Biological computing harnesses living systems and biomolecules to perform complex computations, offering revolutionary advances in data processing and storage. This approach combines biology with computer science to create devices that are energy-efficient, scalable, and capable of solving problems traditional silicon-based computers cannot. Discover how biological computing could transform the future of technology by reading the rest of the article.
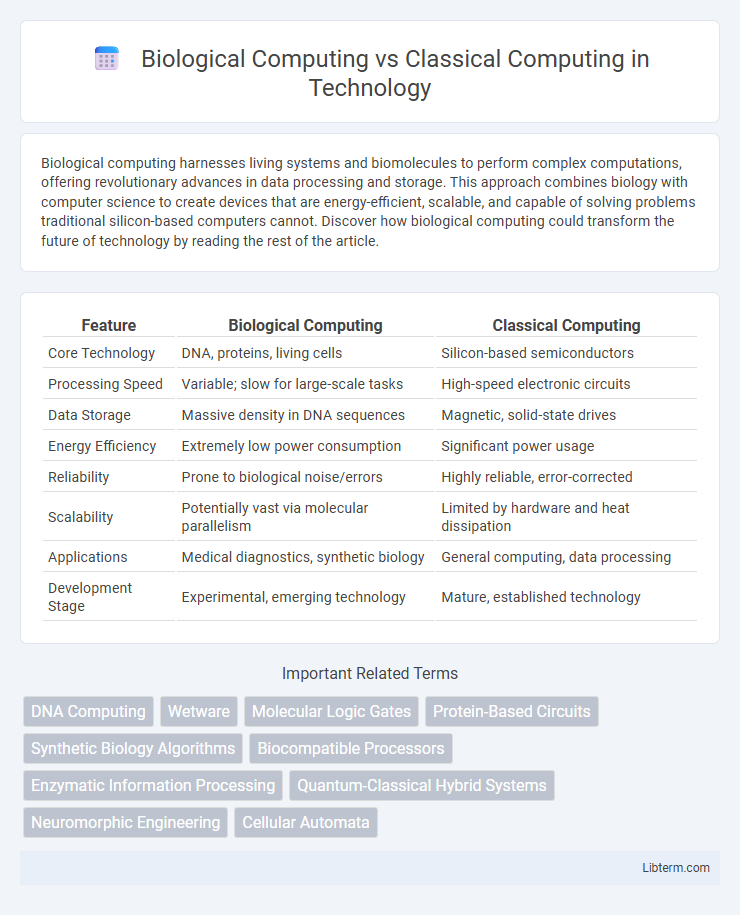
Table of Comparison
| Feature | Biological Computing | Classical Computing |
|---|---|---|
| Core Technology | DNA, proteins, living cells | Silicon-based semiconductors |
| Processing Speed | Variable; slow for large-scale tasks | High-speed electronic circuits |
| Data Storage | Massive density in DNA sequences | Magnetic, solid-state drives |
| Energy Efficiency | Extremely low power consumption | Significant power usage |
| Reliability | Prone to biological noise/errors | Highly reliable, error-corrected |
| Scalability | Potentially vast via molecular parallelism | Limited by hardware and heat dissipation |
| Applications | Medical diagnostics, synthetic biology | General computing, data processing |
| Development Stage | Experimental, emerging technology | Mature, established technology |
Introduction to Biological and Classical Computing
Biological computing leverages organic molecules such as DNA, proteins, and enzymes to perform computational tasks through biochemical reactions, offering massive parallelism and energy efficiency. Classical computing relies on silicon-based hardware and digital logic circuits, processing information in binary form through sequential or parallel algorithms. While classical computing excels in speed and precision for a wide range of applications, biological computing presents emerging opportunities for solving complex problems in bioinformatics, drug discovery, and synthetic biology.
Fundamental Principles of Biological Computing
Biological computing harnesses molecular and cellular processes such as DNA hybridization, enzymatic reactions, and neural signaling to perform computations, contrasting the binary logic and silicon-based hardware of classical computing. It leverages principles of parallelism, energy efficiency, and adaptability observed in natural systems like genetic networks and biochemical circuits. These fundamental mechanisms enable biological computing to process information in ways that traditional electronic computers cannot, offering novel solutions for complex data analysis and bioinformatics.
Core Concepts of Classical Computing
Classical computing operates on binary data represented by bits, utilizing transistors to process and store these bits through logical gates and circuits. Its core concepts include the use of deterministic algorithms, sequential instruction execution, and the von Neumann architecture, which separates memory and processing units. Classical computing excels in tasks requiring precise, reproducible results and well-defined computational steps.
Architecture Comparison: Biological vs Classical Systems
Biological computing relies on cellular and molecular structures such as neurons and DNA to perform parallel processing and adaptive learning, whereas classical computing uses silicon-based transistors arranged in a von Neumann architecture with a sequential processing model. The inherently parallel and distributed nature of biological systems enables fault tolerance and self-repair, contrasting with the deterministic and rigid hardware of classical computers. Energy efficiency in biological computing is significantly higher due to biochemical energy utilization, while classical systems depend on electrical power and face thermal management challenges.
Information Processing Mechanisms
Biological computing leverages molecular and cellular processes for information processing, utilizing DNA, proteins, and biochemical reactions to perform complex computations through parallelism and adaptability. Classical computing relies on electronic circuits and binary logic gates to process information sequentially or in parallel, following predefined algorithms and rigid architectures. The distinct mechanisms make biological computing inherently energy-efficient and capable of handling massive data with self-repair capabilities, whereas classical computing offers high-speed performance and precision in digital computations.
Energy Efficiency and Sustainability
Biological computing leverages organic molecules such as DNA and proteins to perform computations, significantly reducing energy consumption compared to classical silicon-based processors, which require substantial electrical power and cooling systems. The bio-inspired mechanisms inherently offer self-assembly and self-repair capabilities, enhancing sustainability by minimizing electronic waste and enabling renewable, biodegradable components. Energy efficiency in biological computing enables continuous, low-power operations, making it a promising alternative for eco-friendly technologies in contrast to the energy-intensive classical computing infrastructure.
Scalability and Adaptability
Biological computing leverages molecular components like DNA and proteins, offering high scalability through parallel processing capabilities inherent in biological systems, enabling complex problem-solving beyond classical computing limits. Classical computing, based on silicon-based transistors, faces scaling challenges due to physical and thermal constraints, limiting performance and miniaturization. Adaptability in biological computing arises from self-organization and evolutionary mechanisms, allowing dynamic responses to environmental changes, whereas classical computing relies on fixed hardware and predefined algorithms, restricting flexibility.
Real-World Applications and Use Cases
Biological computing leverages DNA, proteins, and cellular processes to perform complex computations, revolutionizing fields such as drug discovery, personalized medicine, and synthetic biology by enabling highly parallel and energy-efficient problem solving. Classical computing excels in general-purpose tasks like data processing, software applications, and machine learning, relying on silicon-based hardware for speed and reliability in industries like finance, engineering, and telecommunications. Real-world applications of biological computing include real-time biosensing and genomics analysis, while classical computing underpins large-scale simulations and cloud computing infrastructure.
Current Challenges and Limitations
Biological computing faces significant challenges with error rates, slower processing speeds, and limited scalability compared to classical computing, which benefits from well-established semiconductor technology and faster data processing capabilities. The complexity of reliably interfacing biological components with digital systems hinders widespread adoption and practical implementation of biological computing devices. Furthermore, classical computing systems continue to improve with advancements in quantum computing and AI integration, widening the performance gap against emerging biological computing technologies.
Future Prospects and Research Directions
Biological computing leverages DNA, proteins, and cellular mechanisms to perform complex computations, offering unprecedented parallelism and energy efficiency compared to classical silicon-based systems. Future prospects include the development of hybrid bio-electronic devices, scalable molecular circuits, and programmable living materials that could revolutionize data storage and processing. Research directions prioritize optimizing error correction in biochemical reactions, enhancing interfacing between biological components and electronic hardware, and exploring synthetic biology techniques to create customizable computing substrates.
Biological Computing Infographic