Graph databases store data in nodes and relationships, enabling complex queries and efficient analysis of interconnected information. They excel in use cases like social networks, recommendation engines, and fraud detection where relationships are crucial. Explore the rest of the article to discover how graph databases can enhance your data management strategy.
Table of Comparison
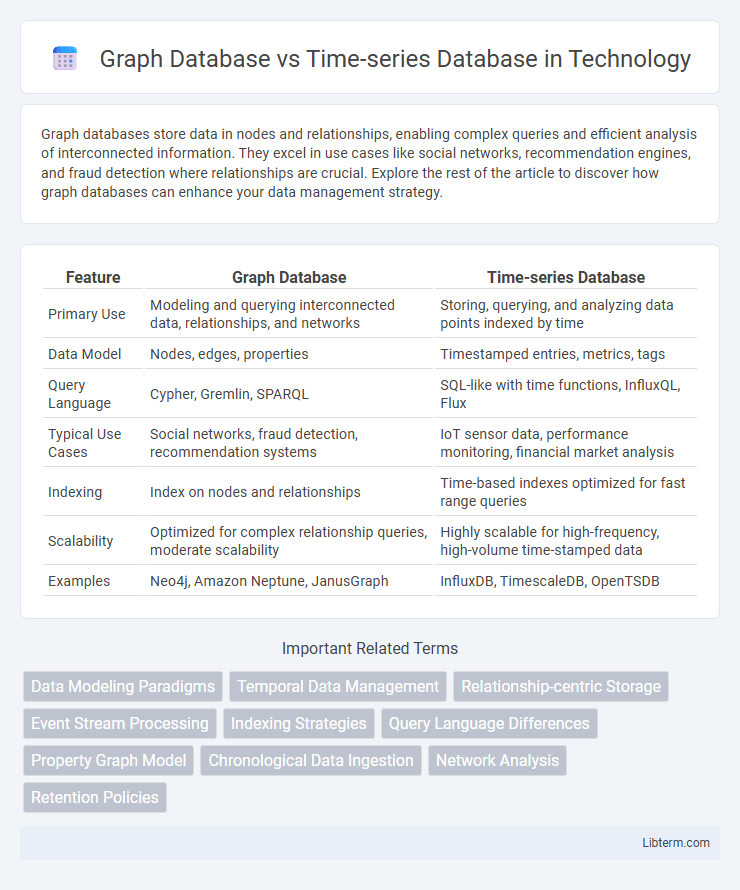
| Feature | Graph Database | Time-series Database |
|---|---|---|
| Primary Use | Modeling and querying interconnected data, relationships, and networks | Storing, querying, and analyzing data points indexed by time |
| Data Model | Nodes, edges, properties | Timestamped entries, metrics, tags |
| Query Language | Cypher, Gremlin, SPARQL | SQL-like with time functions, InfluxQL, Flux |
| Typical Use Cases | Social networks, fraud detection, recommendation systems | IoT sensor data, performance monitoring, financial market analysis |
| Indexing | Index on nodes and relationships | Time-based indexes optimized for fast range queries |
| Scalability | Optimized for complex relationship queries, moderate scalability | Highly scalable for high-frequency, high-volume time-stamped data |
| Examples | Neo4j, Amazon Neptune, JanusGraph | InfluxDB, TimescaleDB, OpenTSDB |
Introduction to Graph Databases and Time-series Databases
Graph databases excel in managing complex relationships by storing data as nodes and edges, enabling efficient querying of interconnected information such as social networks and recommendation systems. Time-series databases specialize in handling sequential data points indexed by time, optimizing storage and retrieval of metrics for applications like IoT monitoring and financial analysis. Both database types leverage tailored schemas and indexing to enhance performance for their specific data models and use cases.
Core Concepts: Nodes vs. Timestamps
Graph databases organize data around nodes and edges, emphasizing relationships and connections between entities for complex network analysis. Time-series databases structure data based on timestamps, optimizing the storage and retrieval of temporal sequences and trends. While graph databases excel in dynamic relationship mapping, time-series databases are specialized in handling chronological data efficiently.
Data Modeling: Relationships vs. Temporal Patterns
Graph databases excel in data modeling by representing complex relationships through nodes and edges, enabling efficient traversal and querying of interconnected data. Time-series databases focus on capturing temporal patterns by organizing data points with timestamps, optimizing for high-speed ingestion and time-based aggregations. While graph databases prioritize relationship dynamics and network topology, time-series databases emphasize chronological ordering and trends over time.
Performance and Scalability Considerations
Graph databases excel in handling complex, interconnected data with rapid traversal speeds, making them highly performant for queries involving relationships and network patterns. Time-series databases optimize write throughput and compression for massive volumes of sequential data, delivering efficient storage and retrieval of time-stamped events. Scalability in graph databases often requires sharding strategies to manage relationship density, whereas time-series databases scale horizontally through partitioning time ranges across distributed nodes.
Query Languages and Operations
Graph databases utilize query languages like Cypher and Gremlin, designed to efficiently traverse and analyze complex relationships and network patterns within interconnected data. Time-series databases employ query languages such as InfluxQL and Flux, optimized for time-stamped data retrieval, aggregation, and downsampling across temporal intervals. Operations in graph databases focus on pathfinding, pattern matching, and relationship analytics, whereas time-series databases specialize in time-window queries, trend detection, and real-time monitoring of chronological data.
Use Cases: When to Choose Graph vs. Time-series
Graph databases excel in use cases involving complex relationships and networked data, such as social networks, recommendation engines, and fraud detection, where querying connections and patterns is crucial. Time-series databases are ideal for scenarios requiring high-volume, sequential data storage and analysis, including IoT sensor data, financial market tracking, and server performance monitoring, where timestamped data points are essential. Choose graph databases for relationship-centric queries and time-series databases for chronological data analysis to optimize performance and insights.
Storage Architecture and Data Compression
Graph databases use nodes, edges, and properties to represent and store complex relationships, optimizing storage architecture for connected data traversal and querying. Time-series databases organize data sequentially by timestamps, employing specialized compression techniques such as delta encoding and Gorilla compression to efficiently handle high write throughput and reduce storage footprint. Differences in storage architecture reflect their primary use cases: graph databases focus on relationship integrity and fast joins, while time-series databases prioritize efficient, compact storage of large volumes of time-stamped data.
Integration with Analytics and Visualization Tools
Graph databases excel in integrating with analytics and visualization tools by offering intuitive graph traversal and relationship-focused insights, enabling complex queries on interconnected data that enhance pattern detection and network analysis. Time-series databases optimize integration with analytics platforms through efficient storage and querying of high-frequency temporal data, supporting real-time anomaly detection, trend analysis, and forecasting. Both database types provide specialized connectors and APIs compatible with BI tools like Grafana, Tableau, and Power BI, but graph databases emphasize relational data visualization while time-series databases prioritize temporal data representation.
Security and Access Control Features
Graph databases offer robust role-based access control and fine-grained permission settings that enforce data visibility at the node and edge levels, enhancing security in complex relationship queries. Time-series databases prioritize secure data ingestion and retention policies with encryption at rest and in transit, while often supporting multi-tenant access control to isolate time-series data streams. Both database types implement authentication and authorization mechanisms tailored to their data models, but graph databases typically provide more granular access control critical for interconnected data security.
Future Trends in Graph and Time-series Databases
Graph databases are evolving to support increasingly complex relationship queries and real-time analytics, driven by advancements in AI integration and distributed computing architectures. Time-series databases are focusing on enhanced scalability and improved anomaly detection capabilities through machine learning models to handle the explosion of IoT and sensor data. Both database types are converging on hybrid solutions that optimize for temporal and relational data, enabling more sophisticated predictive analytics and real-time decision-making in industries like finance, healthcare, and telecommunications.
Graph Database Infographic