Sharding enhances database performance by partitioning large datasets into smaller, more manageable pieces called shards, allowing for faster query processing and improved scalability. This technique is vital for handling big data efficiently across distributed systems and cloud environments. Explore the rest of the article to understand how sharding can optimize your data infrastructure.
Table of Comparison
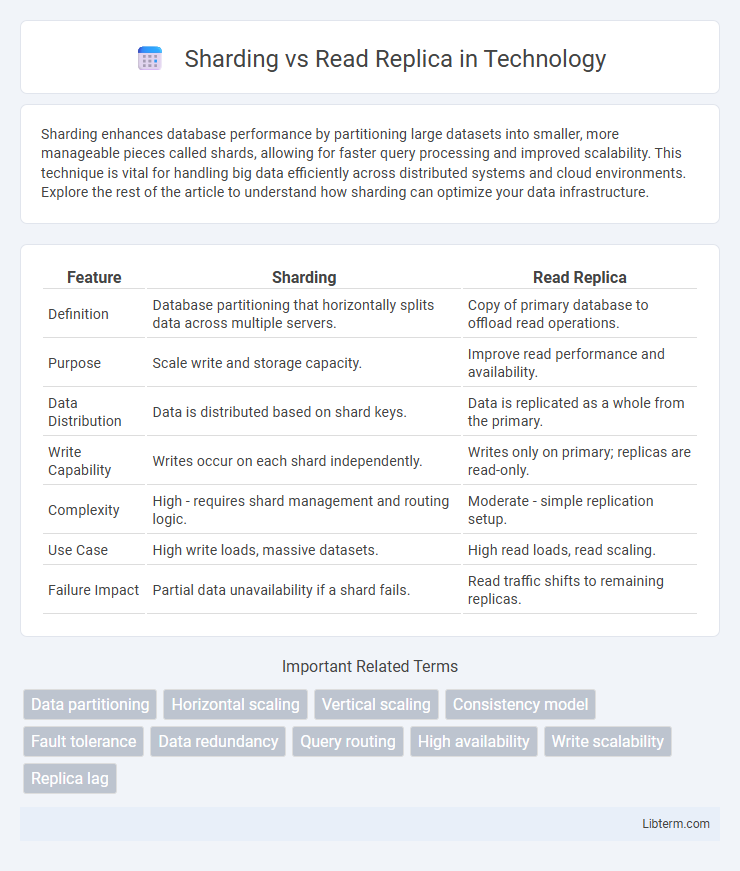
| Feature | Sharding | Read Replica |
|---|---|---|
| Definition | Database partitioning that horizontally splits data across multiple servers. | Copy of primary database to offload read operations. |
| Purpose | Scale write and storage capacity. | Improve read performance and availability. |
| Data Distribution | Data is distributed based on shard keys. | Data is replicated as a whole from the primary. |
| Write Capability | Writes occur on each shard independently. | Writes only on primary; replicas are read-only. |
| Complexity | High - requires shard management and routing logic. | Moderate - simple replication setup. |
| Use Case | High write loads, massive datasets. | High read loads, read scaling. |
| Failure Impact | Partial data unavailability if a shard fails. | Read traffic shifts to remaining replicas. |
Introduction to Database Scalability
Sharding and read replicas are essential techniques for database scalability, each addressing different performance challenges. Sharding partitions data across multiple servers to distribute write and read loads, enhancing horizontal scalability. Read replicas duplicate data from a primary database to serve read-heavy workloads, improving read throughput without affecting write performance.
Understanding Sharding: Definition and Use Cases
Sharding is a database partitioning technique that distributes data across multiple servers or nodes to improve scalability and performance by handling large datasets. It is commonly used in scenarios with high write volumes, such as social media platforms and online gaming, where horizontal scaling is essential to manage distributed data efficiently. Unlike read replicas that only duplicate data for read scalability, sharding enables both read and write operations to be processed in parallel across shards, minimizing bottlenecks and latency.
Exploring Read Replicas: Definition and Applications
Read replicas are copies of primary databases designed to handle read-heavy workloads by distributing query traffic, improving application performance and scalability. They are commonly employed in scenarios like reporting, analytics, and offloading read operations from the main database to prevent bottlenecks. Unlike sharding, which partitions data across multiple nodes to increase write capacity, read replicas maintain a full copy of data, focusing primarily on read scalability and fault tolerance.
Core Differences Between Sharding and Read Replicas
Sharding distributes data across multiple database instances, each holding a subset of the total dataset, enabling horizontal scaling by partitioning data based on a key. Read replicas replicate data from a primary database to read-only copies, improving read performance and load balancing without splitting the dataset. Core differences lie in sharding's data partitioning for write scalability versus read replicas' duplication for read scalability and redundancy.
Data Distribution in Sharding vs Read Replication
Sharding distributes data horizontally across multiple database instances by partitioning tables into smaller, more manageable segments, enhancing write and read performance through parallel processing. Read replicas, however, duplicate the entire dataset from a primary database to one or more secondary instances, primarily optimizing read operations without impacting write workloads. Consequently, sharding balances load through data segmentation, whereas read replication improves read scalability by creating complete dataset copies.
Performance Impact: Sharding vs Read Replica
Sharding distributes data across multiple database servers, significantly improving write performance and enabling horizontal scalability by reducing the load on any single node. Read replicas enhance read performance by offloading read queries from the primary database, but they do not improve write throughput or reduce write latency. Therefore, sharding offers better overall performance impact for write-heavy workloads, while read replicas primarily optimize read-heavy applications without scaling writes.
Scaling Strategies: When to Choose Sharding
Sharding is a scaling strategy that partitions a database into smaller, manageable segments, each hosted on a separate server, making it ideal for handling large datasets with high write throughput and horizontal scalability needs. It is preferable when the workload involves complex queries distributed evenly across shards or when a single database becomes a performance bottleneck due to write-intensive operations. Read replicas, in contrast, primarily enhance read performance by duplicating data across servers but do not alleviate write limitations or address capacity issues inherent in a single database instance.
High Availability and Disaster Recovery Comparison
Sharding partitions data across multiple databases to enhance scalability and fault tolerance, improving high availability by isolating failures to individual shards. Read replicas provide redundancy by copying data from a primary database to secondary nodes, enabling quick failover and improved disaster recovery through data synchronization. While sharding excels in distributing loads and preventing single points of failure, read replicas focus on data redundancy and quick recovery from primary database failures.
Cost Considerations: Sharding versus Read Replicas
Sharding can reduce costs by distributing write and read workloads across multiple servers, minimizing the need for expensive, high-capacity hardware in any single node. Read replicas lower expenses by offloading read queries from the primary database, reducing the load and improving read scalability without significant changes to the schema. The choice between sharding and read replicas depends on workload patterns, with sharding typically requiring higher upfront engineering costs but offering better long-term scalability for write-heavy applications.
Choosing the Right Approach for Your Database Needs
Sharding distributes data across multiple servers to improve write scalability and handle large datasets, while read replicas replicate data to separate nodes primarily to enhance read performance and provide redundancy. Selecting between sharding and read replicas depends on workload characteristics: choose sharding for massive data volume and write scaling requirements, and read replicas for read-heavy applications needing improved query response times. Understanding application access patterns and scaling goals is essential to implement the optimal database architecture.
Sharding Infographic