Storms bring intense weather conditions characterized by strong winds, heavy rain, and sometimes thunder and lightning that can disrupt daily life and damage property. Understanding storm patterns and preparedness measures can significantly reduce risks to Your safety and belongings. Explore the following article to learn how to recognize storm warnings and effectively safeguard Yourself during extreme weather events.
Table of Comparison
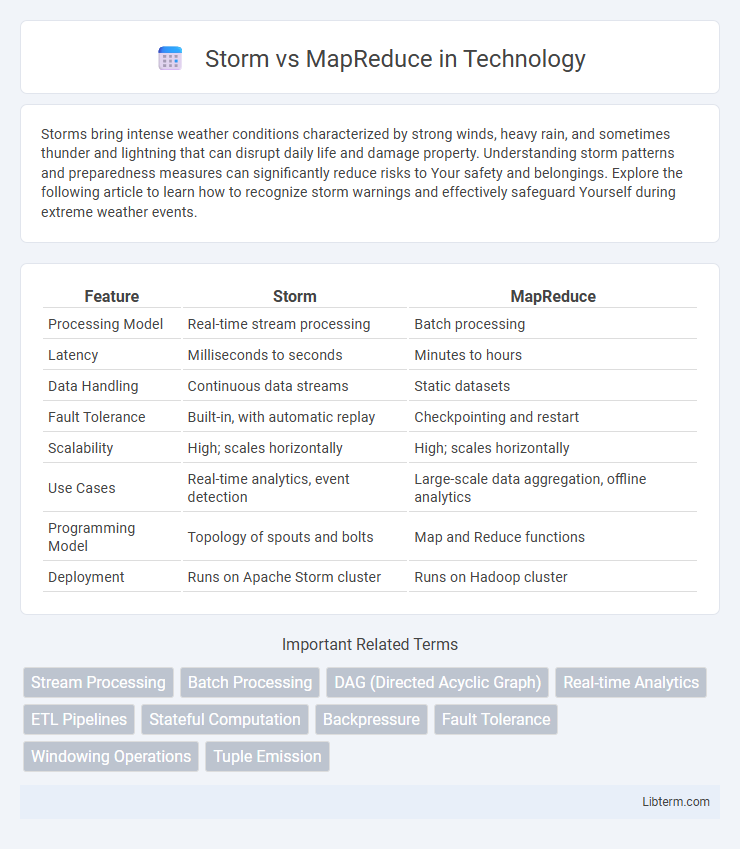
| Feature | Storm | MapReduce |
|---|---|---|
| Processing Model | Real-time stream processing | Batch processing |
| Latency | Milliseconds to seconds | Minutes to hours |
| Data Handling | Continuous data streams | Static datasets |
| Fault Tolerance | Built-in, with automatic replay | Checkpointing and restart |
| Scalability | High; scales horizontally | High; scales horizontally |
| Use Cases | Real-time analytics, event detection | Large-scale data aggregation, offline analytics |
| Programming Model | Topology of spouts and bolts | Map and Reduce functions |
| Deployment | Runs on Apache Storm cluster | Runs on Hadoop cluster |
Introduction to Storm and MapReduce
Storm is a distributed real-time computation system designed for processing large streams of data with low latency, enabling continuous, on-the-fly analytics. MapReduce is a programming model and processing technique primarily used for batch processing of massive datasets across distributed clusters by dividing tasks into map and reduce phases. While Storm excels in real-time processing, MapReduce is optimized for scalable, fault-tolerant batch data operations in big data environments.
Core Concepts and Architecture Comparison
Storm employs a real-time stream processing architecture with spouts and bolts for continuous data flow, enabling low-latency processing of unbounded streams. MapReduce uses a batch processing model based on map and reduce functions that handle large-scale data by dividing it into discrete chunks processed sequentially. Storm's distributed architecture achieves fault tolerance through task replication and stateful processing, while MapReduce relies on task re-execution and data replication within the Hadoop Distributed File System (HDFS) for fault tolerance.
Data Processing Models: Batch vs Stream
Storm processes data in real-time using a stream processing model, enabling continuous computation and low-latency event handling. MapReduce operates on a batch processing model, handling large volumes of data by dividing tasks into discrete batches processed sequentially or in parallel. Stream processing in Storm excels at processing unbounded, continuous data flows, while MapReduce is optimized for bounded, static datasets requiring high throughput over latency.
Performance and Scalability Differences
Storm delivers real-time stream processing with low latency, outperforming MapReduce's batch-oriented model, which introduces higher processing delays due to its reliance on disk I/O. Scalability in Storm is achieved through horizontal scaling by adding more worker nodes and tasks dynamically, whereas MapReduce scales by increasing the number of mappers and reducers but suffers from overhead in coordination and job setup. Storm's architecture allows faster recovery and continuous data handling, leading to superior performance and elasticity in large-scale data processing compared to MapReduce's periodic, resource-intensive batch execution.
Fault Tolerance Mechanisms
Storm employs a tuple acknowledgment framework that tracks the processing of each data unit, enabling precise failure detection and automatic replay of failed tuples for fault tolerance. MapReduce relies on task re-execution by monitoring task heartbeats through its JobTracker or ResourceManager, restarting only failed map or reduce tasks to ensure job completion. Both systems utilize checkpointing and task retries, but Storm's real-time tuple tracking offers lower latency fault recovery compared to MapReduce's batch-oriented fault tolerance.
Use Cases: When to Use Storm or MapReduce
Storm excels in real-time stream processing tasks such as fraud detection, live analytics, and continuous data ingestion where low latency is critical. MapReduce is ideal for batch processing large datasets, performing complex transformations, and generating reports in scenarios like log analysis and data warehousing. Choose Storm when immediate insights are needed; opt for MapReduce for processing vast amounts of data with fault tolerance and scalability.
Ease of Development and Deployment
Storm offers real-time stream processing with a straightforward API, making it easier for developers to build and deploy scalable, low-latency applications. MapReduce requires complex batch processing workflows with rigid job configurations, resulting in a steeper learning curve and longer deployment cycles. Storm's architecture supports continuous processing, enabling faster iteration and seamless deployment compared to the batch-oriented nature of MapReduce.
Integration with Big Data Ecosystems
Storm integrates seamlessly with big data ecosystems by supporting real-time stream processing and easily connecting to Apache Kafka, Apache Cassandra, and Hadoop HDFS for continuous data ingestion and output. MapReduce, as a batch processing framework within Apache Hadoop, excels in processing large-scale static data stored in HDFS but lacks native real-time processing capabilities. Enterprise solutions often combine Storm's real-time streaming prowess with MapReduce's batch analysis to achieve a comprehensive big data processing pipeline.
Real-Time Analytics vs Batch Processing
Storm excels in real-time analytics by processing streams of data with low latency, enabling immediate insights and rapid decision-making. MapReduce is designed for batch processing large datasets, performing complex computations across distributed nodes but with higher latency, making it suitable for offline, comprehensive data analysis. Real-time analytics demands continuous data ingestion and near-instant processing, which Storm provides, whereas batch processing with MapReduce operates on static datasets, optimizing throughput over speed.
Future Trends and Industry Adoption
Storm's real-time stream processing capabilities position it favorably for future trends emphasizing low-latency analytics and event-driven architectures, while MapReduce remains significant in batch processing and big data storage analytics. Industry adoption leans towards Storm for applications requiring continuous data ingestion and immediate insights, with companies in finance, telecommunications, and IoT sectors increasingly integrating it into their data pipelines. Emerging hybrid models and cloud-native platforms are driving collaborative use of Storm and MapReduce, enhancing scalability and operational efficiency in enterprise data ecosystems.
Storm Infographic