High-dimensional data spaces often lead to sparse and less informative datasets, making analysis and machine learning tasks challenging due to the "curse of dimensionality." This phenomenon can degrade the performance of algorithms by increasing computational complexity and reducing the reliability of distance metrics. Explore the rest of the article to understand how you can overcome these obstacles and improve your data modeling processes.
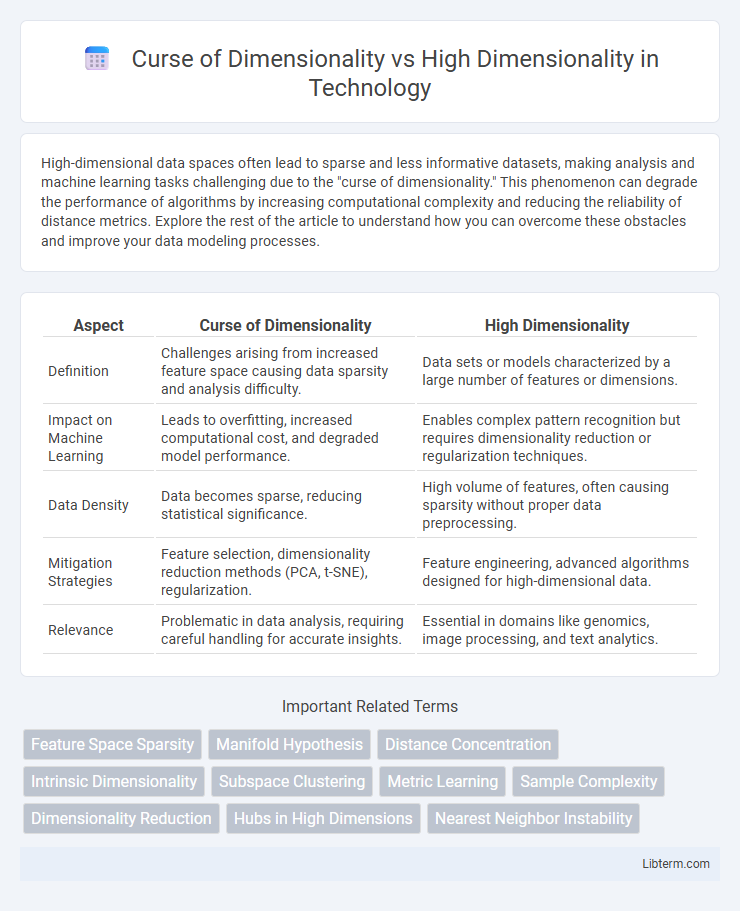
Table of Comparison
| Aspect | Curse of Dimensionality | High Dimensionality |
|---|---|---|
| Definition | Challenges arising from increased feature space causing data sparsity and analysis difficulty. | Data sets or models characterized by a large number of features or dimensions. |
| Impact on Machine Learning | Leads to overfitting, increased computational cost, and degraded model performance. | Enables complex pattern recognition but requires dimensionality reduction or regularization techniques. |
| Data Density | Data becomes sparse, reducing statistical significance. | High volume of features, often causing sparsity without proper data preprocessing. |
| Mitigation Strategies | Feature selection, dimensionality reduction methods (PCA, t-SNE), regularization. | Feature engineering, advanced algorithms designed for high-dimensional data. |
| Relevance | Problematic in data analysis, requiring careful handling for accurate insights. | Essential in domains like genomics, image processing, and text analytics. |
Introduction to Dimensionality in Data Analysis
Dimensionality in data analysis refers to the number of features or variables present in a dataset, directly impacting the complexity and interpretability of models. High dimensionality can lead to sparse data distributions, complicating pattern recognition and increasing computational challenges, often known as the Curse of Dimensionality. Understanding these concepts is crucial for selecting appropriate dimensionality reduction techniques and improving model performance.
Defining High Dimensionality
High dimensionality refers to datasets with a large number of features or attributes, often exceeding hundreds or thousands of dimensions. This complexity increases computational challenges and can lead to sparse data distributions, making traditional algorithms less effective. Understanding high dimensionality is crucial for developing methods that mitigate the curse of dimensionality, improving performance in machine learning and data analysis tasks.
Explaining the Curse of Dimensionality
The Curse of Dimensionality refers to the exponential increase in data sparsity and computational complexity as the number of dimensions or features in a dataset grows, leading to challenges in machine learning and data analysis. High dimensionality causes distances between data points to become less meaningful, reducing the effectiveness of algorithms like k-nearest neighbors and clustering. This phenomenon necessitates dimensionality reduction techniques such as PCA or t-SNE to improve model performance and interpretability.
Key Differences: Curse vs. High Dimensionality
The Curse of Dimensionality refers to the exponential increase in computational complexity and data sparsity as the number of features grows, leading to challenges in modeling and visualization. High Dimensionality simply describes datasets with a large number of attributes or variables without implying negative effects. The key difference lies in Curse of Dimensionality highlighting the practical obstacles in analysis, whereas High Dimensionality is a neutral descriptor of data characteristics.
Impact on Machine Learning Algorithms
High dimensionality in datasets often leads to the curse of dimensionality, where the volume of the feature space increases exponentially, causing data points to become sparse. This sparsity reduces the effectiveness of distance-based algorithms such as k-nearest neighbors and impacts the performance of models by increasing overfitting risks and computational complexity. Techniques like dimensionality reduction and feature selection are essential to mitigate these issues and improve the accuracy and efficiency of machine learning algorithms.
Effects on Data Visualization and Interpretation
High dimensionality complicates data visualization by increasing the number of features beyond human perceptual limits, leading to sparse data distributions and making meaningful patterns harder to identify. The curse of dimensionality exacerbates this challenge by causing distance measures to lose effectiveness, reducing the reliability of clustering and classification methods used in visual analysis. Dimensionality reduction techniques, such as PCA or t-SNE, become essential for transforming high-dimensional data into interpretable visual representations while preserving intrinsic structures.
Consequences for Model Performance
High dimensionality increases the risk of overfitting, as models capture noise rather than underlying patterns, reducing generalization performance on unseen data. The curse of dimensionality leads to sparse data distribution in high-dimensional spaces, making it difficult for algorithms to find meaningful clusters or decision boundaries. This sparsity causes increased computational complexity and degrades model accuracy, especially in distance-based methods like k-nearest neighbors and support vector machines.
Techniques for Mitigating Dimensionality Issues
Techniques for mitigating dimensionality issues include dimensionality reduction methods such as Principal Component Analysis (PCA), t-Distributed Stochastic Neighbor Embedding (t-SNE), and Autoencoders, which transform high-dimensional data into lower-dimensional spaces while preserving essential structures. Feature selection algorithms like Recursive Feature Elimination (RFE) and LASSO regression identify and retain the most informative features, reducing noise and computational complexity. Manifold learning approaches and regularization techniques further help combat the curse of dimensionality by capturing intrinsic data geometry and preventing overfitting in high-dimensional models.
Real-world Examples and Case Studies
High dimensionality often leads to the curse of dimensionality, where data sparsity increases exponentially, hindering machine learning model performance in fields like bioinformatics and image recognition. For instance, gene expression datasets with thousands of features per sample pose challenges for clustering algorithms, while face recognition systems struggle with high pixel dimensions causing overfitting and computation inefficiency. Case studies in marketing analytics reveal that feature selection techniques effectively mitigate the curse by reducing customer data dimensions, improving predictive accuracy and interpretability.
Conclusion: Navigating High and Problematic Dimensions
High dimensionality poses significant challenges due to the curse of dimensionality, where data sparsity and increased computational complexity degrade model performance. Effective techniques such as dimensionality reduction, feature selection, and regularization help navigate these issues by simplifying data representation and improving algorithm efficiency. Understanding the trade-offs between retaining information and reducing dimensionality is crucial for managing high-dimensional datasets in machine learning and data analysis.
Curse of Dimensionality Infographic