Label drift occurs when the relationship between input data and their corresponding labels changes over time, causing machine learning models to become less accurate. This issue is critical in dynamic environments where data evolves, leading to misclassifications if not properly addressed. Discover how to detect and mitigate label drift to maintain the reliability of Your AI solutions by reading the rest of this article.
Table of Comparison
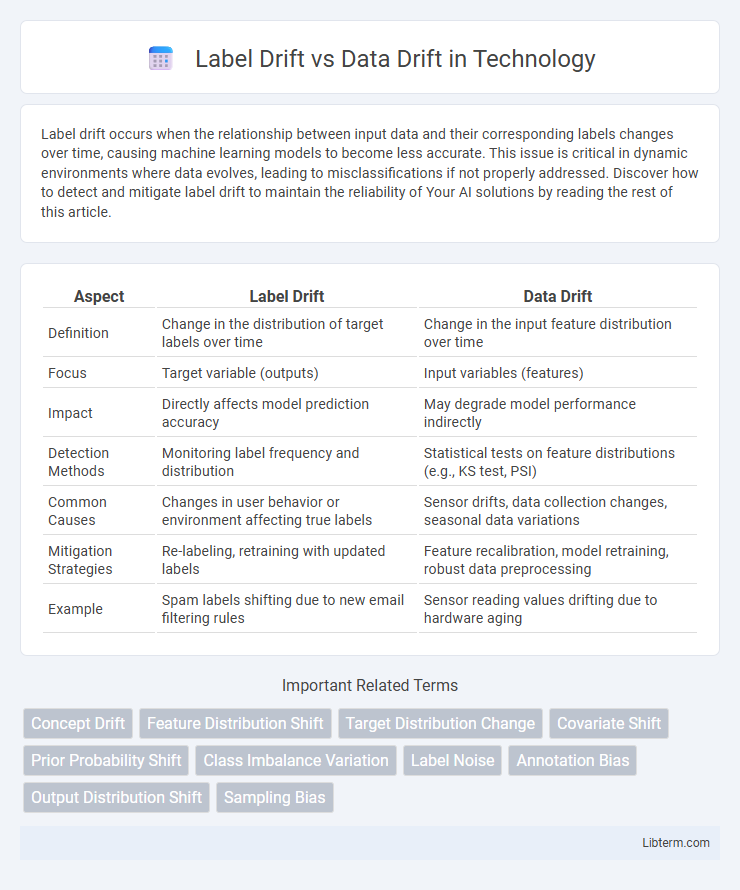
| Aspect | Label Drift | Data Drift |
|---|---|---|
| Definition | Change in the distribution of target labels over time | Change in the input feature distribution over time |
| Focus | Target variable (outputs) | Input variables (features) |
| Impact | Directly affects model prediction accuracy | May degrade model performance indirectly |
| Detection Methods | Monitoring label frequency and distribution | Statistical tests on feature distributions (e.g., KS test, PSI) |
| Common Causes | Changes in user behavior or environment affecting true labels | Sensor drifts, data collection changes, seasonal data variations |
| Mitigation Strategies | Re-labeling, retraining with updated labels | Feature recalibration, model retraining, robust data preprocessing |
| Example | Spam labels shifting due to new email filtering rules | Sensor reading values drifting due to hardware aging |
Introduction to Label Drift and Data Drift
Label drift occurs when the distribution of the target variable changes over time, impacting the accuracy of predictive models that rely on stable label distributions. Data drift refers to changes in the input feature distribution, which can degrade model performance by making historical training data less representative of current conditions. Understanding both label drift and data drift is crucial for maintaining the reliability and effectiveness of machine learning systems in dynamic environments.
Defining Data Drift: Causes and Examples
Data drift occurs when the statistical properties of input data change over time, leading to a mismatch between training and real-world data distributions. Common causes include seasonal trends, changes in user behavior, sensor malfunctions, or evolving external conditions affecting data patterns. For example, an e-commerce recommendation system may experience data drift during holiday seasons when shopping behaviors significantly differ from regular periods.
Understanding Label Drift in Machine Learning
Label Drift occurs when the distribution of labels in the training data changes over time, impacting model performance by altering the relationship between features and target variables. Unlike Data Drift, which involves shifts in feature distributions, Label Drift specifically affects the output variable, causing the predictive accuracy of classifiers to degrade if not detected and managed. Monitoring label distributions and recalibrating models regularly helps mitigate the risks associated with Label Drift in machine learning deployments.
Key Differences Between Data Drift and Label Drift
Data drift occurs when the statistical properties of input data change over time, affecting model performance by altering feature distributions without changing underlying relationships. Label drift involves shifts in the distribution of the target variable, typically caused by evolving real-world conditions or changes in class proportions. Key differences include that data drift impacts the input features, while label drift directly affects the outcome variable, requiring distinct detection and mitigation strategies.
Impact of Drift on Model Performance
Label drift occurs when the distribution of target labels changes over time, leading to increased model error rates and decreased predictive accuracy. Data drift involves shifts in input feature distributions, causing the model to misinterpret new patterns and resulting in reduced performance metrics such as precision and recall. Both types of drift degrade model reliability, necessitating regular monitoring and retraining to maintain optimal performance.
Detecting Data Drift: Tools and Techniques
Detecting data drift involves monitoring changes in feature distributions over time using statistical methods like the Kolmogorov-Smirnov test, population stability index (PSI), and Jensen-Shannon divergence. Tools such as Evidently AI, NannyML, and Fiddler provide automated pipelines for real-time drift detection, integrating seamlessly with machine learning workflows. Employing dimensionality reduction techniques and embedding-based comparisons enhances sensitivity to subtle shifts, ensuring robust model performance and timely retraining.
Identifying and Measuring Label Drift
Label drift occurs when the statistical distribution of target labels changes over time, impacting model accuracy despite stable input features. Identifying label drift involves monitoring shifts in the marginal distribution P(Y) using metrics such as Kullback-Leibler divergence or population stability index (PSI). Measuring label drift requires continuously comparing real-time label frequencies to historical baselines, enabling timely detection and adjustment of predictive models.
Strategies to Mitigate Data and Label Drift
Strategies to mitigate data drift include continuous monitoring of feature distributions and retraining models on recent data to maintain performance. For label drift, techniques such as updating ground truth labels through periodic human review and employing active learning help ensure label accuracy. Implementing automated alerts and adaptive algorithms further supports timely detection and correction of both data and label drift in machine learning systems.
Real-World Case Studies of Drift Issues
Label drift occurs when the relationship between input features and target labels changes over time, as seen in fraud detection where evolving fraud tactics alter the label distribution. Data drift refers to shifts in input feature distributions, exemplified by customer behavior changes in e-commerce platforms affecting model accuracy. Real-world case studies from industries like finance and healthcare highlight the critical need for continuous monitoring and adaptation to manage both label drift and data drift effectively.
Best Practices for Drift Monitoring and Management
Effective drift monitoring requires continuous evaluation of model inputs and outputs to detect both data drift, which affects feature distribution, and label drift, which impacts target variable distributions. Best practices include leveraging statistical tests such as Kolmogorov-Smirnov for data drift and monitoring performance metrics like accuracy or F1-score for label drift, alongside automated retraining triggers to maintain model robustness. Implementing a comprehensive drift management strategy involves integrating real-time data pipelines, establishing baseline distributions, and adopting adaptive models that adjust dynamically to evolving data patterns.
Label Drift Infographic