Table clustering efficiently groups similar data entries to enhance data analysis and retrieval processes. Leveraging algorithms such as k-means or hierarchical clustering, it identifies patterns and relationships within large datasets. Discover how table clustering can streamline your data management by exploring the full article.
Table of Comparison
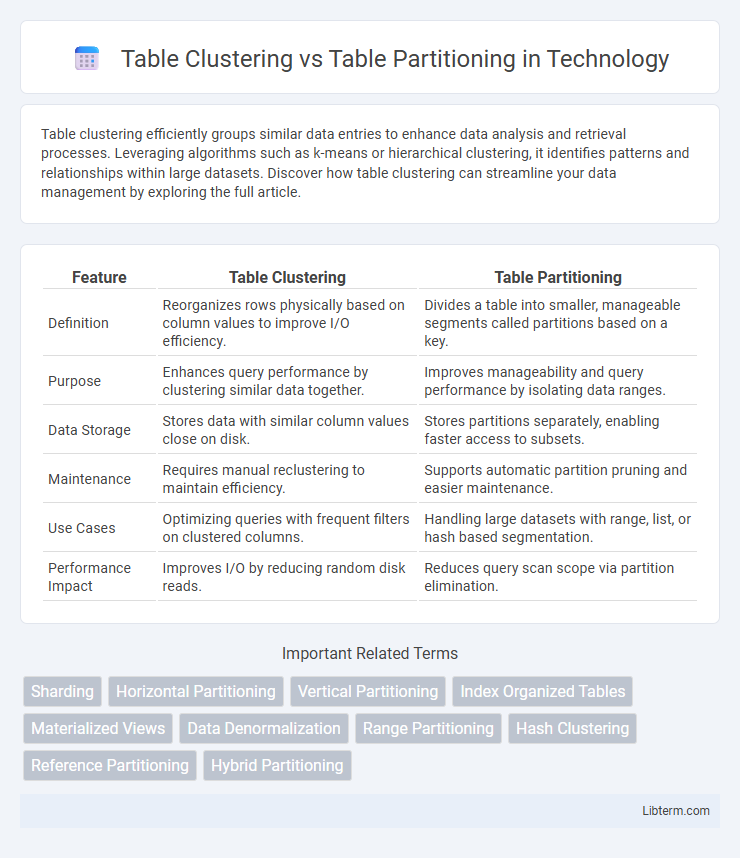
| Feature | Table Clustering | Table Partitioning |
|---|---|---|
| Definition | Reorganizes rows physically based on column values to improve I/O efficiency. | Divides a table into smaller, manageable segments called partitions based on a key. |
| Purpose | Enhances query performance by clustering similar data together. | Improves manageability and query performance by isolating data ranges. |
| Data Storage | Stores data with similar column values close on disk. | Stores partitions separately, enabling faster access to subsets. |
| Maintenance | Requires manual reclustering to maintain efficiency. | Supports automatic partition pruning and easier maintenance. |
| Use Cases | Optimizing queries with frequent filters on clustered columns. | Handling large datasets with range, list, or hash based segmentation. |
| Performance Impact | Improves I/O by reducing random disk reads. | Reduces query scan scope via partition elimination. |
Introduction to Table Clustering and Table Partitioning
Table clustering organizes related rows from multiple tables based on common columns, enhancing join performance by physically storing related data closely. Table partitioning divides large tables into smaller, manageable segments based on key values like date ranges or hashes, improving query efficiency and data maintenance. Both techniques optimize database performance but address different needs: clustering enhances join operations, while partitioning facilitates data management and query pruning.
Defining Table Clustering: Concept and Use Cases
Table clustering organizes tables based on the physical storage of related data rows, grouping similar rows into the same data blocks to enhance query performance in large datasets. It is particularly useful for optimizing join operations and reducing I/O by collocating related rows, commonly applied in data warehousing and OLAP scenarios. Unlike partitioning, clustering does not split tables into separate segments but improves access speed by maintaining related data proximity within a single table structure.
Understanding Table Partitioning: Concept and Applications
Table partitioning divides a large table into smaller, manageable segments based on a partition key, enhancing query performance and maintenance efficiency by eliminating the need to scan the entire dataset. Common partitioning methods include range, list, and hash partitions, each suited for different data distribution patterns and query types. This technique is widely applied in data warehousing, time-series data management, and situations requiring rapid data pruning and parallel processing.
Key Differences Between Clustering and Partitioning
Table clustering groups related rows physically together in the same data block to optimize query performance, especially for join operations, while table partitioning divides a table into separate segments based on defined partition keys for improved manageability and query pruning. Clustering maintains data within a single table structure without altering logical division, whereas partitioning creates multiple distinct partitions that function as individual units for maintenance and optimization. Clustering benefits data locality and join efficiency, and partitioning enhances scalability and simplifies data management for large datasets.
Performance Impact: Clustering vs Partitioning
Table clustering improves performance by physically ordering rows based on a key, which speeds up range queries and index scans without dividing the table into segments. Table partitioning enhances query performance by dividing large tables into smaller, manageable partitions, allowing the database to prune irrelevant partitions and reduce I/O during queries. Partitioning is more effective for queries filtering on partition keys, while clustering benefits workloads with frequent range scans on clustering columns.
Data Organization Techniques Compared
Table clustering organizes related tables physically together in the same database blocks to optimize join performance by minimizing I/O operations. Table partitioning divides a large table into smaller, manageable segments based on specified key values, enabling efficient query processing and maintenance. While clustering improves data retrieval for joined tables, partitioning enhances scalability and data management by segmenting individual tables.
Scalability Considerations in Clustering and Partitioning
Table clustering improves scalability by physically grouping related rows from multiple tables into the same data blocks, reducing I/O during joins and benefiting query performance in multi-table environments. Table partitioning enhances scalability by dividing large tables into smaller, more manageable segments based on key columns, enabling efficient data pruning and parallel processing. While clustering optimizes access patterns for specific join queries, partitioning supports large-scale data management, maintenance, and load balancing across distributed systems.
Use Cases and Best Practices
Table clustering enhances query performance by physically grouping similar rows based on indexed columns, making it ideal for workloads with frequent joins and range scans on specific keys. Table partitioning divides large tables into smaller, manageable segments based on partition key values, optimizing maintenance tasks, improving data pruning, and accelerating queries that filter on partition columns. Best practices include using table clustering for OLTP scenarios with repetitive query patterns and table partitioning for large data warehouses requiring efficient data management and parallel query processing.
Challenges and Limitations
Table clustering often faces challenges such as increased complexity in query optimization and difficulty managing data distribution across clusters, leading to potential performance bottlenecks. Table partitioning presents limitations including restricted partition key flexibility and overhead from maintaining multiple partition segments, which can complicate data maintenance and slow down certain query types. Both techniques require careful planning to balance improved data access speed against increased administrative and operational complexity.
Choosing the Right Approach: Clustering or Partitioning
Choosing between table clustering and table partitioning depends on data organization and query performance goals. Table clustering groups physically related rows together to optimize local I/O for specific queries, while partitioning divides large tables into smaller, manageable segments based on key values for efficient data management and parallel processing. For workloads requiring targeted access to subsets of data with predictable query patterns, partitioning offers superior performance, whereas clustering benefits scenarios with complex joins and frequent access on clustered columns.
Table Clustering Infographic