A continuous variable can take any value within a given range, representing measurements such as height, weight, or temperature. These variables are essential in statistical analysis and data science for modeling and interpreting complex real-world phenomena. Explore the rest of the article to understand how continuous variables impact your data-driven decisions.
Table of Comparison
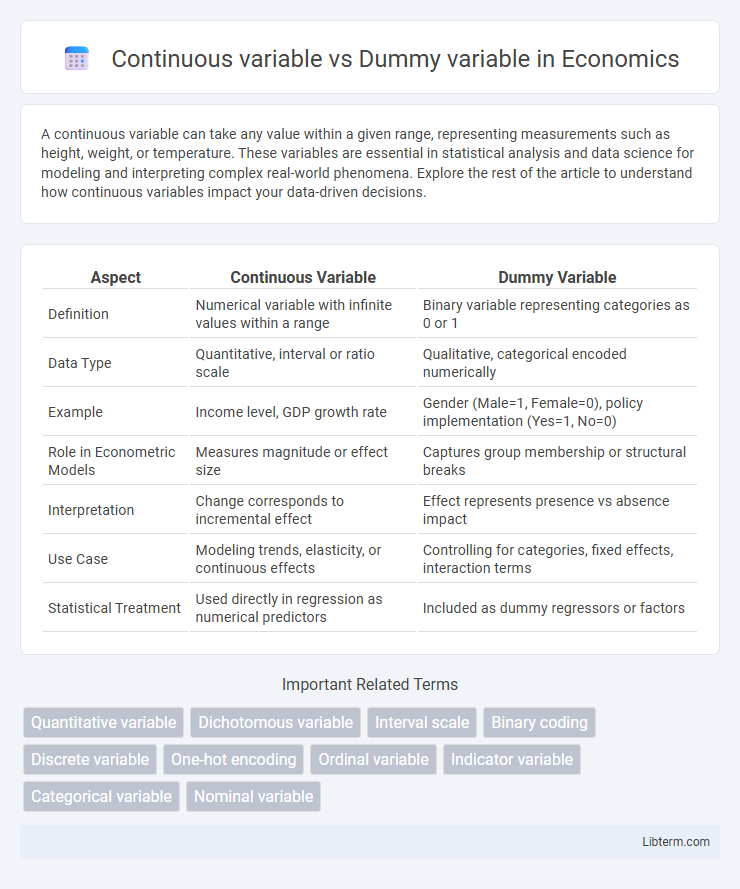
| Aspect | Continuous Variable | Dummy Variable |
|---|---|---|
| Definition | Numerical variable with infinite values within a range | Binary variable representing categories as 0 or 1 |
| Data Type | Quantitative, interval or ratio scale | Qualitative, categorical encoded numerically |
| Example | Income level, GDP growth rate | Gender (Male=1, Female=0), policy implementation (Yes=1, No=0) |
| Role in Econometric Models | Measures magnitude or effect size | Captures group membership or structural breaks |
| Interpretation | Change corresponds to incremental effect | Effect represents presence vs absence impact |
| Use Case | Modeling trends, elasticity, or continuous effects | Controlling for categories, fixed effects, interaction terms |
| Statistical Treatment | Used directly in regression as numerical predictors | Included as dummy regressors or factors |
Introduction to Continuous and Dummy Variables
Continuous variables represent data that can take any value within a range, such as height, weight, or temperature, allowing for precise measurements and detailed analysis. Dummy variables, also known as binary or indicator variables, categorize data into two distinct groups, typically coded as 0 or 1, to represent the presence or absence of a categorical attribute. Understanding the distinction between continuous and dummy variables is essential for applying appropriate statistical methods and improving model accuracy in data analysis.
Defining Continuous Variables
Continuous variables represent measurable quantities that can take any value within a given range, such as height, weight, or temperature. These variables are characterized by their ability to assume an infinite number of possible values, often measured on a scale with units like centimeters, kilograms, or degrees. Continuous data is critical for statistical analysis, enabling precise modeling and interpretation in fields like economics, biology, and engineering.
Understanding Dummy (Categorical) Variables
Dummy variables, also known as categorical variables, represent qualitative data by assigning binary values (0 or 1) to different categories, enabling their inclusion in regression models. Unlike continuous variables that assume infinite numerical values, dummy variables capture distinct groups or levels, facilitating the analysis of categorical effects on dependent variables. Proper encoding of dummy variables avoids multicollinearity issues and enhances model interpretability in statistical analyses.
Key Differences Between Continuous and Dummy Variables
Continuous variables represent numerical data that can take any value within a range, such as height or temperature, allowing for arithmetic operations and detailed analysis. Dummy variables, also known as binary or indicator variables, are categorical and take on only two values, typically 0 or 1, to represent the presence or absence of a qualitative attribute. The key difference lies in their data type and usage: continuous variables capture quantitative variations, while dummy variables convert categorical data into a format suitable for regression models and other statistical analyses.
Examples of Continuous Variables in Data Analysis
Continuous variables represent measurable quantities that can take any value within a range, such as height, temperature, or income. In data analysis, examples include body weight measured in kilograms, time recorded in seconds, and sales revenue expressed in dollars. These variables allow for detailed statistical computations like mean, variance, and regression analysis, enhancing model precision.
Examples of Dummy Variables in Statistical Models
Dummy variables in statistical models represent categorical data with binary indicators, often coded as 0 or 1 to signify the absence or presence of a specific category. Examples include gender (male = 1, female = 0), treatment groups in clinical trials (treatment = 1, control = 0), or regions in economic studies (region A = 1, region B = 0). These variables enable regression analysis to incorporate qualitative factors by transforming categorical attributes into numerical form for model estimation.
Importance of Variable Type Selection in Research
Selecting the appropriate variable type is crucial in research as continuous variables allow for precise measurement and statistical analysis, capturing a wide range of values and variance. Dummy variables, representing categorical data as binary indicators, enable inclusion of non-numeric factors in regression models and facilitate interpretation of group differences. Proper variable type selection impacts model accuracy, validity of statistical inferences, and the overall robustness of research findings.
How to Convert Continuous Variables to Dummy Variables
Transforming continuous variables into dummy variables involves creating binary indicators that represent specific ranges or categories within the continuous data. This can be achieved through binning, where the continuous variable is divided into intervals, and each interval is encoded as a separate dummy variable indicating presence or absence. Such conversion facilitates easier interpretation and use in models requiring categorical inputs, especially in regression or classification tasks.
Applications in Regression and Machine Learning
Continuous variables represent measurable quantities with an infinite range of values, making them essential for regression models that predict outcomes based on nuanced input data such as height, temperature, or income. Dummy variables, also known as indicator or binary variables, are used to encode categorical data into numerical form, allowing machine learning algorithms to handle qualitative factors like gender, region, or product type within regression frameworks. Effective use of continuous and dummy variables enhances model accuracy by capturing both quantitative variance and categorical distinctions critical for prediction tasks in supervised learning.
Best Practices for Handling Variable Types
Continuous variables should be standardized or normalized to improve model performance and ensure comparability, especially in algorithms sensitive to scale like gradient descent. Dummy variables, created through one-hot encoding for categorical data, must avoid the dummy variable trap by excluding one category to maintain model interpretability and prevent multicollinearity. Proper handling of these variable types enhances predictive accuracy and reduces bias in statistical models and machine learning pipelines.
Continuous variable Infographic