The Bulkhead Pattern is a crucial design strategy in software architecture that isolates components to prevent failures from cascading across an entire system. By creating independent partitions or compartments, it enhances system resilience and maintains functionality even when parts encounter issues. Explore the rest of this article to understand how implementing the Bulkhead Pattern can safeguard your applications and improve reliability.
Table of Comparison
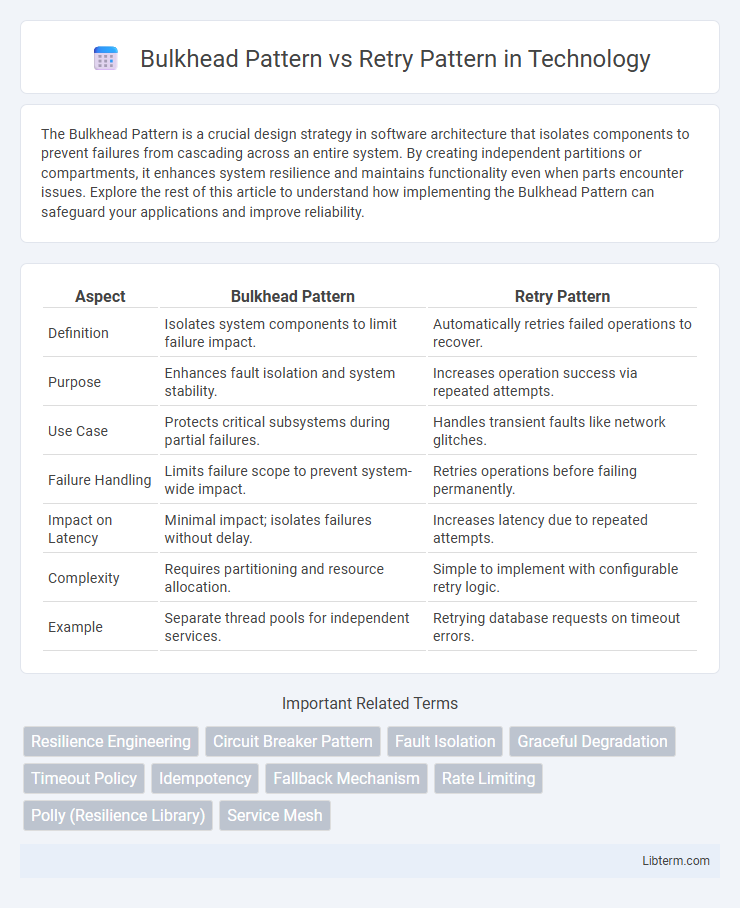
| Aspect | Bulkhead Pattern | Retry Pattern |
|---|---|---|
| Definition | Isolates system components to limit failure impact. | Automatically retries failed operations to recover. |
| Purpose | Enhances fault isolation and system stability. | Increases operation success via repeated attempts. |
| Use Case | Protects critical subsystems during partial failures. | Handles transient faults like network glitches. |
| Failure Handling | Limits failure scope to prevent system-wide impact. | Retries operations before failing permanently. |
| Impact on Latency | Minimal impact; isolates failures without delay. | Increases latency due to repeated attempts. |
| Complexity | Requires partitioning and resource allocation. | Simple to implement with configurable retry logic. |
| Example | Separate thread pools for independent services. | Retrying database requests on timeout errors. |
Introduction to Resilience Patterns
Bulkhead Pattern isolates system components to prevent failure in one part from cascading throughout the entire application, enhancing overall stability by containing faults. Retry Pattern improves reliability by automatically reattempting failed operations, masking transient errors and reducing the impact of temporary issues. Both patterns are fundamental resilience strategies that help maintain system availability and performance under stress or partial failure conditions.
Overview of Bulkhead Pattern
The Bulkhead Pattern isolates different components or services within a system to prevent cascading failures by partitioning resources such as threads or connections. This approach ensures that faults in one part do not consume all shared resources, thereby maintaining overall system stability and availability. Implementing bulkheads optimizes fault tolerance and improves resilience in distributed architectures.
Overview of Retry Pattern
The Retry Pattern improves system reliability by automatically reattempting failed operations based on predefined rules such as maximum retry count and backoff strategies. It is commonly used to handle transient faults in distributed systems, ensuring temporary issues like network glitches or service unavailability don't cause permanent failures. Proper implementation of the Retry Pattern reduces error rates and enhances user experience without overwhelming the system.
Key Differences Between Bulkhead and Retry Patterns
The Bulkhead Pattern isolates system components to prevent cascading failures by limiting resource allocation for each service, enhancing overall system resilience. In contrast, the Retry Pattern focuses on reattempting failed operations to overcome transient faults, improving reliability but potentially increasing system load. The key difference lies in Bulkhead preventing system-wide impact through isolation, while Retry aims to achieve successful execution by repeated attempts.
Use Cases for Bulkhead Pattern
The Bulkhead Pattern is primarily used to isolate critical components or services in distributed systems to prevent cascading failures and ensure system resilience under high load. It is ideal for scenarios where different services or tenants share infrastructure but require fault isolation to maintain availability, such as in microservices architectures or multi-tenant cloud platforms. In contrast to the Retry Pattern, which focuses on handling transient faults by reattempting operations, the Bulkhead Pattern safeguards system stability by limiting resource consumption and containing failures within defined boundaries.
Use Cases for Retry Pattern
Retry Pattern is essential in distributed systems where transient faults such as network timeouts or temporary service unavailability occur frequently, ensuring higher reliability by automatically reattempting failed operations. It is commonly used in database transactions, API calls, and microservices communication to handle intermittent errors without user intervention. This pattern improves application resilience by reducing failure rates and enhancing user experience through seamless recovery from transient issues.
Advantages of Bulkhead Pattern
The Bulkhead Pattern enhances system resilience by isolating failures within individual components, preventing a single fault from cascading across the entire application. It optimizes resource allocation by partitioning system capacity, ensuring critical services remain operational even under high load or failure conditions. This pattern improves overall reliability and availability by containing faults and managing dependencies more effectively than the Retry Pattern, which primarily focuses on transient error recovery.
Advantages of Retry Pattern
The Retry Pattern enhances application resilience by automatically attempting failed operations, reducing transient errors' impact on user experience. It improves system stability and reliability by allowing temporary glitches, like network timeouts or service unavailability, to be resolved without immediate failure. This pattern helps maintain seamless connectivity and minimizes service disruptions, especially in distributed and microservices architectures.
When to Choose Bulkhead vs Retry
Choose the Bulkhead Pattern when isolating system components to prevent cascading failures and ensure fault tolerance in distributed architectures. Opt for the Retry Pattern to handle transient faults by automatically reattempting failed operations within a short timeframe. Use Bulkhead for long-lasting failures affecting specific resources, while Retry suits temporary glitches or intermittent network issues.
Best Practices for Implementing Resilience Patterns
Implementing the Bulkhead Pattern involves isolating system components or resources to prevent cascading failures by limiting the impact of faults within bounded compartments, ensuring that one failing service does not exhaust shared resources. The Retry Pattern requires careful configuration of retry limits, backoff strategies, and idempotency to avoid overwhelming services with repeated requests and to handle transient faults gracefully. Best practices for resilience include combining both patterns where Bulkheads isolate failure domains while Retries handle transient errors efficiently, optimizing resource management and reducing system downtime.
Bulkhead Pattern Infographic