Compression reduces file size by removing redundant data while maintaining quality to improve storage efficiency and faster transmission. Various algorithms like ZIP, RAR, and JPEG serve different purposes, optimizing data for documents, images, and videos. Explore the article to discover how compression can enhance Your digital experience and simplify file management.
Table of Comparison
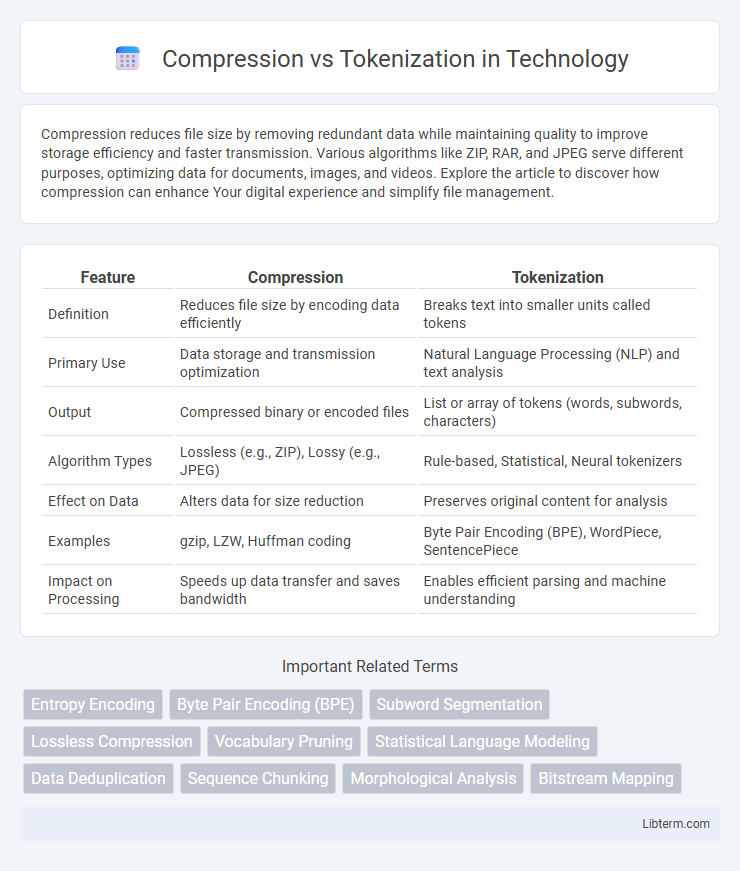
| Feature | Compression | Tokenization |
|---|---|---|
| Definition | Reduces file size by encoding data efficiently | Breaks text into smaller units called tokens |
| Primary Use | Data storage and transmission optimization | Natural Language Processing (NLP) and text analysis |
| Output | Compressed binary or encoded files | List or array of tokens (words, subwords, characters) |
| Algorithm Types | Lossless (e.g., ZIP), Lossy (e.g., JPEG) | Rule-based, Statistical, Neural tokenizers |
| Effect on Data | Alters data for size reduction | Preserves original content for analysis |
| Examples | gzip, LZW, Huffman coding | Byte Pair Encoding (BPE), WordPiece, SentencePiece |
| Impact on Processing | Speeds up data transfer and saves bandwidth | Enables efficient parsing and machine understanding |
Introduction to Compression and Tokenization
Compression reduces file size by encoding information more efficiently, using algorithms like Huffman coding or LZW to minimize storage and transmission costs. Tokenization breaks text into meaningful units called tokens, such as words or phrases, to facilitate natural language processing and data analysis. Both techniques improve data handling but serve distinct purposes: compression optimizes space, while tokenization structures textual data for semantic understanding.
Defining Data Compression
Data compression reduces file size by encoding information more efficiently, minimizing storage space and transmission time. It leverages algorithms like Huffman coding or Lempel-Ziv-Welch (LZW) to eliminate redundancies and represent data in a compact format. Unlike tokenization, which segments text into meaningful units for processing, compression focuses on optimizing data representation without altering content semantics.
Understanding Tokenization
Tokenization is the process of converting text into smaller units, called tokens, such as words or subwords, to enable efficient natural language processing. Unlike compression, which reduces data size by encoding information, tokenization prepares raw text for analysis by structuring language into manageable components for models. Effective tokenization improves language model understanding by capturing syntactic and semantic nuances, enhancing tasks like parsing, translation, and sentiment analysis.
Key Differences Between Compression and Tokenization
Compression reduces data size by encoding information more efficiently, focusing on minimizing storage or transmission requirements. Tokenization replaces sensitive data elements with non-sensitive tokens to protect privacy and secure information during processing. Unlike compression, tokenization does not reduce data size but enhances data security by masking original values.
Use Cases for Compression
Compression is widely used in data storage and transmission to reduce file size, optimizing bandwidth and saving space on devices. It is essential in multimedia applications, such as streaming high-definition videos and audio files, where minimizing latency and load times improves user experience. Compression techniques are also critical in cloud storage and backup solutions, enabling efficient management of large datasets.
Use Cases for Tokenization
Tokenization is crucial in natural language processing tasks, enabling models to break down text into manageable units such as words, subwords, or characters for efficient analysis and understanding. It supports applications like machine translation, sentiment analysis, and chatbots by ensuring text is accurately parsed and interpreted. Unlike compression, which reduces data size for storage or transmission, tokenization optimizes textual data for semantic processing and computational models.
Efficiency and Performance Comparison
Compression reduces data size by encoding information more compactly, improving storage efficiency and reducing transmission time, while tokenization breaks text into meaningful units for natural language processing, enhancing computational performance during text analysis. Compression algorithms like ZIP or GZIP optimize space utilization but require decompression overhead, whereas tokenization methods optimize processing speed by enabling faster parsing and indexing in machine learning models. The balance between compression and tokenization depends on specific use cases, where compression excels in minimizing data transfer costs and tokenization drives efficiency in language understanding and search tasks.
Security Implications of Each Approach
Compression reduces data size by encoding redundancies, which can obscure some information patterns but may still expose sensitive data if decompressed improperly. Tokenization replaces sensitive data with non-sensitive placeholders, significantly minimizing exposure risks since the original data is stored separately and accessed only via secure token vaults. Security implications favor tokenization for sensitive data protection due to its ability to isolate actual data from processing environments, reducing breach impacts compared to compression.
Choosing the Right Method for Your Needs
Choosing the right method between compression and tokenization depends on the specific requirements of your data management and security goals. Compression optimizes storage and speeds up data transmission by reducing file size, making it ideal for bandwidth-limited environments, while tokenization enhances data security and privacy by replacing sensitive information with non-sensitive placeholders, essential for compliance with regulations like PCI DSS or GDPR. Evaluate factors such as the need for data reversibility, processing speed, and regulatory compliance to determine whether compression or tokenization best aligns with your operational priorities.
Future Trends in Data Optimization
Future trends in data optimization emphasize enhanced compression algorithms integrating semantic tokenization to reduce redundancy and improve processing efficiency. Advances in AI-driven tokenization enable context-aware data encoding, facilitating more effective compression by understanding linguistic and structural data patterns. The convergence of compression and tokenization techniques promises scalable, real-time optimization for big data and edge computing environments.
Compression Infographic