A data warehouse centralizes and consolidates large volumes of data from multiple sources, enabling efficient querying and analysis for business intelligence. It supports your organization's decision-making by providing a reliable, historical record of data optimized for reporting and analytics. Explore the rest of the article to understand how implementing a data warehouse can transform your data strategy.
Table of Comparison
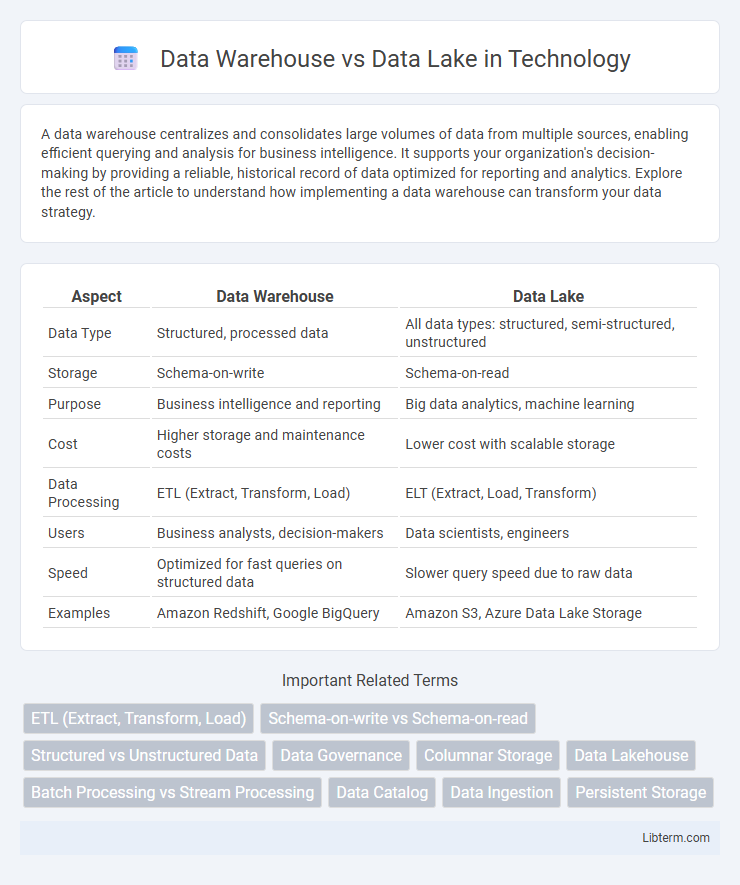
| Aspect | Data Warehouse | Data Lake |
|---|---|---|
| Data Type | Structured, processed data | All data types: structured, semi-structured, unstructured |
| Storage | Schema-on-write | Schema-on-read |
| Purpose | Business intelligence and reporting | Big data analytics, machine learning |
| Cost | Higher storage and maintenance costs | Lower cost with scalable storage |
| Data Processing | ETL (Extract, Transform, Load) | ELT (Extract, Load, Transform) |
| Users | Business analysts, decision-makers | Data scientists, engineers |
| Speed | Optimized for fast queries on structured data | Slower query speed due to raw data |
| Examples | Amazon Redshift, Google BigQuery | Amazon S3, Azure Data Lake Storage |
Introduction to Data Warehouse and Data Lake
Data warehouses store structured data optimized for query performance and business intelligence, enabling organizations to analyze historical data from multiple sources. Data lakes retain raw, unprocessed data in its native format, supporting diverse data types and flexible analytics, including machine learning and real-time processing. Both serve distinct purposes in modern data architecture, with warehouses emphasizing structured data management and lakes enabling extensive, scalable data storage.
Key Definitions and Core Concepts
A Data Warehouse is a structured repository designed for storing processed, filtered, and transformed data optimized for analytics and reporting, characterized by schema-on-write and high data quality standards. A Data Lake stores raw, unprocessed data in its native format, supporting schema-on-read and accommodating diverse data types like structured, semi-structured, and unstructured data for flexible analysis. The core distinction lies in Data Warehouses emphasizing data consistency and performance for business intelligence, while Data Lakes prioritize scalability and flexibility for big data and advanced analytics.
Architecture Overview: Data Warehouse vs Data Lake
Data Warehouse architecture is designed around structured data stored in relational databases with predefined schemas optimized for fast query performance and business intelligence analytics. Data Lake architecture supports diverse data types including structured, semi-structured, and unstructured data stored in a flat architecture using scalable storage systems like Hadoop or cloud object storage. The key distinction lies in Data Warehouse's schema-on-write approach versus Data Lake's schema-on-read flexibility, enabling different use cases and data processing methods.
Data Structure and Storage Formats
Data warehouses use structured data stored in relational databases with schema-on-write, optimizing for fast querying and analytics. Data lakes store raw, unstructured, semi-structured, and structured data in various formats like JSON, Parquet, and Avro, employing schema-on-read for flexibility. The storage in data lakes is typically cost-effective and scalable, utilizing distributed file systems or cloud object storage, unlike the more rigid and optimized storage of data warehouses.
Data Ingestion and Processing
Data warehouses use structured data ingestion through Extract, Transform, Load (ETL) processes to ensure data quality and consistency for reporting and analytics. Data lakes support bulk ingestion of raw, unstructured, and semi-structured data using Extract, Load, Transform (ELT) methods, enabling flexible schema-on-read processing. Processing in data warehouses is optimized for complex queries on cleaned data, while data lakes facilitate scalable, diverse analytics including machine learning on large datasets.
Scalability and Performance Comparison
Data warehouses provide structured storage with optimized query performance for complex analytics, supporting high concurrency and consistent performance through schema enforcement and indexing. Data lakes offer massive scalability by efficiently storing vast amounts of unstructured, semi-structured, and structured data in distributed storage systems, enabling flexible data ingestion but often requiring additional processing for query optimization. While data warehouses excel in fast, reliable analytics on cleaned data, data lakes prioritize scalable storage and raw data access, making them suitable for diverse and large-scale data scenarios with variable query performance.
Security and Compliance Considerations
Data warehouses enforce strict schema-on-write protocols, enhancing data quality and regulatory compliance through structured access controls and encryption standards like AES-256. Data lakes offer flexible schema-on-read storage but require advanced security measures such as fine-grained access control, data masking, and activity logging to meet compliance frameworks like GDPR and HIPAA. Organizations must implement robust identity and access management (IAM) policies and continuous monitoring to secure sensitive data across both platforms effectively.
Cost Implications and Resource Utilization
Data warehouses generally incur higher costs due to structured storage, optimized query performance, and frequent data transformations requiring significant compute resources, while data lakes offer cost-effective storage by handling vast volumes of raw, unprocessed data on cheaper hardware or cloud object stores. Resource utilization in data warehouses emphasizes CPU-intensive Extract, Transform, Load (ETL) processes and storage for processed datasets, whereas data lakes leverage scalable, often serverless architectures that minimize upfront compute expenses but may demand advanced analytics tools for efficient data management. Choosing between data warehouse and data lake architectures involves evaluating total cost of ownership (TCO), considering factors like data volume, processing frequency, query complexity, and long-term scalability requirements.
Use Cases and Industry Applications
Data warehouses excel in structured data analytics for business intelligence, supporting industries like finance, healthcare, and retail with real-time reporting and compliance tracking. Data lakes are designed to store vast amounts of raw, unstructured, and semi-structured data, ideal for big data analytics, AI, and machine learning in technology, media, and IoT sectors. Companies utilize data warehouses for operational efficiency and regulatory reporting, while data lakes enable advanced data discovery and innovation through flexible schema and scalable storage.
Choosing the Right Solution for Your Business
Choosing the right data storage solution depends on your business's needs for structure, scalability, and analytics. Data warehouses excel in handling structured data with optimized query performance and consistent data governance, making them ideal for operational reporting and business intelligence. Conversely, data lakes offer flexibility by storing diverse, raw data types at scale, supporting advanced analytics and machine learning use cases for organizations prioritizing data variety and exploration.
Data Warehouse Infographic