Causal consistency ensures that operations in distributed systems are seen by all nodes in an order that preserves cause-effect relationships, preventing anomalies caused by out-of-order updates. This model balances consistency and performance, making it suitable for applications where understanding the sequence of events is critical. Discover how causal consistency can improve your system's reliability by reading the full article.
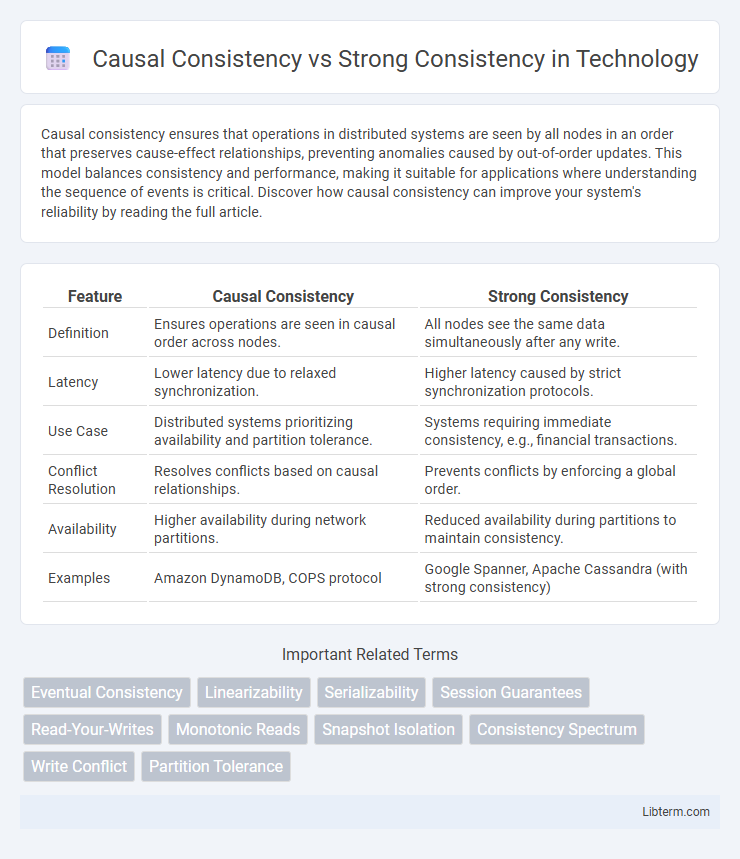
Table of Comparison
| Feature | Causal Consistency | Strong Consistency |
|---|---|---|
| Definition | Ensures operations are seen in causal order across nodes. | All nodes see the same data simultaneously after any write. |
| Latency | Lower latency due to relaxed synchronization. | Higher latency caused by strict synchronization protocols. |
| Use Case | Distributed systems prioritizing availability and partition tolerance. | Systems requiring immediate consistency, e.g., financial transactions. |
| Conflict Resolution | Resolves conflicts based on causal relationships. | Prevents conflicts by enforcing a global order. |
| Availability | Higher availability during network partitions. | Reduced availability during partitions to maintain consistency. |
| Examples | Amazon DynamoDB, COPS protocol | Google Spanner, Apache Cassandra (with strong consistency) |
Introduction to Consistency Models
Consistency models define the rules for visibility and ordering of operations in distributed systems, ensuring data accuracy and predictability across replicas. Causal consistency guarantees that operations causally related are seen by all nodes in the same order, allowing concurrent operations to proceed independently and improving system availability. Strong consistency enforces a strict total order on all operations, ensuring that all nodes see the same data simultaneously but often at the cost of increased latency and reduced availability during network partitions.
Defining Causal Consistency
Causal consistency is a consistency model in distributed systems that ensures operations that are causally related are seen by all nodes in the same order, preserving cause-and-effect relationships. Unlike strong consistency, which guarantees a single global order for all operations, causal consistency only requires order preservation for operations with causal dependencies, allowing for higher availability and performance. This model is particularly useful in collaborative applications and distributed databases where maintaining the partial order of events is critical without the overhead of total synchronization.
Understanding Strong Consistency
Strong consistency guarantees that any read operation returns the most recent write across all replicas, ensuring a single global order of operations. This model prevents conflicts and provides a straightforward programming model but often introduces higher latency due to synchronization overhead. Applications requiring immediate consistency and correctness, like banking systems, typically rely on strong consistency to maintain data integrity.
Key Differences Between Causal and Strong Consistency
Causal consistency ensures that operations that are causally related are seen by all processes in the same order, allowing for more flexible and efficient distributed systems, whereas strong consistency requires all operations to be seen in the exact same order by every node, providing a stricter guarantee. The key difference lies in the trade-off between performance and strict ordering: causal consistency allows concurrent updates to be observed at different times as long as causality is preserved, while strong consistency enforces a global order, often resulting in higher latency. Causal consistency supports eventual convergence with preserved causality, while strong consistency guarantees immediate consistency across all replicas after every operation.
Real-World Applications of Causal Consistency
Causal consistency ensures that operations reflecting cause-and-effect relationships are observed in the correct order, making it ideal for collaborative applications like social media feeds, distributed version control systems, and multi-user document editing where user actions must appear consistently across devices. Unlike strong consistency, which requires all nodes to see the latest data instantly, causal consistency improves performance and availability by allowing eventual synchronization while preserving the logical order of events. This balance enables real-world applications to scale efficiently without sacrificing data coherence critical for user experience.
When to Use Strong Consistency
Strong consistency guarantees that all users see the most recent write, making it essential for systems requiring immediate accuracy, such as financial transactions or inventory management. It is the preferred choice when applications must prevent anomalies like stale reads or conflicting updates, ensuring data integrity across distributed databases. Environments with strict compliance requirements or real-time decision-making benefit significantly from strong consistency models.
Performance Implications and Trade-offs
Causal consistency offers improved performance in distributed systems by allowing operations to be replicated asynchronously while preserving the cause-effect relationship, which reduces latency and increases availability compared to strong consistency. Strong consistency enforces a strict order of operations across all nodes, resulting in higher synchronization overhead and increased response times due to coordination protocols like Paxos or Raft. The trade-off involves choosing between lower latency and higher scalability with causal consistency versus immediate consistency guarantees and potential performance bottlenecks with strong consistency.
Challenges in Implementing Consistency Models
Implementing causal consistency presents challenges such as tracking causal dependencies across distributed systems, which requires maintaining metadata to ensure operations respect the happens-before relationship. Strong consistency demands coordination mechanisms like consensus protocols, leading to increased latency and reduced availability under network partitions due to the CAP theorem. Balancing performance, fault tolerance, and consistency guarantees remains a fundamental challenge when choosing between causal and strong consistency models in distributed databases.
Causal Consistency vs Strong Consistency: Use Cases
Causal consistency suits collaborative applications like social media and real-time messaging, where preserving the order of related updates is crucial for user experience without sacrificing availability. Strong consistency is essential in financial systems and inventory management, where immediate and synchronized data accuracy across all nodes prevents conflicts and maintains transactional integrity. Choosing between causal and strong consistency depends on the application's tolerance for latency, partition tolerance, and the criticality of immediate data synchronization.
Future Trends in Data Consistency Models
Future trends in data consistency models emphasize hybrid approaches combining causal consistency's efficiency with strong consistency's reliability to balance low latency and fault tolerance in distributed systems. Emerging techniques leverage machine learning to predict and resolve conflicts dynamically, enhancing system responsiveness and consistency guarantees. The adoption of geo-distributed databases and cloud-native architectures drives innovation toward adaptive consistency models that optimize performance based on workload and network conditions.
Causal Consistency Infographic