocomplete features and dictionary implementations. Explore the rest of the article to understand how a trie can optimize your search operations and enhance data handling.
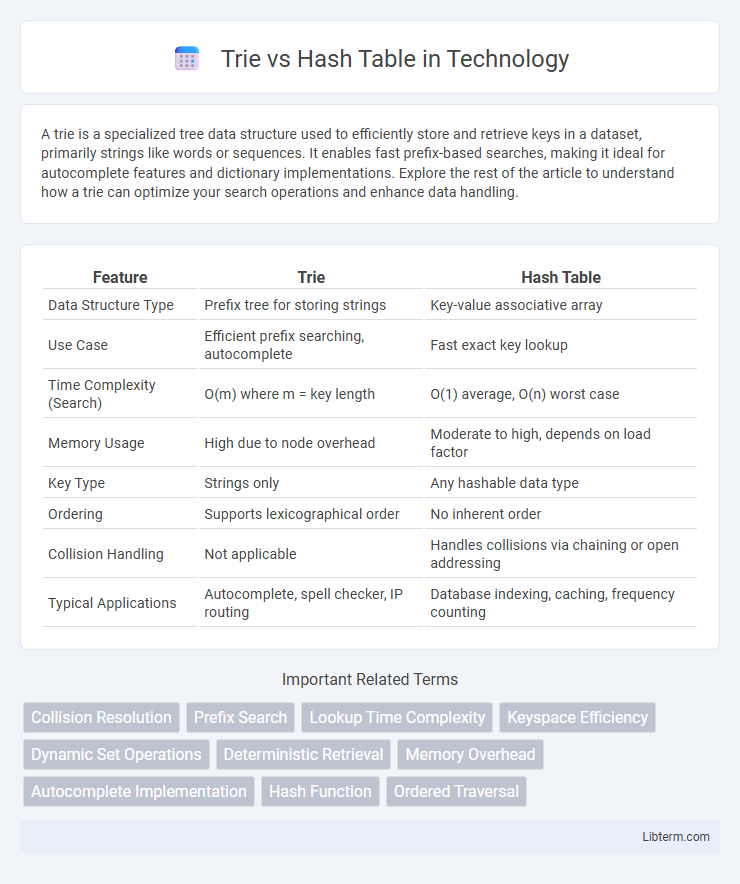
Table of Comparison
| Feature | Trie | Hash Table |
|---|---|---|
| Data Structure Type | Prefix tree for storing strings | Key-value associative array |
| Use Case | Efficient prefix searching, autocomplete | Fast exact key lookup |
| Time Complexity (Search) | O(m) where m = key length | O(1) average, O(n) worst case |
| Memory Usage | High due to node overhead | Moderate to high, depends on load factor |
| Key Type | Strings only | Any hashable data type |
| Ordering | Supports lexicographical order | No inherent order |
| Collision Handling | Not applicable | Handles collisions via chaining or open addressing |
| Typical Applications | Autocomplete, spell checker, IP routing | Database indexing, caching, frequency counting |
Introduction to Trie and Hash Table
Trie is a tree-like data structure primarily used for storing and searching strings efficiently by utilizing common prefixes, making it ideal for applications like autocomplete and spell checking. Hash Table is a data structure that maps keys to values using a hash function, providing average constant time complexity for insertion, deletion, and lookup operations. While Trie excels in prefix-based searches and ordered data retrieval, Hash Table offers faster access for exact key lookups but does not maintain any order among keys.
Data Structure Overview
A trie is a tree-like data structure that stores keys by breaking them into individual characters, enabling efficient retrieval of strings and prefix searches. Hash tables use a hash function to map keys to array indices, offering average-case constant time complexity for insertions, deletions, and lookups but lack inherent support for ordered data or prefix queries. Tries provide advantages in scenarios requiring lexicographical ordering and autocomplete features, while hash tables optimize for faster access in key-value stores with minimal memory overhead.
How Trie Works
A Trie organizes data in a tree-like structure where each node represents a character, enabling efficient retrieval by traversing paths corresponding to prefixes of stored strings. Each edge in the Trie corresponds to a character, and complete words are marked at terminal nodes, facilitating prefix searches, autocomplete, and spell checking. The time complexity for search, insert, or delete operations is proportional to the length of the word, making Trie highly suitable for applications needing fast prefix-based queries.
How Hash Table Functions
A hash table functions by mapping keys to specific indices in an array through a hash function, enabling efficient data retrieval with average time complexity of O(1). It handles collisions using methods such as chaining or open addressing to maintain performance despite key conflicts. Hash tables are widely used in applications where quick lookups, insertions, and deletions are essential, but they do not preserve the order of elements like trie structures do.
Key Differences Between Trie and Hash Table
Trie stores keys as a sequence of characters, enabling efficient prefix-based searches and ordered data retrieval, while Hash Table uses a hash function to map keys to values, providing average constant-time complexity for exact key lookups. Tries consume more memory due to their node-heavy structure but excel in operations like autocomplete and spell checking, unlike Hash Tables which are more memory-efficient and better suited for simple key-value pair storage. Hash Tables face challenges with collisions and lack inherent order, whereas Tries inherently maintain key order and support prefix queries seamlessly.
Performance Comparison: Speed and Efficiency
Trie outperforms hash tables in search operations for strings due to its prefix-based structure, enabling faster lookups with time complexity proportional to the key length (O(m)), compared to hash tables' average O(1) but potential worst-case O(n). Memory efficiency varies as tries use more space to store nodes for each character, while hash tables require memory for storing keys and managing collisions through buckets or linked lists. In scenarios involving large datasets with many keys sharing prefixes, tries deliver better speed and predictable query times, whereas hash tables excel in average-case speed for arbitrary key distributions with less overhead in memory usage.
Memory Usage and Scalability
Tries typically consume more memory than hash tables due to storing multiple child pointers per node, especially with large alphabets, but they offer better scalability for prefix-based queries and dynamic datasets with varying key lengths. Hash tables use a more compact memory footprint by hashing keys directly, which provides faster average lookup times but can suffer from collisions and rehashing overhead as the dataset grows. Memory optimization in tries is achievable with techniques like path compression, whereas hash tables scale efficiently with load factor management but may require resizing to maintain performance.
Use Cases and Applications
Tries excel in applications requiring efficient prefix-based searches, such as auto-completion, spell checking, and IP routing, due to their ability to store strings in a tree structure that allows fast retrieval of common prefixes. Hash tables are better suited for scenarios needing constant-time average complexity for exact key-value lookups, commonly used in caches, databases, and symbol tables. Use cases involving large-scale dictionary words or real-time text prediction prefer tries, while hash tables dominate in indexing, unique data storage, and quick membership testing.
Pros and Cons of Trie vs Hash Table
Trie structures enable efficient prefix-based searches and are optimal for tasks like auto-completion and spell-checking due to their ability to store keys as shared prefixes. Hash tables provide faster average-case lookup times with constant-time complexity, but they lack ordered traversal and have poor performance in prefix queries. Tries consume more memory than hash tables because of node overhead, while hash tables can suffer from collisions and require good hash functions for optimal performance.
Choosing the Right Data Structure
Choosing between a Trie and a Hash Table depends on use cases involving key search patterns and memory efficiency; Tries excel in prefix matching and lexicographical order queries, making them ideal for autocomplete and spell-check applications. Hash Tables provide average constant-time complexity for exact key lookups, optimizing speed for unordered key-value access but lack inherent order and prefix searching capabilities. Evaluating factors such as search requirements, memory constraints, and key distribution helps determine the optimal data structure for performance and scalability.
Trie Infographic