Databases are essential tools for efficiently storing, managing, and retrieving vast amounts of information across various applications. Understanding the fundamentals of database structures, query languages, and optimization techniques can significantly enhance your data handling capabilities. Explore the rest of this article to dive deeper into database concepts and improve your data management skills.
Table of Comparison
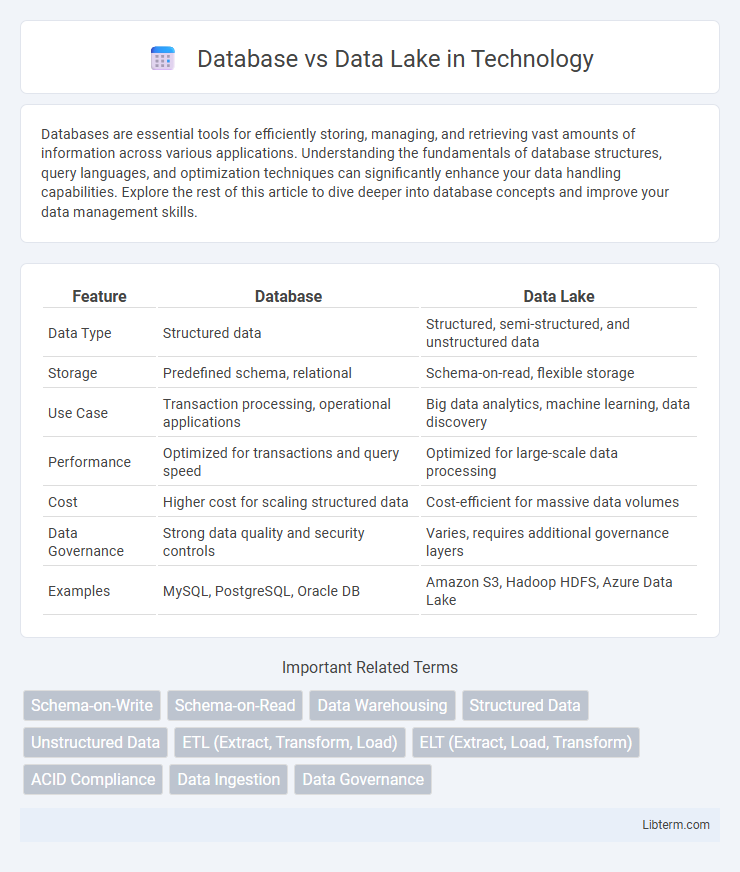
| Feature | Database | Data Lake |
|---|---|---|
| Data Type | Structured data | Structured, semi-structured, and unstructured data |
| Storage | Predefined schema, relational | Schema-on-read, flexible storage |
| Use Case | Transaction processing, operational applications | Big data analytics, machine learning, data discovery |
| Performance | Optimized for transactions and query speed | Optimized for large-scale data processing |
| Cost | Higher cost for scaling structured data | Cost-efficient for massive data volumes |
| Data Governance | Strong data quality and security controls | Varies, requires additional governance layers |
| Examples | MySQL, PostgreSQL, Oracle DB | Amazon S3, Hadoop HDFS, Azure Data Lake |
Introduction to Databases and Data Lakes
Databases store structured data in organized tables optimized for transactional processing and quick queries, essential for applications requiring data consistency and integrity. Data lakes hold vast amounts of raw, unstructured, or semi-structured data, enabling flexible analytics and machine learning across diverse data types. The key distinction lies in databases managing highly organized data schemas, while data lakes provide scalable storage for multi-format data with schema-on-read capabilities.
Key Differences Between Databases and Data Lakes
Databases store structured data in predefined schemas optimized for transactional processing and complex queries, supporting ACID properties for data integrity. Data lakes handle vast amounts of raw, unstructured, and semi-structured data at scale, enabling flexible storage without rigid schemas and supporting big data analytics and machine learning use cases. While databases excel in operational efficiency and consistency, data lakes prioritize scalability and diverse data ingestion for exploratory analysis.
Data Structure and Storage Methods
Databases organize data into structured tables with predefined schemas, enabling efficient querying through relational frameworks, whereas data lakes store raw, unstructured, and semi-structured data in its native format, often using distributed file systems. Database storage relies on optimized row or column-based storage engines to ensure fast transaction processing, while data lakes leverage scalable object storage designed for large volumes of diverse data types. The schema-on-write approach in databases contrasts with the schema-on-read flexibility in data lakes, allowing the latter to accommodate evolving data structures and analytics needs.
Use Cases: When to Use a Database vs. Data Lake
Databases are ideal for transactional applications requiring structured data storage, fast query performance, and ACID compliance, such as e-commerce platforms, financial systems, and customer relationship management (CRM) tools. Data lakes excel in storing vast amounts of raw, unstructured, or semi-structured data from diverse sources, making them suitable for big data analytics, machine learning projects, and data archiving. Organizations leverage data lakes for exploratory data analysis and real-time streaming data ingestion, while databases are preferred for operational reporting and consistent data access.
Scalability and Performance Comparison
Databases typically offer optimized query performance with structured data and predefined schemas, but they may face scalability limitations when handling massive or unstructured datasets. Data lakes provide high scalability by storing vast amounts of raw, unstructured, and semi-structured data across distributed storage systems, enabling flexible schema-on-read processing. Performance in data lakes depends on architecture and processing frameworks, often requiring additional tools like Apache Spark or Presto to achieve efficient querying and analytics at scale.
Data Processing and Analytics Capabilities
Databases offer structured data storage optimized for transactional processing and support complex queries with ACID compliance, enabling precise analytics on well-defined schemas. Data lakes store vast volumes of raw, unstructured, or semi-structured data, supporting diverse data types and big data analytics through schema-on-read and advanced processing frameworks like Apache Spark. Their flexibility allows real-time and batch analytics but may require more advanced tools for data governance and integration compared to traditional databases.
Security and Compliance Considerations
Databases offer structured data storage with granular access controls and transaction consistency, supporting stringent security measures such as encryption at rest and in transit, role-based access control (RBAC), and audit logging, which are critical for compliance with regulations like GDPR and HIPAA. Data lakes, while flexible for large-scale unstructured data, often require enhanced security frameworks including data classification, schema enforcement, and integration with identity and access management (IAM) systems to address potential vulnerabilities and ensure compliance. Effective governance in both environments involves continuous monitoring, policy enforcement, and ensuring data lineage to mitigate risks associated with unauthorized access and data breaches.
Cost Implications: Database vs. Data Lake
Databases typically involve higher upfront costs due to licensing fees, structured schema design, and ongoing maintenance expenses, which can escalate with scaling. Data lakes, leveraging low-cost storage solutions like object storage on cloud platforms, offer more economical options for storing vast amounts of raw, unstructured data but may incur costs related to data processing and governance tools. Choosing between a database and a data lake requires analyzing total cost of ownership, including infrastructure, operational management, and performance requirements for specific data use cases.
Integration with Big Data and AI Technologies
Databases offer structured data storage optimized for transactional processing, but their rigid schemas limit seamless integration with diverse big data and AI workloads. Data lakes store vast amounts of raw, unstructured, and semi-structured data, enabling flexible access for machine learning models and advanced analytics across heterogeneous sources. Integrating AI technologies with data lakes accelerates insight extraction by leveraging scalable storage and processing frameworks like Hadoop and Spark.
Choosing the Right Solution for Your Organization
Choosing the right solution between a database and a data lake depends on your organization's data structure and usage requirements. Databases excel in storing structured data with predefined schemas, supporting efficient transaction processing and queries, making them ideal for operational applications. Data lakes offer scalable storage for vast amounts of raw, unstructured, or semi-structured data, enabling advanced analytics, machine learning, and flexibility in data exploration across varied data sources.
Database Infographic