Protocol Buffer and Avro are powerful serialization frameworks designed for efficient data exchange and storage, widely used in distributed systems and big data applications. Each offers unique features: Protocol Buffer emphasizes compactness and speed with a schema defined in .proto files, while Avro integrates schema evolution directly within data files for flexible, dynamic applications. Explore the rest of the article to understand how these tools can enhance your data serialization strategy.
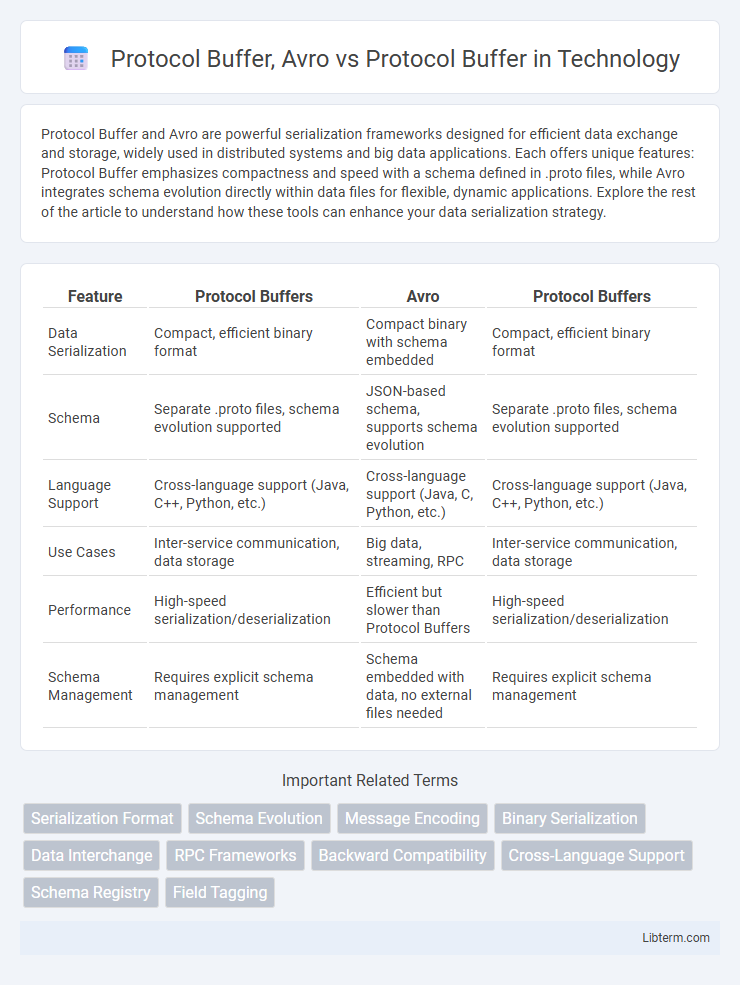
Table of Comparison
| Feature | Protocol Buffers | Avro | Protocol Buffers |
|---|---|---|---|
| Data Serialization | Compact, efficient binary format | Compact binary with schema embedded | Compact, efficient binary format |
| Schema | Separate .proto files, schema evolution supported | JSON-based schema, supports schema evolution | Separate .proto files, schema evolution supported |
| Language Support | Cross-language support (Java, C++, Python, etc.) | Cross-language support (Java, C, Python, etc.) | Cross-language support (Java, C++, Python, etc.) |
| Use Cases | Inter-service communication, data storage | Big data, streaming, RPC | Inter-service communication, data storage |
| Performance | High-speed serialization/deserialization | Efficient but slower than Protocol Buffers | High-speed serialization/deserialization |
| Schema Management | Requires explicit schema management | Schema embedded with data, no external files needed | Requires explicit schema management |
Introduction to Data Serialization Formats
Protocol Buffer and Avro are popular data serialization formats designed for efficient data exchange and storage in distributed systems. Protocol Buffer, developed by Google, uses a compact binary format with a schema defined in .proto files, enabling backward and forward compatibility while optimizing performance. Avro, created by the Apache Hadoop project, stores schema alongside the data in JSON format, facilitating dynamic schemas and seamless integration with big data ecosystems.
What is Protocol Buffer?
Protocol Buffer is a language-neutral, platform-neutral serialization library developed by Google for efficient data interchange. It uses a compact binary format to encode structured data, enabling faster transmission and reduced storage compared to text-based formats like JSON or XML. Protocol Buffer defines data schemas using .proto files, facilitating backward and forward compatibility across distributed systems.
Understanding Avro: An Overview
Avro is a data serialization system developed within the Apache Hadoop project, designed for compact, fast, binary data interchange with rich data structures and schema evolution support. Unlike Protocol Buffers, Avro stores its schema within the serialized data, enabling dynamic and flexible schema resolution at runtime, which simplifies cross-language data communication. Avro's JSON-based schema definition and lack of generated code make it particularly suitable for big data applications requiring seamless integration with Hadoop and streaming platforms.
Core Features of Protocol Buffer
Protocol Buffer offers efficient serialization with compact binary format and supports forward and backward compatibility through schema evolution. It provides strong data typing, language-neutral interfaces, and automatic code generation for multiple programming languages, enhancing development speed and reducing errors. Unlike Avro, Protocol Buffer requires a separate schema file and emphasizes minimal message size, making it ideal for performance-critical applications.
Key Features of Avro
Avro offers schema evolution with dynamic schemas embedded in data files, enabling seamless data serialization and deserialization across different versions without breaking compatibility. Its JSON-based schema provides human-readable and flexible structure definitions, facilitating easier integration in diverse data serialization workflows. Unlike Protocol Buffers which require predefined schemas for compilation, Avro's schema is always stored with the data, optimizing for big data environments like Apache Hadoop and Apache Kafka.
Performance Comparison: Avro vs Protocol Buffer
Protocol Buffer outperforms Avro in serialization and deserialization speed due to its compact binary format and efficient encoding mechanisms. While Avro offers schema evolution benefits and easy integration with Hadoop ecosystems, Protocol Buffer's optimized binary size reduces network bandwidth and latency significantly. Benchmark tests reveal Protocol Buffer achieves faster data processing times, making it ideal for high-performance applications requiring rapid data exchange.
Schema Evolution: Avro and Protocol Buffer
Avro supports schema evolution by allowing both backward and forward compatibility through its use of JSON-based schemas embedded with data, enabling dynamic schema resolution during message serialization and deserialization. Protocol Buffer handles schema evolution by requiring field numbering consistency and supports backward compatibility primarily through optional fields and default values but does not support schema evolution as flexibly as Avro. Avro's ability to include schemas with data simplifies evolving data structures in distributed systems, whereas Protocol Buffer relies on stricter schema management and versioning practices.
Data Interoperability and Compatibility
Protocol Buffer offers strong backward and forward compatibility through explicit schema evolution rules, ensuring seamless data interoperability across different versions of applications. Avro emphasizes dynamic schemas embedded within serialized data, facilitating flexible data exchange and schema resolution at runtime. Both formats enable efficient cross-language data serialization, but Protocol Buffer's static schema approach provides more robust type safety, while Avro excels in schema evolution and interoperability in distributed data systems.
Use Case Scenarios: When to Choose Avro or Protocol Buffer
Protocol Buffer excels in scenarios requiring high-performance serialization with compact binary output, ideal for microservices, RPC frameworks, and real-time communication due to its efficient schema evolution and fast processing. Avro is preferred for big data ecosystems like Hadoop and Kafka, where schema-on-read capabilities and dynamic schema resolution provide flexibility in handling evolving data structures and diverse data streams. Choosing Protocol Buffer fits use cases demanding speed and compatibility in tightly coupled services, while Avro suits analytics pipelines and heterogeneous environments requiring schema flexibility.
Conclusion: Choosing the Right Serialization Format
Protocol Buffer offers efficient serialization with compact binary output and strong backward compatibility, making it ideal for performance-critical applications and cross-language systems. Avro provides dynamic schemas embedded within data files, enabling schema evolution and seamless integration in Big Data environments like Hadoop. Selecting between Protocol Buffer and Avro depends on specific use cases: choose Protocol Buffer for fixed schemas and optimized speed, whereas Avro excels in scenarios requiring flexible schema evolution and interoperability with data processing frameworks.
Protocol Buffer, Avro Infographic