A Merkle tree is a cryptographic data structure used to efficiently verify the integrity and consistency of large data sets. It works by hashing pairs of nodes recursively until a single root hash is formed, ensuring secure and tamper-proof verification processes. Discover how understanding Merkle trees can enhance your knowledge of data security and blockchain technology by reading the full article.
Table of Comparison
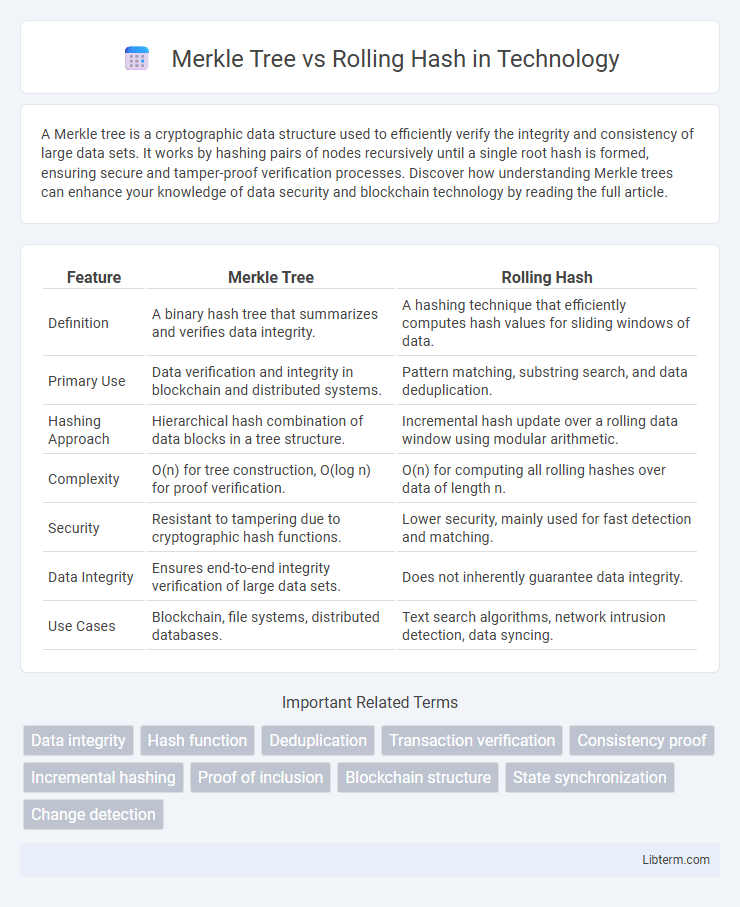
| Feature | Merkle Tree | Rolling Hash |
|---|---|---|
| Definition | A binary hash tree that summarizes and verifies data integrity. | A hashing technique that efficiently computes hash values for sliding windows of data. |
| Primary Use | Data verification and integrity in blockchain and distributed systems. | Pattern matching, substring search, and data deduplication. |
| Hashing Approach | Hierarchical hash combination of data blocks in a tree structure. | Incremental hash update over a rolling data window using modular arithmetic. |
| Complexity | O(n) for tree construction, O(log n) for proof verification. | O(n) for computing all rolling hashes over data of length n. |
| Security | Resistant to tampering due to cryptographic hash functions. | Lower security, mainly used for fast detection and matching. |
| Data Integrity | Ensures end-to-end integrity verification of large data sets. | Does not inherently guarantee data integrity. |
| Use Cases | Blockchain, file systems, distributed databases. | Text search algorithms, network intrusion detection, data syncing. |
Introduction to Data Integrity Verification
Merkle Trees and Rolling Hash techniques are pivotal for data integrity verification in distributed systems and communication protocols. Merkle Trees use a hierarchical hash structure to enable efficient and secure verification of large data sets by computing and comparing root hashes. Rolling Hash algorithms provide quick recalculations of hash values over sliding windows, optimizing real-time data integrity checks in streaming or dynamic content scenarios.
What is a Merkle Tree?
A Merkle Tree is a cryptographic data structure that organizes data blocks into a binary tree, where each leaf node contains a hash of a data block and each non-leaf node contains the hash of its child nodes, enabling efficient and secure verification of data integrity. It is widely used in blockchain technology and distributed systems to verify the consistency and contents of large data sets without needing to access the entire data. Unlike rolling hash algorithms, which compute hash values over sliding windows of data to detect changes, Merkle Trees provide hierarchical and tamper-evident proofs of data structure and authenticity.
Understanding Rolling Hash Algorithms
Rolling hash algorithms efficiently compute hash values for substrings by updating the hash based on the previous substring's value, enabling constant-time substring comparison in string matching applications. Unlike Merkle Trees, which construct hierarchical hash structures to verify data integrity in large datasets, rolling hashes are optimized for sliding window techniques in pattern detection and duplicate elimination. The Rabin-Karp algorithm exemplifies rolling hash utility, leveraging polynomial rolling hashes to quickly identify matching patterns with minimal recomputation.
Core Differences: Merkle Tree vs Rolling Hash
Merkle Trees utilize a hierarchical, hash-based structure that combines multiple data blocks into a single hash, enabling efficient and secure verification of large data sets, while Rolling Hash employs a sliding window technique to compute hash values incrementally for substrings. Merkle Trees prioritize data integrity and tamper detection through hash aggregation, ideal for blockchain and distributed ledgers, whereas Rolling Hash excels in pattern matching and substring search due to its rapid hash update capability. The core difference lies in Merkle Trees' tree-based design for cryptographic proofs versus Rolling Hash's linear, windowed approach optimized for string algorithms.
Use Cases: When to Choose Merkle Tree
Merkle Trees excel in blockchain and distributed ledger technologies by efficiently verifying data integrity and consistency across decentralized networks. They are ideal for applications requiring secure and tamper-proof proofs, such as cryptocurrency transactions and secure file systems. Choose Merkle Trees when ensuring trustless verification and data auditability is critical.
Use Cases: When to Use Rolling Hash
Rolling hash algorithms are ideal for applications requiring efficient substring search and data deduplication, such as in the Rabin-Karp string matching algorithm or incremental file comparison. They excel in scenarios where hash values need to be updated dynamically with minimal recomputation, making them suitable for real-time data streams and sliding window protocols. Merkle trees, by contrast, are better suited for verifying data integrity in distributed systems or blockchain environments where hierarchical hash structures ensure tamper-proof authentication.
Performance Comparison
Merkle Trees provide efficient integrity verification and tamper detection in large data structures with logarithmic proof sizes, making them ideal for blockchain and distributed systems. Rolling Hash algorithms excel in sequential data processing tasks like substring search and streaming data analysis, offering constant-time hash updates per new character, which enhances real-time performance. For large-scale, static data integrity validation, Merkle Trees outperform, while Rolling Hashes deliver superior performance in dynamic or sliding window scenarios.
Security Implications
Merkle Trees provide strong security guarantees by enabling efficient and secure verification of data integrity through cryptographic hash functions and tree structures, reducing the risk of tampering and ensuring authenticity. Rolling Hash techniques, while useful for quick substring searches and checksum calculations, offer weaker security properties because they lack collision resistance and are more vulnerable to hash manipulation attacks. Consequently, Merkle Trees are preferred in blockchain and distributed ledger technologies where data integrity and security are paramount.
Scalability and Efficiency
Merkle Trees offer superior scalability by enabling efficient verification of large datasets through hierarchical hashing, reducing the need for full data traversal. Rolling Hashes excel in efficiency for detecting changes in streaming data or sliding windows, minimizing recomputation with constant-time updates. While Merkle Trees are optimal for batch verification in distributed systems, Rolling Hashes provide rapid incremental updates, making them complementary in different scalability scenarios.
Conclusion: Choosing the Right Solution
Merkle Trees excel in providing cryptographic proof and secure data verification, making them ideal for blockchain and distributed ledger technologies. Rolling Hash algorithms offer efficient pattern matching and quick incremental updates, suited for applications like plagiarism detection and data synchronization. Select Merkle Trees when data integrity and tamper-proof validation are paramount; opt for Rolling Hash when speed and continuous data comparison are critical.
Merkle Tree Infographic