Batch processing optimizes the execution of large volumes of data by grouping tasks together for efficient handling without manual intervention. This method increases throughput and reduces operational costs by automating repetitive tasks in manufacturing, data management, and computing environments. Dive into the rest of the article to discover how batch processing can transform your workflows and boost productivity.
Table of Comparison
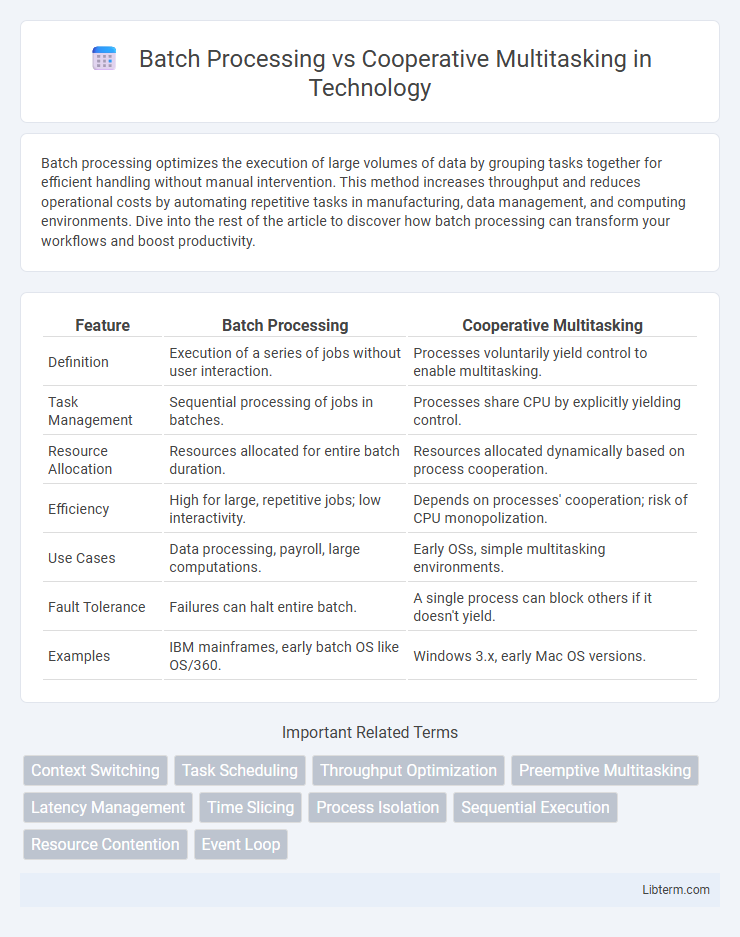
| Feature | Batch Processing | Cooperative Multitasking |
|---|---|---|
| Definition | Execution of a series of jobs without user interaction. | Processes voluntarily yield control to enable multitasking. |
| Task Management | Sequential processing of jobs in batches. | Processes share CPU by explicitly yielding control. |
| Resource Allocation | Resources allocated for entire batch duration. | Resources allocated dynamically based on process cooperation. |
| Efficiency | High for large, repetitive jobs; low interactivity. | Depends on processes' cooperation; risk of CPU monopolization. |
| Use Cases | Data processing, payroll, large computations. | Early OSs, simple multitasking environments. |
| Fault Tolerance | Failures can halt entire batch. | A single process can block others if it doesn't yield. |
| Examples | IBM mainframes, early batch OS like OS/360. | Windows 3.x, early Mac OS versions. |
Introduction to Batch Processing and Cooperative Multitasking
Batch processing organizes tasks into groups executed sequentially without user interaction, optimizing system resource utilization and throughput. Cooperative multitasking relies on processes voluntarily yielding control to enable shared CPU time, which can lead to inefficiencies if tasks fail to release control. Understanding these foundational differences is critical for designing operating systems that balance performance and responsiveness.
Core Concepts: Defining Batch Processing
Batch processing is a method of executing multiple jobs or tasks without manual intervention, where data and instructions are collected, processed, and completed as a single group. It is designed for efficiency in large-scale data handling, relying on sequential task execution rather than real-time interaction. This approach contrasts with cooperative multitasking, which requires active coordination among processes sharing CPU time.
Understanding Cooperative Multitasking
Cooperative multitasking relies on each running process to voluntarily yield control to allow multiple tasks to share CPU time, which can lead to system inefficiency if a process fails to release control. This method contrasts with batch processing, where tasks are executed sequentially without interactive user input, focusing on automating large workloads. Understanding cooperative multitasking is crucial for legacy systems that depend on process cooperation rather than preemptive scheduling to manage multitasking effectively.
Key Differences: Batch Processing vs Cooperative Multitasking
Batch processing executes multiple jobs sequentially without user interaction, optimizing system resource utilization for large-scale data tasks. Cooperative multitasking relies on each running process to voluntarily yield control, enabling multiple applications to share CPU time but risking system responsiveness if a process fails to yield. The main difference lies in control flow: batch processing is automatic and non-interactive, while cooperative multitasking depends on the cooperative behavior of processes to manage execution.
Workflow and Task Management
Batch processing organizes tasks into sequential, non-interactive jobs executed without user intervention, optimizing large-scale, repetitive workflows for efficiency. Cooperative multitasking relies on tasks voluntarily yielding control, requiring well-behaved processes to manage workflows interactively but risking system unresponsiveness if a task fails to yield. Effective task management in batch processing emphasizes job scheduling and resource allocation, while cooperative multitasking demands careful task synchronization and yield management to maintain system responsiveness.
System Resources and Performance
Batch processing maximizes system resource utilization by executing large volumes of jobs sequentially without user interaction, leading to high throughput but potential inefficiencies during I/O waits. Cooperative multitasking relies on processes voluntarily yielding control, which can cause resource underutilization and decreased performance if tasks fail to yield timely. Modern systems favor preemptive multitasking for improved responsiveness and balanced resource allocation over traditional batch and cooperative models.
Use Cases and Real-World Applications
Batch processing excels in large-scale data tasks like payroll systems, scientific simulations, and end-of-day financial reports where jobs run sequentially without user interaction. Cooperative multitasking suits interactive environments such as early desktop operating systems and embedded systems where tasks yield control voluntarily to share CPU time. Real-world applications of batch processing include banking transaction processing and data warehousing, while cooperative multitasking appears in legacy systems like early versions of Windows and classic Mac OS.
Advantages and Disadvantages of Each Approach
Batch processing excels in automating repetitive tasks without user interaction, increasing system efficiency and throughput for large data sets, but suffers from inflexibility and delayed feedback, making real-time adjustments difficult. Cooperative multitasking allows multiple processes to share CPU time voluntarily, enhancing responsiveness and user control, yet risks system hangs if a process fails to yield control, compromising overall stability and performance. Each approach balances resource management and user experience differently, with batch processing favoring high-volume jobs and cooperative multitasking prioritizing interactive applications.
Security and Stability Considerations
Batch processing enhances security by minimizing user interaction, reducing exposure to malicious activities and limiting access points during execution. Cooperative multitasking relies on each task to yield control, increasing risks of system instability and security vulnerabilities if a task errantly consumes resources or bypasses proper handoffs. Stability in batch processing is maintained through isolated, sequential execution, whereas cooperative multitasking depends heavily on trust and well-behaved tasks, leading to potential security breaches and system crashes.
Choosing the Right Model for Your Needs
Batch processing excels in handling large volumes of tasks without user interaction, making it ideal for data-heavy operations such as payroll or transaction processing. Cooperative multitasking suits environments where multiple programs share resources but require smooth user interaction, common in legacy systems or embedded applications. Selecting the right model depends on factors like system responsiveness, resource management, and the need for real-time user input.
Batch Processing Infographic