Low cardinality refers to a data attribute containing a limited number of unique values, often seen in categorical variables like gender or status fields. Managing low cardinality efficiently can improve database performance and reduce storage costs by optimizing indexing and compression techniques. Explore the rest of the article to learn how leveraging low cardinality can enhance your data handling strategies.
Table of Comparison
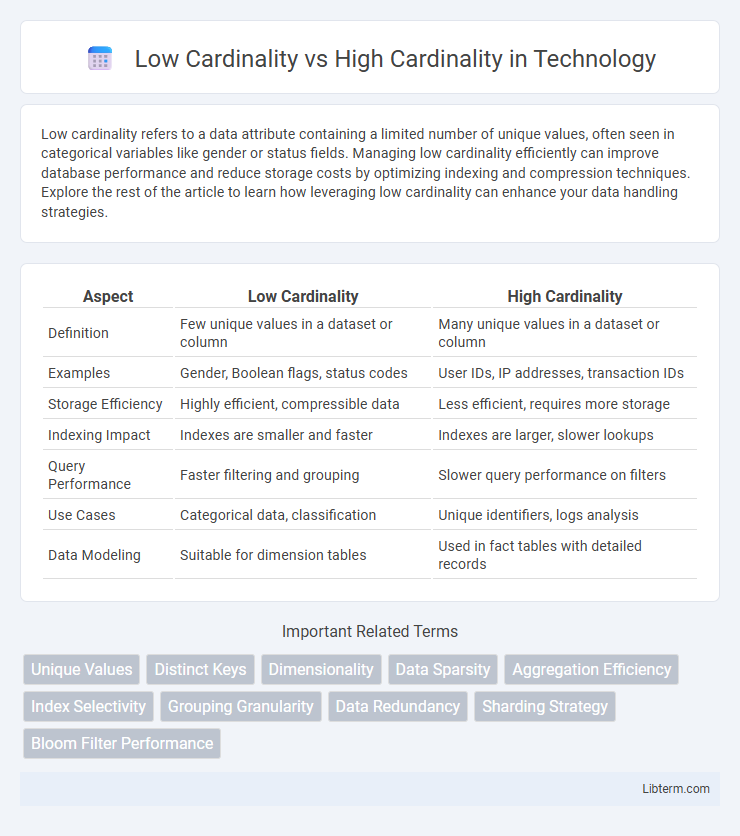
| Aspect | Low Cardinality | High Cardinality |
|---|---|---|
| Definition | Few unique values in a dataset or column | Many unique values in a dataset or column |
| Examples | Gender, Boolean flags, status codes | User IDs, IP addresses, transaction IDs |
| Storage Efficiency | Highly efficient, compressible data | Less efficient, requires more storage |
| Indexing Impact | Indexes are smaller and faster | Indexes are larger, slower lookups |
| Query Performance | Faster filtering and grouping | Slower query performance on filters |
| Use Cases | Categorical data, classification | Unique identifiers, logs analysis |
| Data Modeling | Suitable for dimension tables | Used in fact tables with detailed records |
Understanding Cardinality in Data
Cardinality in data refers to the uniqueness of values contained in a column, with low cardinality indicating a limited set of distinct values and high cardinality representing a vast number of unique entries. Low cardinality is common in categorical data such as gender or boolean flags, enhancing compression and indexing performance. High cardinality often appears in identifiers like user IDs or timestamps, requiring optimized storage techniques to maintain query efficiency and reduce computational overhead.
Defining Low Cardinality
Low cardinality refers to datasets or columns containing a limited number of unique values relative to the total number of records, such as gender or boolean fields. This characteristic optimizes storage and query performance in databases by enabling efficient use of compression and indexing techniques. In contrast to high cardinality, which includes fields with numerous distinct values like user IDs or timestamps, low cardinality simplifies data analysis and enhances performance in aggregations and groupings.
Defining High Cardinality
High cardinality refers to a dataset column containing a large number of unique values, often approaching the total number of entries, such as user IDs or email addresses in a database. This characteristic poses challenges for data storage, indexing, and query performance due to the increased complexity in handling numerous distinct elements. Understanding high cardinality is essential for optimizing database design, improving search efficiency, and ensuring scalable data processing in applications with extensive and diverse datasets.
Examples of Low and High Cardinality
Low cardinality refers to columns with a limited number of unique values, such as gender (male, female) or Boolean fields (true, false), which simplify data grouping and indexing. High cardinality involves columns with a vast array of unique values, like user IDs, email addresses, or transaction IDs in large datasets, which can impact performance and storage. Examples of low cardinality include country codes or product categories, whereas examples of high cardinality include social security numbers or timestamps with millisecond precision.
Impact on Database Performance
Low cardinality columns, with fewer unique values, improve database performance by enabling efficient compression and faster indexing, reducing query execution time. High cardinality columns, featuring many unique values, often result in larger indexes and slower query performance due to increased I/O and less effective caching. Optimizing schema designs by balancing cardinality can significantly enhance storage efficiency and query responsiveness in relational databases.
Indexing Strategies for Cardinality
Low cardinality columns, containing a limited number of distinct values, benefit from bitmap indexing which provides efficient query performance with minimal storage overhead. High cardinality columns, with many unique values, perform better using B-tree or hash indexes that support rapid lookups and range queries without excessive index bloat. Choosing the appropriate indexing strategy according to cardinality optimizes query speed and resource utilization in database management systems.
Data Storage Considerations
Low cardinality data, characterized by a limited number of unique values, optimizes data storage by enabling efficient encoding techniques such as dictionary encoding and bitmaps, which reduce memory usage. High cardinality data, containing a vast array of unique values, typically demands more storage space and may require advanced compression algorithms or indexing strategies to manage large datasets effectively. Choosing the appropriate storage method depends on the cardinality level, influencing performance, retrieval speed, and overall database efficiency.
Query Optimization Techniques
Low cardinality columns, characterized by a limited number of unique values, enable efficient query optimization through bitmap indexing and compression techniques, reducing I/O and speeding up filtering operations. High cardinality columns contain numerous unique values, requiring advanced indexing strategies such as B-tree indexes or partitioning to maintain query performance and limit scan times. Query optimizers leverage statistics on cardinality to choose the most suitable execution plan, balancing index usage and data retrieval costs for optimized response times.
Use Cases for Different Cardinalities
Low cardinality is ideal for categorical data with a limited set of unique values, such as gender, status flags, or boolean fields, enabling efficient compression and faster query performance in databases and data warehouses. High cardinality suits data with numerous unique values, like user IDs, transaction numbers, or timestamps, supporting detailed analytics, personalized recommendations, and fraud detection by capturing granular information. Selecting cardinality depends on use cases emphasizing either compactness and speed for low cardinality or diversity and detail for high cardinality scenarios.
Choosing the Right Approach for Your Data
Low cardinality data, characterized by a limited set of distinct values, enables efficient compression and faster query performance in databases and analytics platforms. High cardinality data, containing many unique values, requires more storage and may benefit from indexing strategies or specialized data structures to maintain query speed. Choosing the right approach depends on the specific dataset's distribution, query patterns, and system capabilities to optimize both storage efficiency and retrieval performance.
Low Cardinality Infographic