Augmented data enhances machine learning models by artificially expanding training datasets through techniques like rotations, flips, and color adjustments. This process improves model accuracy and robustness by simulating a wider variety of real-world scenarios. Explore the rest of the article to understand how augmented data can transform Your AI projects.
Table of Comparison
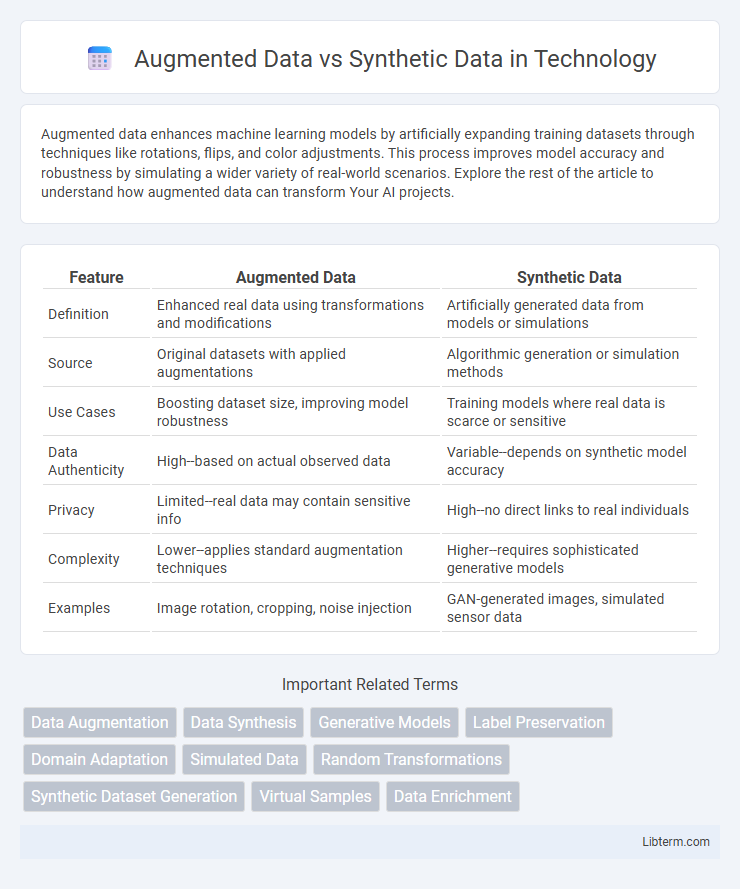
| Feature | Augmented Data | Synthetic Data |
|---|---|---|
| Definition | Enhanced real data using transformations and modifications | Artificially generated data from models or simulations |
| Source | Original datasets with applied augmentations | Algorithmic generation or simulation methods |
| Use Cases | Boosting dataset size, improving model robustness | Training models where real data is scarce or sensitive |
| Data Authenticity | High--based on actual observed data | Variable--depends on synthetic model accuracy |
| Privacy | Limited--real data may contain sensitive info | High--no direct links to real individuals |
| Complexity | Lower--applies standard augmentation techniques | Higher--requires sophisticated generative models |
| Examples | Image rotation, cropping, noise injection | GAN-generated images, simulated sensor data |
Introduction to Augmented Data and Synthetic Data
Augmented data involves enhancing existing datasets by applying transformations such as rotation, scaling, or color adjustments to increase variability and improve model robustness. Synthetic data is artificially generated using algorithms or simulations to create entirely new data points that mimic real-world distributions, often used when real data is scarce or privacy-sensitive. Both approaches aim to address data limitations and improve machine learning model performance through increased dataset diversity.
Defining Augmented Data
Augmented data refers to existing datasets that have been enhanced through techniques such as rotation, scaling, flipping, or noise addition to increase diversity and improve machine learning model robustness. This process maintains the original data's underlying properties while generating variations that help reduce overfitting and improve generalization. Unlike synthetic data, which is generated entirely from models or simulations, augmented data is derived by modifying real-world examples.
Defining Synthetic Data
Synthetic data is artificially generated information created through algorithms and simulations to mimic real-world data characteristics without exposing sensitive information. Unlike augmented data, which involves enhancing existing datasets by transformations such as rotation or scaling, synthetic data is entirely fabricated, offering scalable and privacy-preserving solutions for training machine learning models. This approach enables robust model development, especially when access to real data is restricted or limited due to privacy concerns.
Key Differences Between Augmented and Synthetic Data
Augmented data enhances existing datasets by applying transformations such as rotation, scaling, or noise addition to real data, preserving underlying patterns and improving model robustness. Synthetic data, generated from algorithms or simulations, creates entirely new data points without direct reliance on real samples, enabling privacy protection and addressing data scarcity. Key differences include the origin--augmented data stems from real data while synthetic data is artificial--and their implications on model training, privacy, and diversity of the dataset.
Use Cases for Augmented Data
Augmented data enhances existing datasets by introducing slight variations of real data, improving model robustness in applications like image recognition, natural language processing, and medical diagnostics. It is particularly valuable in scenarios with limited labeled data, enabling better generalization and accuracy in machine learning models. Use cases include augmenting medical imaging for rare diseases, expanding voice datasets for speech recognition, and enriching autonomous vehicle sensor data to simulate diverse driving conditions.
Use Cases for Synthetic Data
Synthetic data is essential for training machine learning models in scenarios where real data is scarce, sensitive, or expensive to collect, such as autonomous driving, healthcare, and finance fraud detection. It enables the creation of diverse and balanced datasets that improve model robustness and reduce bias without compromising privacy. Industries leverage synthetic data to simulate rare events, perform stress testing, and accelerate algorithm development while ensuring compliance with data protection regulations.
Advantages of Augmented Data
Augmented data enhances model performance by expanding original datasets through realistic variations, preserving authentic data distribution and maintaining data quality. It reduces the risk of overfitting by introducing minor, controlled alterations such as rotation, scaling, and color adjustments, which helps models generalize better to real-world scenarios. Augmented data is cost-effective since it leverages existing labeled samples, minimizing the need for expensive data collection or annotation processes compared to generating fully synthetic datasets.
Benefits of Synthetic Data
Synthetic data offers enhanced privacy protection by generating artificial datasets that avoid using real personal information, minimizing risks of data breaches and compliance issues. It enables scalable data production for training machine learning models, especially in scenarios with limited or imbalanced real data, ensuring better model generalization and robustness. Furthermore, synthetic data allows for controlled environment simulation, facilitating testing under rare or extreme conditions that are difficult to capture with augmented or real-world data.
Challenges and Limitations
Augmented data often faces challenges related to preserving data diversity and avoiding overfitting due to limited variations generated from original datasets. Synthetic data presents limitations such as potential inaccuracies in representing real-world distributions and risks of introducing bias if the generative models are inadequately trained. Both approaches require careful validation to ensure that the data quality supports robust and generalizable machine learning model performance.
Choosing Between Augmented and Synthetic Data
Choosing between augmented data and synthetic data depends on the specific use case and data requirements for machine learning models. Augmented data enhances existing datasets by applying transformations such as rotations, color changes, or noise to increase diversity while preserving real-world features, making it ideal for improving model robustness without extensive data collection. Synthetic data, generated entirely by algorithms or simulations, offers scalability and privacy advantages, especially useful when real data is scarce or sensitive but may require careful validation to ensure it accurately represents real-world scenarios.
Augmented Data Infographic