A pushdown automaton is a computational model used in automata theory that extends the capabilities of a finite automaton by incorporating a stack as additional memory. It is essential for recognizing context-free languages and plays a crucial role in parsing and syntax analysis in compilers. Explore the rest of the article to understand how a pushdown automaton functions and its significance in computer science.
Table of Comparison
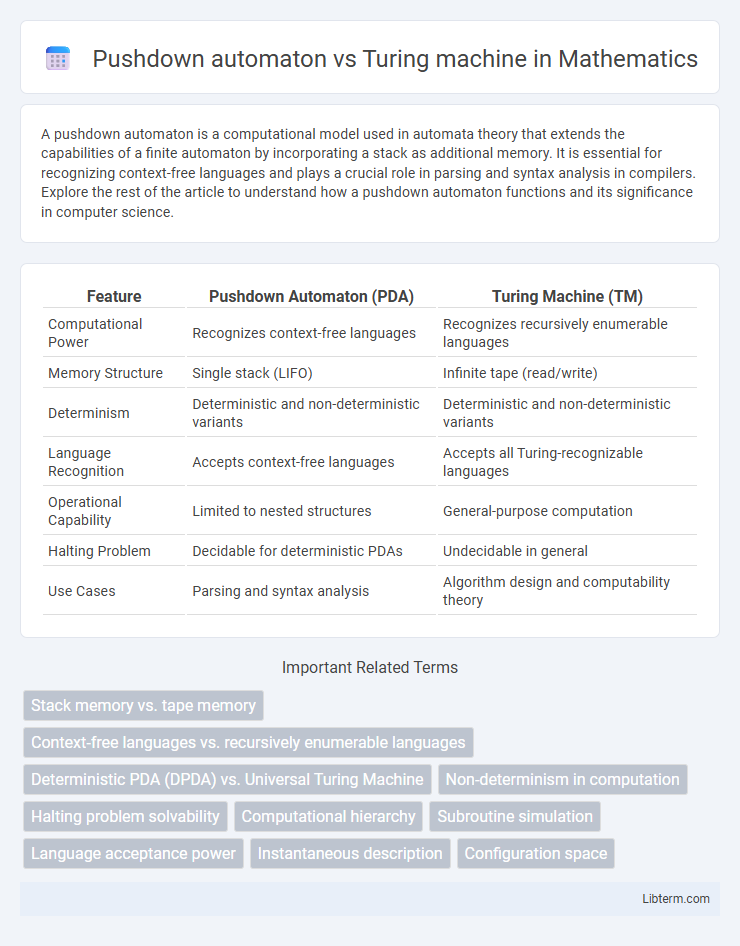
| Feature | Pushdown Automaton (PDA) | Turing Machine (TM) |
|---|---|---|
| Computational Power | Recognizes context-free languages | Recognizes recursively enumerable languages |
| Memory Structure | Single stack (LIFO) | Infinite tape (read/write) |
| Determinism | Deterministic and non-deterministic variants | Deterministic and non-deterministic variants |
| Language Recognition | Accepts context-free languages | Accepts all Turing-recognizable languages |
| Operational Capability | Limited to nested structures | General-purpose computation |
| Halting Problem | Decidable for deterministic PDAs | Undecidable in general |
| Use Cases | Parsing and syntax analysis | Algorithm design and computability theory |
Introduction to Computational Models
Pushdown automata (PDAs) are computational models used to recognize context-free languages by utilizing a finite state machine coupled with a stack for memory storage. Turing machines extend this capability by featuring an infinite tape, enabling the simulation of any algorithm and recognition of recursively enumerable languages. The key difference lies in the memory structure: PDAs have limited, stack-based memory, while Turing machines provide unbounded, random-access memory, allowing for greater computational power.
What is a Pushdown Automaton?
A Pushdown Automaton (PDA) is a computational model used to recognize context-free languages, functioning as a finite automaton equipped with an auxiliary stack for memory. The PDA processes input symbols while manipulating the stack through push and pop operations, enabling it to handle nested structures like balanced parentheses. Unlike Turing machines, which have an infinite tape allowing for more complex computations, PDAs have limited memory confined to a stack, making them less powerful but crucial for parsing tasks in compiler design and formal language theory.
What is a Turing Machine?
A Turing machine is an abstract computational model that manipulates symbols on an infinite tape according to a set of rules to simulate any algorithmic process. It consists of a tape divided into cells, a read/write head that moves left or right, and a finite control that dictates the machine's operations based on the current state and tape symbol. This universal computational power surpasses that of a pushdown automaton, which uses a stack and is limited to recognizing context-free languages.
Structural Differences Between PDA and Turing Machine
A Pushdown Automaton (PDA) has a finite set of states and uses a single stack as its memory structure, allowing it to recognize context-free languages. In contrast, a Turing Machine possesses an infinite tape as its memory, enabling read/write operations and arbitrary movement, which grants it the capability to recognize recursively enumerable languages. Structurally, the PDA's memory is limited to stack operations (push, pop), while the Turing Machine's tape allows comprehensive manipulation of symbols, making it more powerful and versatile in computational processes.
Memory Mechanisms: Stack vs. Infinite Tape
A Pushdown Automaton (PDA) uses a stack as its memory mechanism, allowing it to store an unbounded amount of information but only supports last-in, first-out (LIFO) access. In contrast, a Turing Machine employs an infinite tape that functions as a read-write memory, enabling random access and modification of data at any tape position. This fundamental difference in memory structures grants Turing Machines greater computational power and the ability to solve a wider range of languages compared to PDAs.
Language Recognition Capabilities
Pushdown automata (PDA) recognize context-free languages, utilizing a stack to manage nested structures and enabling parsing of languages like balanced parentheses and palindromes. Turing machines possess superior language recognition capabilities, capable of recognizing recursively enumerable languages that include all context-free and context-sensitive languages. The stack-based memory limitation of PDAs confines them to non-regular language classes, whereas Turing machines' unlimited tape allows them to simulate any algorithmic process.
Determinism in PDA and Turing Machine
Determinism in Pushdown Automata (PDA) restricts their ability to recognize certain context-free languages since deterministic PDAs (DPDAs) cannot handle all non-deterministic cases, unlike non-deterministic PDAs. Turing Machines (TMs), whether deterministic or non-deterministic, possess equivalent computational power, capable of recognizing recursively enumerable languages, reflecting that determinism does not limit the class of languages recognizable by TMs. The deterministic nature of PDAs limits language recognition to deterministic context-free languages, whereas deterministic and non-deterministic TMs share the same computational capabilities.
Practical Applications of PDAs and Turing Machines
Pushdown automata (PDAs) are primarily used in programming language parsing and syntax analysis, enabling efficient processing of context-free grammars in compilers and interpreters. Turing machines provide a more general computational model capable of simulating any algorithm, making them fundamental in the design and analysis of complex algorithms, artificial intelligence, and formal verification. Practical applications of Turing machines span beyond PDAs, including decision problems, computability theory, and the development of automated reasoning systems.
Limitations and Advantages of Each Model
Pushdown automata excel in recognizing context-free languages with a single stack, offering efficient parsing for programming languages but are limited in memory and cannot handle languages requiring arbitrary tape access or complex computations. Turing machines provide a universal computation model with infinite tape memory, enabling recognition of recursively enumerable languages and solving broader problems beyond context-free languages but at the cost of increased complexity and slower processing. The fundamental limitation of pushdown automata is their restricted memory structure, while Turing machines, despite their computational power, face practical challenges in implementation and time efficiency.
Summary: Choosing the Right Model
Pushdown automata are ideal for recognizing context-free languages due to their use of a stack for memory, making them efficient for parsing tasks like programming language syntax analysis. Turing machines offer greater computational power, capable of simulating any algorithm and recognizing a broader class of languages, including context-sensitive and recursively enumerable languages. Selecting the right model depends on the complexity of the language and the computational resources needed, with pushdown automata suited for simpler hierarchical structures and Turing machines necessary for general-purpose computation.
Pushdown automaton Infographic