Real data offers authentic insights that drive informed decisions and enhance predictive accuracy in various fields. Leveraging real data ensures that models and analyses reflect true patterns and behaviors, boosting reliability. Explore the rest of the article to discover how harnessing real data can transform your strategies.
Table of Comparison
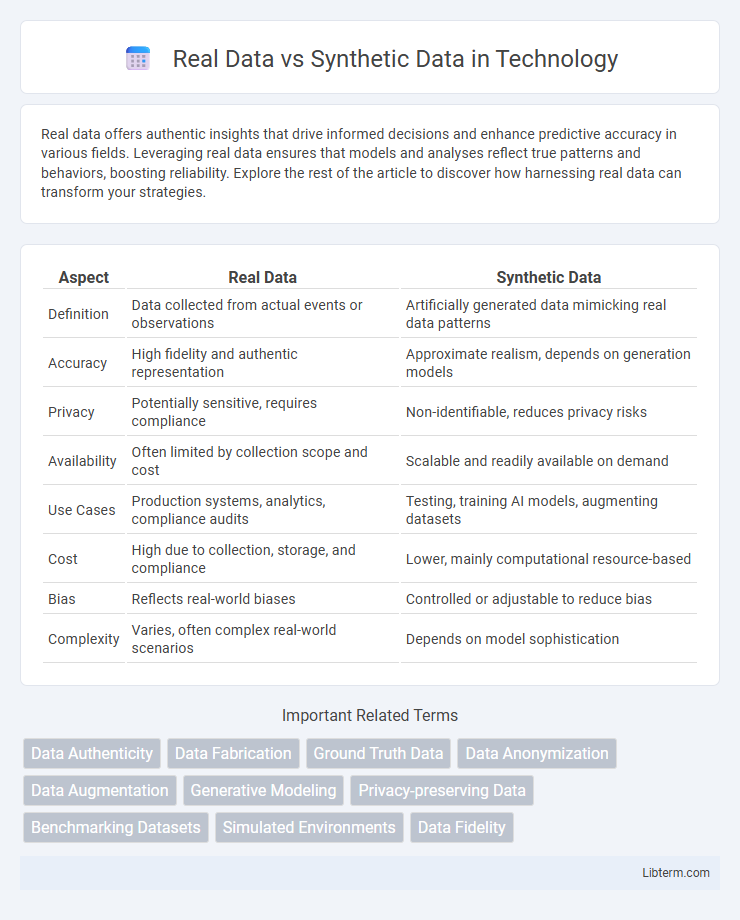
| Aspect | Real Data | Synthetic Data |
|---|---|---|
| Definition | Data collected from actual events or observations | Artificially generated data mimicking real data patterns |
| Accuracy | High fidelity and authentic representation | Approximate realism, depends on generation models |
| Privacy | Potentially sensitive, requires compliance | Non-identifiable, reduces privacy risks |
| Availability | Often limited by collection scope and cost | Scalable and readily available on demand |
| Use Cases | Production systems, analytics, compliance audits | Testing, training AI models, augmenting datasets |
| Cost | High due to collection, storage, and compliance | Lower, mainly computational resource-based |
| Bias | Reflects real-world biases | Controlled or adjustable to reduce bias |
| Complexity | Varies, often complex real-world scenarios | Depends on model sophistication |
Introduction to Real Data and Synthetic Data
Real data consists of actual information collected from real-world sources, encompassing accurate and unaltered measurements, events, or observations. Synthetic data is artificially generated using algorithms, simulations, or models designed to replicate the statistical properties and patterns found in real data without revealing sensitive information. Both types of data serve distinct roles in machine learning, data analysis, and privacy preservation contexts.
Key Differences Between Real and Synthetic Data
Real data consists of authentic information collected from actual events or observations, ensuring high accuracy and true representation of phenomena, whereas synthetic data is artificially generated using algorithms or simulations to mimic real data patterns without containing real-world details. Real data often contains noise and inconsistencies but provides ground truth, while synthetic data is clean, customizable, and scalable, enabling privacy preservation and addressing data scarcity. The key differences lie in authenticity, privacy concerns, data quality, and application suitability for training machine learning models or conducting analyses.
Advantages of Using Real Data
Real data provides authentic, high-fidelity information derived from actual events, ensuring models trained on it capture real-world complexities and nuances. It enhances the accuracy and reliability of machine learning algorithms by reflecting true patterns, behaviors, and variability inherent in natural datasets. Access to real data facilitates validation and benchmarking processes, enabling robust evaluation of predictive performance in practical applications.
Benefits of Synthetic Data Generation
Synthetic data generation enhances data availability by creating large, diverse datasets that overcome limitations of real data scarcity or privacy restrictions. It improves machine learning model training by providing balanced datasets that reduce bias and increase generalization across different scenarios. Synthetic data also accelerates innovation in fields like autonomous driving and healthcare by enabling safe and cost-effective experimentation without risking sensitive information.
Challenges of Working With Real Data
Real data often presents challenges such as missing values, inconsistencies, and noise that complicate analysis and model training. Privacy concerns and regulatory restrictions limit access to comprehensive datasets, affecting the quality and representativeness of real data. The high cost and time-consuming process of collecting and cleaning real data further hinder efficient data-driven decision-making.
Common Use Cases for Synthetic Data
Synthetic data is widely used in machine learning model training, enabling robust algorithms without compromising privacy or requiring extensive real-world data collection. It supports scenarios such as autonomous vehicle simulation, healthcare research with anonymized patient records, and financial fraud detection testing under rare conditions. Enterprises leverage synthetic data to enhance feature engineering, improve model generalization, and accelerate development cycles by generating diverse, scalable datasets.
Privacy and Security Implications
Real data contains sensitive personal information, making it vulnerable to privacy risks such as data breaches and unauthorized access, which require stringent security measures and compliance with regulations like GDPR and CCPA. Synthetic data, generated artificially without direct ties to real individuals, significantly reduces privacy concerns by minimizing the risk of exposing personal identifiers while enabling safe data sharing and model training. However, synthetic data must be carefully validated to ensure it accurately represents real data patterns without compromising utility or security.
Quality and Accuracy: Real vs Synthetic
Real data offers unparalleled authenticity and reflects true phenomena, making it highly accurate for training and validating models. Synthetic data, while often less precise due to its generated nature, can be tailored to cover edge cases and augment data scarcity, enhancing overall model robustness. The quality of synthetic data depends heavily on the generation algorithms and their ability to mimic real-world distributions and patterns.
Tools and Technologies for Data Generation
Synthetic data generation relies on advanced tools such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) to create realistic datasets that mimic real data distributions. Real data tools often involve traditional data collection methods, data warehousing solutions, and ETL (Extract, Transform, Load) processes for managing and cleaning large datasets. Emerging technologies like deep learning frameworks (e.g., TensorFlow, PyTorch) and specialized synthetic data platforms (e.g., Gretel.ai, Hazy) enhance the generation, augmentation, and validation of synthetic datasets for machine learning and AI applications.
Choosing the Right Data for Your Project
Choosing the right data for your project depends on the specific goals, data quality requirements, and privacy considerations. Real data offers authentic, diverse insights ideal for accurate model training but may involve privacy risks and limited availability. Synthetic data provides scalable, privacy-compliant alternatives with controlled scenarios, enhancing model robustness when real data is scarce or sensitive.
Real Data Infographic