Graph databases store and manage data by representing entities as nodes and relationships as edges, enabling efficient handling of complex and interconnected information. This structure excels in applications like social networks, recommendation systems, and fraud detection, where relationships are as critical as the data itself. Discover how leveraging graph databases can transform your data strategy by reading the full article.
Table of Comparison
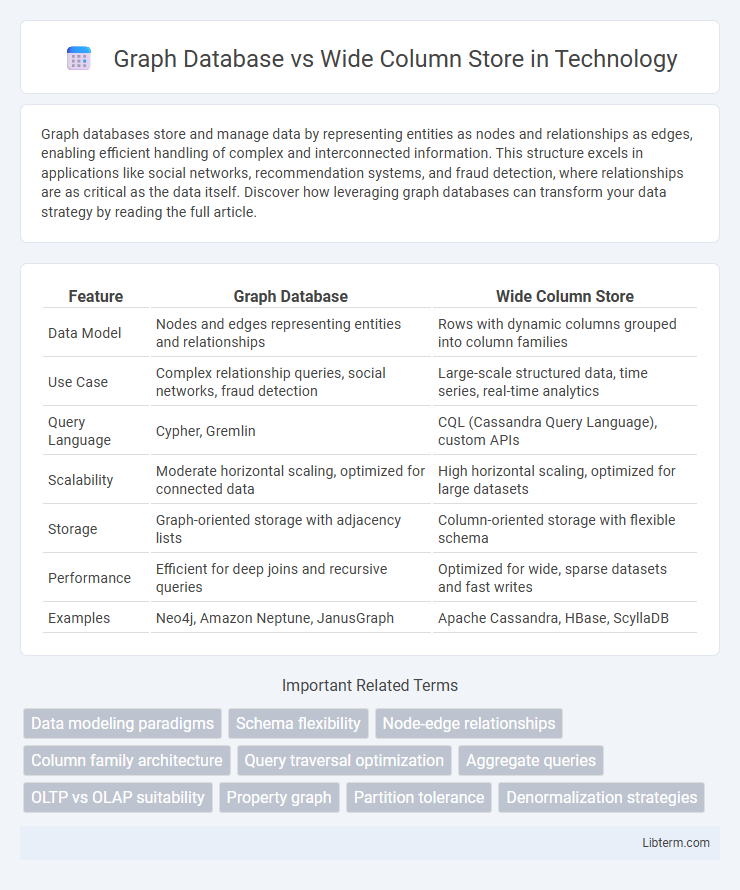
| Feature | Graph Database | Wide Column Store |
|---|---|---|
| Data Model | Nodes and edges representing entities and relationships | Rows with dynamic columns grouped into column families |
| Use Case | Complex relationship queries, social networks, fraud detection | Large-scale structured data, time series, real-time analytics |
| Query Language | Cypher, Gremlin | CQL (Cassandra Query Language), custom APIs |
| Scalability | Moderate horizontal scaling, optimized for connected data | High horizontal scaling, optimized for large datasets |
| Storage | Graph-oriented storage with adjacency lists | Column-oriented storage with flexible schema |
| Performance | Efficient for deep joins and recursive queries | Optimized for wide, sparse datasets and fast writes |
| Examples | Neo4j, Amazon Neptune, JanusGraph | Apache Cassandra, HBase, ScyllaDB |
Introduction to Graph Databases and Wide Column Stores
Graph databases organize data as interconnected nodes and edges, enabling efficient representation and querying of complex relationships, ideal for social networks and recommendation systems. Wide column stores, such as Apache Cassandra and HBase, structure data into flexible, scalable tables with rows and dynamic columns, optimized for high write throughput and large-scale distributed storage. Each model offers distinct advantages based on the nature of data and query patterns, with graph databases excelling in relationship-heavy datasets, while wide column stores provide performance benefits for vast, sparse datasets.
Core Concepts: Data Modeling Differences
Graph databases model data using nodes, edges, and properties to represent highly interconnected entities and relationships, optimizing traversals and complex queries across relationships. Wide column stores organize data into rows and dynamic columns grouped into column families, designed for scalability and fast querying on large datasets with sparse attributes. The fundamental difference lies in graph databases focusing on relationship-centric models while wide column stores prioritize flexible, tabular storage for distributed data processing.
Performance Comparison: Query Speed and Scalability
Graph databases excel in handling complex relationship queries with high-speed traversals due to their optimized graph structures, making them ideal for connected data scenarios. Wide column stores offer superior scalability for massive datasets by distributing data across multiple nodes, ensuring consistent query performance for wide and sparse tables. Query speed in graph databases outperforms wide column stores in deep link analysis, while wide column stores achieve faster retrieval for large-scale, column-oriented data workloads.
Use Cases: When to Choose a Graph DB vs Wide Column Store
Graph databases excel in use cases involving complex relationships and network analysis, such as social networks, recommendation engines, fraud detection, and knowledge graphs, where traversing and querying connections is critical. Wide column stores are ideal for handling large-scale, sparse data sets with variable schema, supporting time-series data, IoT applications, and real-time analytics that require high write throughput and horizontal scalability. Choose a graph database when data relationships drive insights, and a wide column store when managing massive volumes of distributed, semi-structured data with fast, flexible access patterns.
Data Relationships: How Connections are Handled
Graph databases excel at representing and querying complex data relationships through nodes and edges, enabling efficient traversal of connected data such as social networks or recommendation systems. Wide column stores handle relationships by embedding related data within rows or columns but lack native support for direct connections, often requiring additional application logic for relationship management. This makes graph databases more suited for scenarios with intricate, dynamic connections, while wide column stores prioritize scalability for large, sparse datasets.
Scalability and Distributed Architecture
Graph databases leverage distributed architecture by partitioning graph data across multiple nodes, enabling efficient querying of relationships at scale and maintaining low-latency access for complex traversals. Wide column stores provide high scalability through horizontal scaling and data distribution across large clusters, optimizing for read and write throughput with data organized in flexible, sparse columns. While graph databases excel in relationship-centric queries with dynamic schema, wide column stores prioritize massive scalability and fault tolerance for large, tabular datasets in distributed environments.
Consistency, Availability, and Partition Tolerance (CAP)
Graph databases prioritize consistency and partition tolerance by maintaining strict relationships and data integrity across distributed nodes, often sacrificing availability during network partitions to ensure accurate graph traversal and query results. Wide column stores emphasize availability and partition tolerance by enabling high scalability and fault tolerance across distributed systems, occasionally allowing eventual consistency to maintain performance and uptime. The CAP theorem trade-offs in graph databases lean towards CP systems, while wide column stores typically align with AP systems, reflecting their differing use cases and architectural designs.
Query Languages: Cypher, Gremlin, CQL, and Others
Graph databases primarily utilize query languages like Cypher and Gremlin, designed to efficiently navigate and manipulate graph structures by expressing complex relationships and traversals. Wide column stores leverage the Cassandra Query Language (CQL), optimized for querying large-scale, distributed, and columnar data with rapid read and write operations, though it lacks the graph-specific traversal capabilities. Other query languages, such as SPARQL for RDF stores and SQL for relational systems, differ in expressiveness and performance depending on data model requirements and query complexity.
Pros and Cons of Graph Databases
Graph databases excel at managing highly interconnected data and complex relationships, offering efficient querying through traversals and intuitive visualization of network structures. They provide flexibility in schema design and are ideal for use cases like social networks, recommendation engines, and fraud detection. However, graph databases may face challenges with scalability for massive datasets and can have higher resource consumption compared to wide column stores, which are optimized for large-scale, distributed, and sparse data storage.
Pros and Cons of Wide Column Stores
Wide column stores excel in handling large volumes of data with high write and read throughput due to their horizontal scalability and flexible schema design. They struggle with complex relationships and transactional consistency, making them less ideal for use cases requiring multi-row ACID transactions or graph traversal queries. Their optimized storage for sparse data and fast aggregation queries benefits analytics and time-series applications but limits their effectiveness in scenarios needing deep data interconnections.
Graph Database Infographic