Karnaugh Maps (K-Maps) simplify Boolean algebra expressions by visually organizing truth values in a grid format, minimizing logic functions efficiently. They help reduce complex digital circuits by grouping adjacent ones, allowing for straightforward identification of prime implicants and essential terms. Explore the rest of the article to master K-Map techniques and optimize your digital logic designs effortlessly.
Table of Comparison
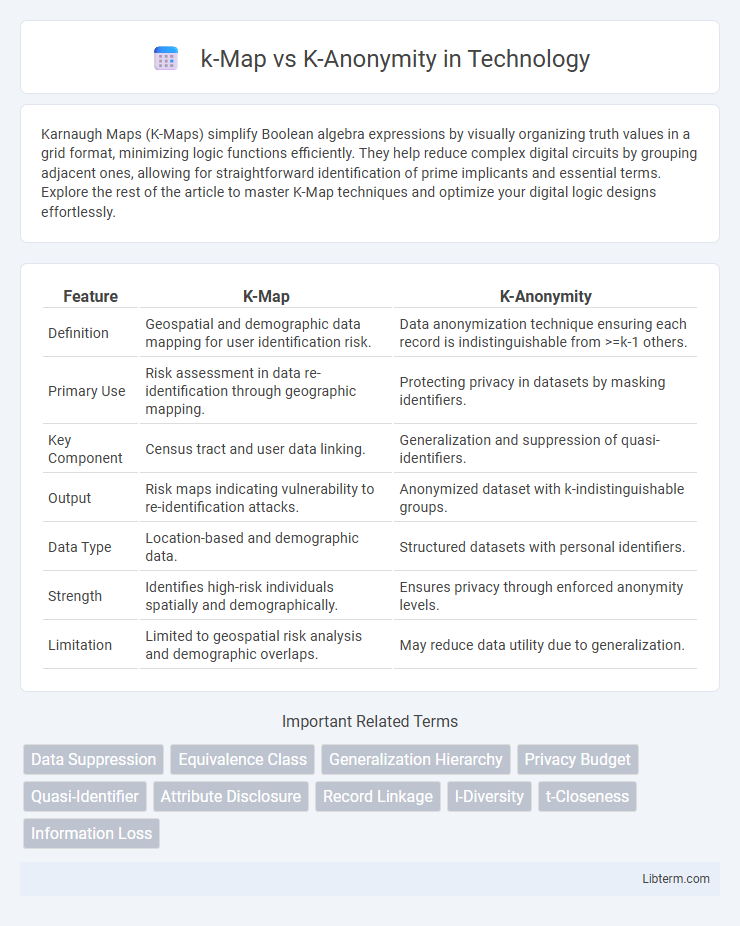
| Feature | K-Map | K-Anonymity |
|---|---|---|
| Definition | Geospatial and demographic data mapping for user identification risk. | Data anonymization technique ensuring each record is indistinguishable from >=k-1 others. |
| Primary Use | Risk assessment in data re-identification through geographic mapping. | Protecting privacy in datasets by masking identifiers. |
| Key Component | Census tract and user data linking. | Generalization and suppression of quasi-identifiers. |
| Output | Risk maps indicating vulnerability to re-identification attacks. | Anonymized dataset with k-indistinguishable groups. |
| Data Type | Location-based and demographic data. | Structured datasets with personal identifiers. |
| Strength | Identifies high-risk individuals spatially and demographically. | Ensures privacy through enforced anonymity levels. |
| Limitation | Limited to geospatial risk analysis and demographic overlaps. | May reduce data utility due to generalization. |
Introduction to Data Privacy Techniques
K-Map and K-Anonymity are essential data privacy techniques aimed at protecting sensitive information during data analysis and sharing. K-Anonymity ensures that any individual cannot be distinguished from at least k-1 others in a dataset, reducing the risk of re-identification through generalization and suppression of identifying attributes. K-Map, often used in the context of re-identification risk assessment, maps quasi-identifiers to known external datasets to evaluate whether anonymized data can still be linked back to individuals, highlighting vulnerabilities in privacy protection methods.
What is k-Map?
k-Map is a privacy risk measure that estimates the likelihood of identifying an individual in a dataset by linking anonymized data with external information. It quantifies the probability that a record in the dataset uniquely matches an individual based on quasi-identifiers, reflecting the vulnerability to re-identification attacks. Unlike k-Anonymity, which enforces groupings of records to prevent identification, k-Map evaluates the actual risk of linkage disclosure without altering the dataset.
What is K-Anonymity?
K-Anonymity is a privacy-preserving technique used in data anonymization to protect individuals' identities by ensuring that each record is indistinguishable from at least k-1 other records within a dataset. It achieves this by generalizing or suppressing specific quasi-identifiers, such as age, ZIP code, or gender, thus preventing re-identification of individuals. This method is widely employed in fields like healthcare and social sciences to balance data utility with privacy protection.
Core Principles of k-Map and K-Anonymity
k-Map is a re-identification risk assessment technique that estimates the probability of correctly linking anonymized records to individuals by analyzing the uniqueness of quasi-identifiers in external data sources. K-Anonymity is a privacy preservation model that ensures each record is indistinguishable from at least k-1 other records in a dataset by generalizing or suppressing identifiers. The core principle of k-Map revolves around assessing re-identification risk based on external data overlap, while K-Anonymity focuses on achieving a minimum group size to protect against identity disclosure.
Key Differences Between k-Map and K-Anonymity
K-Map identifies individuals by linking quasi-identifiers with external datasets, revealing privacy risks through re-identification, whereas K-Anonymity protects privacy by ensuring each record is indistinguishable from at least k-1 others based on those quasi-identifiers. K-Map is a risk assessment technique quantifying potential exposure, while K-Anonymity is a privacy model applying data generalization or suppression to prevent re-identification. The key difference lies in K-Map's focus on measuring vulnerability, and K-Anonymity's focus on data transformation to safeguard anonymity.
Advantages of k-Map
k-Map leverages precise re-identification risk quantification by applying exact matching techniques on quasi-identifiers, allowing for a clear understanding of privacy vulnerabilities in datasets. It provides more detailed risk assessment compared to K-Anonymity, which primarily ensures group indistinguishability without measuring actual re-identification probabilities. The advantage of k-Map lies in its ability to identify the minimal set of attributes leading to potential identity disclosure, enabling targeted data protection strategies that maintain utility while minimizing privacy risks.
Benefits of K-Anonymity
K-Anonymity enhances data privacy by ensuring that any given individual's information cannot be distinguished from at least k-1 others, significantly reducing the risk of re-identification in datasets. Unlike K-Map, which primarily serves visualization and simplification of Boolean expressions, K-Anonymity provides a robust framework for protecting sensitive data in data publishing and sharing. Implementing K-Anonymity improves compliance with privacy regulations such as GDPR and HIPAA by preventing the exposure of unique personal identifiers.
Limitations and Challenges
K-Map faces limitations due to its reliance on precise demographic and geographic data, making it vulnerable to re-identification when external information is available. K-Anonymity struggles with preserving data utility while minimizing information loss, as achieving adequate anonymity often requires extensive generalization or suppression. Both methods encounter challenges in handling high-dimensional data and ensuring robust protection against sophisticated inference attacks.
Practical Applications and Use Cases
K-Map is utilized in digital circuit design to simplify Boolean expressions, enhancing hardware efficiency and reducing logic gate usage in electronic systems and embedded devices. K-Anonymity focuses on data privacy by masking sensitive information in datasets, widely applied in healthcare, finance, and social sciences to prevent re-identification of individuals while sharing data. Both techniques address distinct practical needs: K-Map optimizes digital logic circuits, whereas K-Anonymity secures personal data in large-scale databases.
Choosing the Right Approach for Data Privacy
K-Map and K-Anonymity serve distinct roles in data privacy; K-Map identifies unique geographic locations from data points, while K-Anonymity focuses on protecting individual identities in datasets through generalization and suppression techniques. Choosing the right approach depends on whether the priority is spatial analysis accuracy with K-Map or safeguarding personal information against re-identification risks using K-Anonymity. Organizations handling sensitive demographic records benefit from K-Anonymity, whereas those analyzing location-based data for patterns may find K-Map more suitable.
k-Map Infographic