Feature selection improves model performance by identifying the most relevant variables and eliminating redundant or irrelevant data. This process reduces overfitting, enhances accuracy, and speeds up computation time in machine learning tasks. Explore the rest of the article to learn effective feature selection techniques that can boost your model's efficiency.
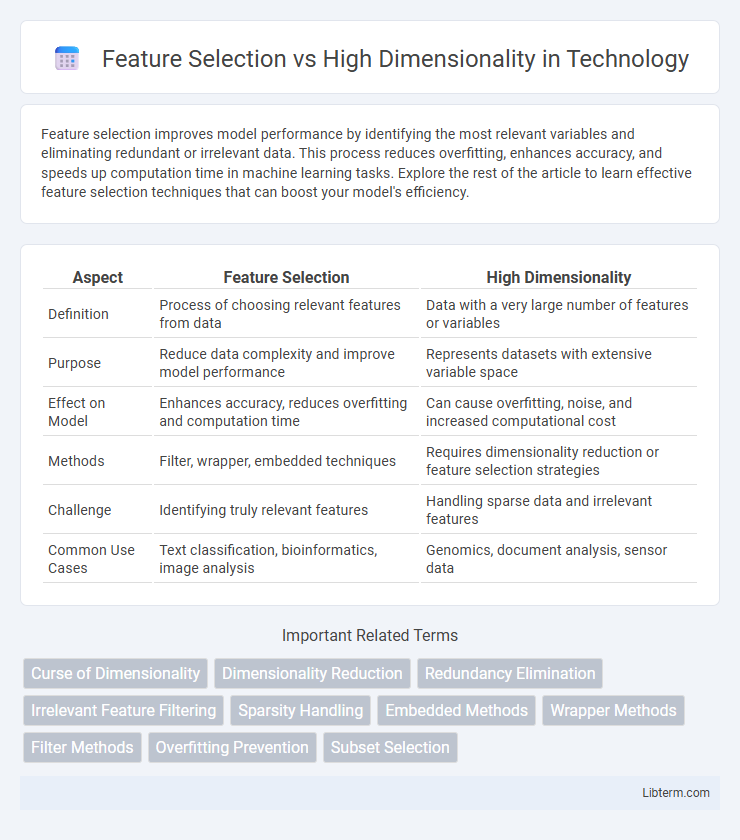
Table of Comparison
| Aspect | Feature Selection | High Dimensionality |
|---|---|---|
| Definition | Process of choosing relevant features from data | Data with a very large number of features or variables |
| Purpose | Reduce data complexity and improve model performance | Represents datasets with extensive variable space |
| Effect on Model | Enhances accuracy, reduces overfitting and computation time | Can cause overfitting, noise, and increased computational cost |
| Methods | Filter, wrapper, embedded techniques | Requires dimensionality reduction or feature selection strategies |
| Challenge | Identifying truly relevant features | Handling sparse data and irrelevant features |
| Common Use Cases | Text classification, bioinformatics, image analysis | Genomics, document analysis, sensor data |
Understanding Feature Selection: Definition and Importance
Feature selection involves identifying and selecting the most relevant variables from high-dimensional datasets to improve model performance and reduce computational complexity. In high-dimensionality scenarios, where datasets contain thousands of features, feature selection is critical to mitigate overfitting and enhance interpretability. Effective feature selection techniques optimize predictive accuracy while minimizing noise and redundancy in the data.
What is High Dimensionality in Data Science?
High dimensionality in data science refers to datasets with a large number of features or variables, often leading to challenges like the "curse of dimensionality," where the volume of the feature space grows exponentially with each added dimension. This complexity can cause overfitting, increased computational costs, and difficulty in visualizing and interpreting data patterns. Feature selection techniques help mitigate these issues by identifying and retaining the most relevant variables, enhancing model performance and interpretability in high-dimensional spaces.
Challenges Posed by High-Dimensional Data
High-dimensional data presents significant challenges such as increased computational complexity and the risk of overfitting in machine learning models. Feature selection techniques help mitigate these issues by identifying the most relevant variables, reducing noise and improving model interpretability. However, the curse of dimensionality often leads to sparse data distributions, making it difficult to discern meaningful patterns and necessitating advanced dimensionality reduction methods.
The Role of Feature Selection in Machine Learning
Feature selection plays a critical role in managing high-dimensional data by reducing the number of irrelevant or redundant features, which enhances model performance and interpretability. Techniques like recursive feature elimination, LASSO, and tree-based methods help identify the most informative variables, minimizing overfitting and computational complexity. Effective feature selection improves training speed, generalization accuracy, and supports better insights into the underlying data patterns in machine learning applications.
Common Feature Selection Techniques
Common feature selection techniques such as filter methods, wrapper methods, and embedded methods effectively address the challenges posed by high dimensionality in datasets by reducing irrelevant and redundant features. Filter methods evaluate the relevance of features using statistical measures like chi-square, mutual information, or correlation coefficients, which improves model performance and reduces computational cost. Wrapper methods, including recursive feature elimination and forward selection, utilize predictive models to assess feature subsets, while embedded methods like LASSO and decision tree algorithms integrate feature selection into the model training process for optimized dimensionality reduction.
Feature Selection vs. Dimensionality Reduction: Key Differences
Feature selection identifies the most relevant variables by evaluating their contribution to model performance, preserving original feature meaning, while dimensionality reduction transforms data into new feature spaces, often reducing interpretability. High dimensionality challenges like overfitting and increased computational cost motivate using both techniques but with different goals: feature selection emphasizes variable importance, whereas dimensionality reduction focuses on data compression and variance preservation. Principal Component Analysis (PCA) exemplifies dimensionality reduction by creating orthogonal components, whereas methods like Recursive Feature Elimination (RFE) highlight feature selection's direct approach to variable elimination.
Impact of High Dimensionality on Model Performance
High dimensionality often leads to the curse of dimensionality, causing sparse data distributions that degrade model generalization and increase overfitting risk. Feature selection reduces irrelevant or redundant features, enhancing model interpretability and boosting computational efficiency while mitigating noise. Consequently, effective dimensionality reduction improves prediction accuracy and stabilizes model training in complex datasets.
Strategies to Handle the Curse of Dimensionality
Effective strategies to handle the curse of dimensionality involve feature selection techniques such as filter methods using mutual information and variance thresholds, wrapper methods leveraging recursive feature elimination, and embedded methods like LASSO regression that incorporate feature selection within model training. Dimensionality reduction techniques like Principal Component Analysis (PCA) and t-Distributed Stochastic Neighbor Embedding (t-SNE) also address high dimensionality by transforming features into lower-dimensional spaces while preserving data variance or structure. Combining feature selection with dimensionality reduction optimizes computational efficiency and model generalization by reducing redundancy and noise in datasets with thousands of features.
Best Practices for Effective Feature Selection
Effective feature selection addresses the challenges of high dimensionality by identifying the most relevant variables, reducing noise, and improving model interpretability. Techniques such as recursive feature elimination, mutual information, and L1 regularization help prioritize features that contribute significantly to predictive performance. Applying cross-validation and domain knowledge ensures robust feature subsets, preventing overfitting and enhancing generalization in complex datasets.
Future Trends in Feature Selection and High Dimensionality
Future trends in feature selection emphasize the integration of deep learning techniques with traditional statistical methods to effectively handle high dimensionality in datasets. Advances in automated machine learning (AutoML) and explainable AI (XAI) are driving the development of more efficient and interpretable feature selection algorithms. Emerging research focuses on scalable methods that reduce computational complexity while maintaining predictive accuracy in ultra-high-dimensional data scenarios common in genomics and big data analytics.
Feature Selection Infographic