Data warehouses are centralized repositories designed to store large volumes of structured data from multiple sources, enabling efficient querying and analysis. They support business intelligence activities by integrating and organizing data to provide valuable insights and improve decision-making. Explore the rest of the article to discover how data warehouses can transform Your data management strategy.
Table of Comparison
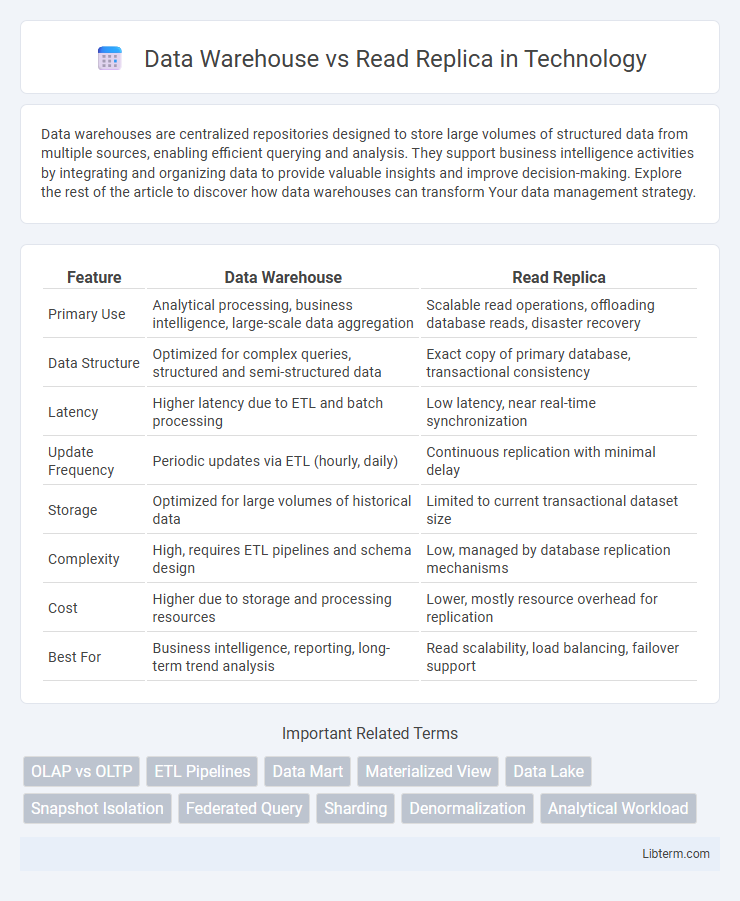
| Feature | Data Warehouse | Read Replica |
|---|---|---|
| Primary Use | Analytical processing, business intelligence, large-scale data aggregation | Scalable read operations, offloading database reads, disaster recovery |
| Data Structure | Optimized for complex queries, structured and semi-structured data | Exact copy of primary database, transactional consistency |
| Latency | Higher latency due to ETL and batch processing | Low latency, near real-time synchronization |
| Update Frequency | Periodic updates via ETL (hourly, daily) | Continuous replication with minimal delay |
| Storage | Optimized for large volumes of historical data | Limited to current transactional dataset size |
| Complexity | High, requires ETL pipelines and schema design | Low, managed by database replication mechanisms |
| Cost | Higher due to storage and processing resources | Lower, mostly resource overhead for replication |
| Best For | Business intelligence, reporting, long-term trend analysis | Read scalability, load balancing, failover support |
Introduction to Data Warehouses and Read Replicas
Data warehouses are centralized repositories designed for complex analytical queries and business intelligence, aggregating data from multiple sources to support decision-making processes. Read replicas, on the other hand, are duplicated instances of primary databases optimized for read-heavy workloads, enhancing application performance and availability without impacting the primary database's write operations. While data warehouses facilitate extensive data analysis with historical insights, read replicas primarily serve to distribute read traffic and increase scalability in operational environments.
What Is a Data Warehouse?
A data warehouse is a centralized repository designed to store large volumes of structured data from multiple sources, optimized for query and analysis rather than transaction processing. It supports complex analytical queries, reporting, and business intelligence by aggregating historical data, enabling trend analysis and informed decision-making. Unlike read replicas, which primarily enhance database performance and availability by duplicating live operational data, data warehouses provide a distinct environment tailored for deep data mining and extensive reporting.
What Is a Read Replica?
A read replica is a copy of a primary database that enables read-only queries to reduce the load on the main database and improve performance. It synchronizes data asynchronously, ensuring near real-time consistency without affecting write operations on the primary database. Read replicas are commonly used for scaling read-heavy workloads, backups, and disaster recovery in cloud-based architectures.
Key Differences Between Data Warehouses and Read Replicas
Data warehouses are centralized repositories designed for complex analytical queries and large-scale data integration from multiple sources, optimized for OLAP (Online Analytical Processing) workloads. Read replicas serve as copies of primary databases to distribute read traffic and improve application performance, focusing on real-time transactional data with OLTP (Online Transaction Processing) characteristics. Key differences include their primary use cases, with data warehouses supporting business intelligence and historical analysis, while read replicas enhance read scalability and reduce load on primary operational databases.
Use Cases: When to Choose a Data Warehouse
Data warehouses are ideal for complex analytical queries, large-scale data integration, and long-term historical analysis, supporting business intelligence and decision-making processes. They consolidate data from multiple sources, enabling deep insights through advanced reporting and machine learning algorithms. Choose a data warehouse when you need optimized query performance on vast datasets, accurate data modeling, and robust support for varied analytics workloads beyond real-time operational reads.
Use Cases: When to Use Read Replicas
Read replicas are ideal for offloading read-heavy workloads from a primary database, enabling improved application performance and scalability without impacting write operations. They support use cases such as real-time analytics, reporting, and disaster recovery where up-to-date but eventually consistent data is sufficient. When applications require low-latency access to frequently updated data with high availability, read replicas provide an efficient solution compared to data warehouses, which are optimized for complex, large-scale analytical queries.
Performance and Scalability Comparison
Data warehouses are optimized for complex queries and large-scale analytics by using columnar storage and massively parallel processing, delivering high-performance data aggregation and reporting across vast datasets. Read replicas enhance database read scalability by offloading read traffic from the primary database, but they typically lack the analytical optimizations and may introduce replication lag, impacting real-time query performance. For scalable analytics workloads, data warehouses outperform read replicas by efficiently handling concurrent, complex queries with faster response times and better resource isolation.
Data Consistency and Latency Considerations
Data warehouses offer high data consistency by integrating and transforming data from diverse sources into a single, authoritative repository, ensuring analytical accuracy. Read replicas prioritize low latency for read operations by asynchronously replicating live database data, potentially causing slight delays and eventual consistency issues. Choosing between them depends on balancing immediate data freshness with reliable, consistent reporting and complex querying needs.
Cost Implications: Data Warehouse vs Read Replica
Data warehouses incur higher costs due to their storage, compute, and complex ETL processes optimized for analytics on large datasets, while read replicas primarily increase expenses by duplicating operational databases for read scalability and failover. Data warehouses often require separate infrastructure and licensing fees, making them more expensive compared to read replicas that leverage primary database resources with minimal additional overhead. Budget decisions hinge on workload type, with data warehouses being cost-effective for heavy analytical queries and read replicas better suited for cost-efficient operational read scaling.
Choosing the Right Solution for Your Business
Choosing between a data warehouse and a read replica depends on your business needs for scalability, performance, and analytical capabilities. Data warehouses excel in handling complex queries, large-scale data integration, and historical analysis, making them ideal for business intelligence and decision-making workflows. Read replicas provide simplified data redundancy and load balancing for operational databases, enhancing read performance but lacking advanced analytics and aggregation features found in data warehouses.
Data Warehouse Infographic