Anomaly detection is a critical technique in data analysis that identifies unusual patterns or outliers in datasets, helping to prevent fraud, detect faults, and improve system security. By leveraging machine learning algorithms and statistical methods, it ensures that deviations from expected behavior are spotted early, minimizing potential risks. Explore the rest of the article to learn how you can implement effective anomaly detection strategies for your data needs.
Table of Comparison
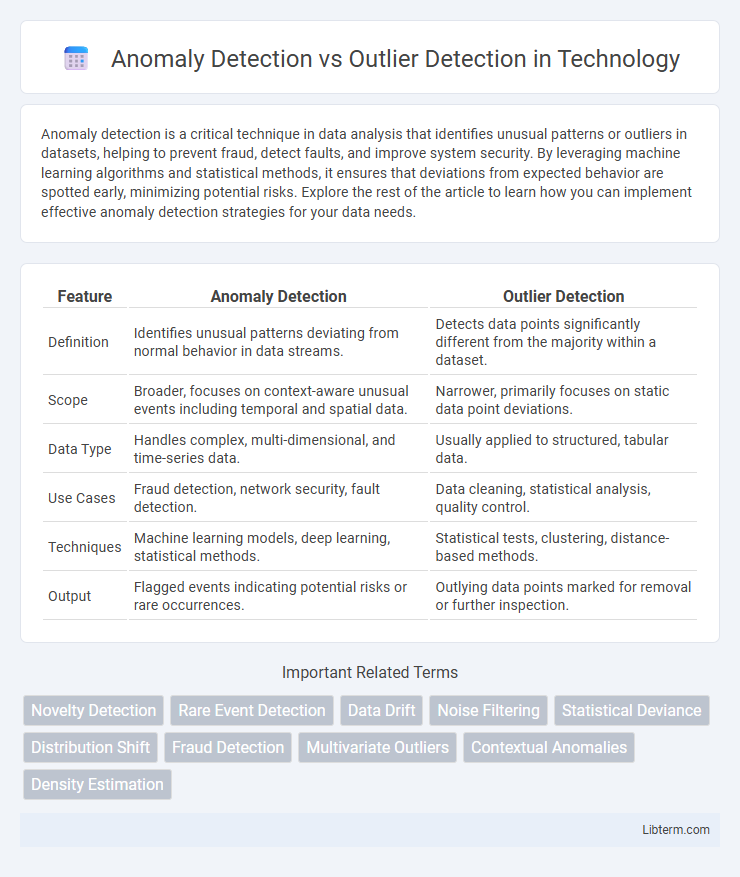
| Feature | Anomaly Detection | Outlier Detection |
|---|---|---|
| Definition | Identifies unusual patterns deviating from normal behavior in data streams. | Detects data points significantly different from the majority within a dataset. |
| Scope | Broader, focuses on context-aware unusual events including temporal and spatial data. | Narrower, primarily focuses on static data point deviations. |
| Data Type | Handles complex, multi-dimensional, and time-series data. | Usually applied to structured, tabular data. |
| Use Cases | Fraud detection, network security, fault detection. | Data cleaning, statistical analysis, quality control. |
| Techniques | Machine learning models, deep learning, statistical methods. | Statistical tests, clustering, distance-based methods. |
| Output | Flagged events indicating potential risks or rare occurrences. | Outlying data points marked for removal or further inspection. |
Introduction to Anomaly and Outlier Detection
Anomaly detection identifies patterns in data that deviate significantly from the expected behavior, often signaling critical issues such as fraud, network intrusions, or system failures. Outlier detection focuses on finding data points that are statistically distant from the rest of the dataset, which may indicate measurement errors, rare events, or novel phenomena. Both techniques utilize statistical, machine learning, and data mining methods to analyze datasets for unusual observations important in domains like cybersecurity, finance, and healthcare.
Defining Anomalies vs. Outliers
Anomalies refer to patterns in data that deviate significantly from expected behavior, often indicating critical issues or rare events within complex datasets. Outliers represent individual data points that differ markedly from other observations, typically caused by measurement errors, variability, or noise. Distinguishing anomalies involves context-aware analysis to identify unusual occurrences, while outlier detection focuses primarily on statistical deviation from normal data distributions.
Key Differences Between Anomaly Detection and Outlier Detection
Anomaly detection identifies patterns in data that deviate significantly from expected behavior, often indicating rare events or critical issues, whereas outlier detection focuses on finding data points that are statistically distant from the majority of the dataset. Anomalies are context-dependent and may represent meaningful deviations requiring action, while outliers can sometimes be noise or errors without significant impact. Anomaly detection typically involves modeling normal behavior to detect deviations, whereas outlier detection relies more on statistical measures and distance-based metrics to spot isolated points.
Importance in Data Science and Analytics
Anomaly detection and outlier detection are critical techniques in data science and analytics for identifying unusual patterns that deviate from expected behavior, enabling the prevention of fraud, system failures, and data quality issues. While outlier detection focuses on statistical deviations in datasets, anomaly detection encompasses a broader range of irregularities often tied to contextual and temporal factors, enhancing predictive maintenance and cybersecurity applications. Effective implementation of these methods improves decision-making accuracy, operational efficiency, and risk management in various industries.
Techniques for Anomaly Detection
Techniques for anomaly detection include machine learning methods such as supervised learning with labeled data, unsupervised models like autoencoders and clustering algorithms, and statistical approaches including Gaussian mixture models and hypothesis testing. These techniques identify patterns that deviate significantly from the norm in time-series data, network traffic, or sensor readings. Unlike outlier detection, which mainly isolates extreme values, anomaly detection focuses on recognizing complex irregularities that may indicate system faults or fraud.
Methods for Outlier Detection
Outlier detection methods commonly include statistical approaches such as Z-score and Grubbs' test, distance-based techniques like k-Nearest Neighbors (k-NN), and density-based methods including Local Outlier Factor (LOF). Machine learning algorithms, such as Isolation Forest and One-Class SVM, enable efficient identification of outliers in high-dimensional data. Robust clustering algorithms and ensemble methods also enhance detection accuracy by capturing subtle deviations in complex datasets.
Common Applications and Use Cases
Anomaly detection and outlier detection both identify data points that deviate from normal patterns but differ in context and complexity of use cases. Anomaly detection is widely used in cybersecurity for identifying fraudulent activities and network intrusions, as well as in industrial monitoring to detect equipment failures early. Outlier detection finds applications in finance for spotting unusual transactions, in data cleaning to improve model accuracy, and in healthcare for identifying rare disease cases or measurement errors.
Challenges and Limitations
Anomaly detection faces challenges in handling high-dimensional data and distinguishing between rare but legitimate patterns and true anomalies, leading to potential false positives. Outlier detection struggles with defining clear boundaries in noisy datasets, often resulting in misclassification of valid variations as outliers. Both techniques require careful feature selection and domain knowledge to improve accuracy and reduce computational complexity.
Best Practices for Accurate Detection
Effective anomaly detection relies on advanced machine learning algorithms such as Isolation Forests and Autoencoders, which capture complex data patterns beyond simple statistical deviations used in traditional outlier detection methods like Z-score or IQR. Incorporating domain knowledge and continuous model training with labeled datasets enhances accuracy by reducing false positives and adapting to evolving data distributions. Data preprocessing techniques such as normalization, feature engineering, and handling missing values play a crucial role in improving the performance of both anomaly and outlier detection systems.
Future Trends in Detection Technologies
Future trends in anomaly detection and outlier detection technologies emphasize the integration of advanced machine learning models like deep learning and reinforcement learning to improve accuracy and real-time processing. Innovations in explainable AI (XAI) are enhancing interpretability, enabling better understanding of detected anomalies in complex datasets such as IoT sensor streams and cybersecurity logs. Edge computing and federated learning are increasingly adopted to enable decentralized anomaly detection, reducing latency and preserving data privacy in critical applications.
Anomaly Detection Infographic